모두의 코드
씹어먹는 C 언어 - <20 - 2. 메모리 동적할당 + 메모리 갖고 놀기>
이번 강좌에서는
구조체의 동적 할당
노드의 이용
메모리 관리 함수(memmove, memcpy, memcmp) 함수의 사용

안녕하세요 여러분. 메모리에 관해서 두 번째 이야기를 풀어 나가려고 합니다. 원래 메모리 동적 할당은 강의 한 개로 끝내려고 했는데 코이치 님이 무언가 조금 모자라다는 듯한 느낌이 든다고 하셔서 두 개의 강의로 이어 나가려고 합니다. 물론 동적 할당에 관한 기본 개념은 지난 강좌에서 모두 다루었지만 조금 보충 설명과 함께 새로운 것들을 이야기 하고자 합니다.
구조체 동적 할당
#include <stdio.h> #include <stdlib.h> struct Something { int a, b; }; int main() { struct Something *arr; int size, i; printf("원하시는 구조체 배열의 크기 : "); scanf("%d", &size); arr = (struct Something *)malloc(sizeof(struct Something) * size); for (i = 0; i < size; i++) { printf("arr[%d].a : ", i); scanf("%d", &arr[i].a); printf("arr[%d].b : ", i); scanf("%d", &arr[i].b); } for (i = 0; i < size; i++) { printf("arr[%d].a : %d , arr[%d].b : %d \n", i, arr[i].a, i, arr[i].b); } free(arr); return 0; }
성공적으로 컴파일 했다면
실행 결과
원하시는 구조체 배열의 크기 : 2 arr[0].a : 1 arr[0].b : 2 arr[1].a : 3 arr[1].b : 4 arr[0].a : 1 , arr[0].b : 2 arr[1].a : 3 , arr[1].b : 4
와 같이 나옵니다.
저의 구조체 강좌를 여태까지 잘 보신 분들은 잘 아시겠지만 구조체 역시 특별하게 생각해야 될 것이 아니라 '사용자가 만든 하나의 데이터 타입' 이라고 보시면 된다고 했습니다. 다시 말해 구조체도 int 처럼 사용할 수 있다는 것이지요. 따라서 구조체 배열을 malloc 을 이용하여 지지고 볶는 일은 전혀 이상할 것이 없는 행동 입니다.
struct Something *arr;
일단 1 차원 구조체 배열을 가리키기 위한 arr 을 선언하였습니다. int 형 배열을 만들기 위해 int *arr; 이라 했던 것과 정확히 일치 합니다.
arr = (struct Something *)malloc(sizeof(struct Something) * size);
이제 malloc 함수를 이용하여 arr 을 위한 공간을 할당해줍니다. 이에 필요한 크기는 당연히도 sizeof(struct Something) * size 입니다. 만일 sizeof 대신에 구조체의 실제 크기를 계산해서 더하시는 분이 있는데 이는 오류를 발생 시킬 수 있습니다. 예를 들어 위 Somehting 구조체의 경우 1 개당 8 바이트를 차지한다고 볼 수 있는데 사실 그렇지 않을 수 도 있습니다.
물론 위 경우는 조금 특별하지만 예를 들어 구조체의 크기가 10 바이트일 경우 컴퓨터가 더블워드 경계(double word boundary) 에 놓음으로 속도를 향상시키는 경우가 있는데 이 경우 구조체의 크기는 12 바이트로 간주될 수 있습니다. 사실 자세한 내용은 여기서 생략하기로 하고 아무튼 기역해야 할 점은 언제나 sizeof 를 사용해야 한다는 점입니다. 무턱대고 크기를 추정하지 맙시다!
for (i = 0; i < size; i++) { printf("arr[%d].a : ", i); scanf("%d", &arr[i].a); printf("arr[%d].b : ", i); scanf("%d", &arr[i].b); }
이렇게 할당을 하고 나면 입력을 받아야 겠지요? 위와 같은 for 문을 열심히 돌려서 입력을 받으면 됩니다.
free(arr);
그리고 마지막에 위와 같이 free 로 깔끔하게 메모리를 정리해주는 것도 잊으면 안됩니다!
노드
여태까지 여러분들은 여러가지 자료형들을 배워왔습니다. 변수를 무식하게 나열하는 것을 막기 위해 배열을 이용하였고, 또 배열의 기능에 한계를 느낀 여러분은 구조체를 만들었습니다. 그리고 구조체 하나에 한 개 한 개를 다루는데 한계를 느낀 여러분은 구조체 배열을 이용해왔구요. 결국 배열로 다시 돌아왔습니다. 동적 할당을 함으로써 사용자가 원하는 크기의 입력을 다룰 수 있게 되었다고 하더라도 아직 많은 문제를 느끼고 있습니다. 만일 사용자가 마음이 변해서 한 개의 입력을 더 받고 싶다면 말이죠. 새롭게 동적할당을 하면 되지만 예컨대 1000 개 의 데이터가 있는데 1 개의 추가적인 데이터를 위해 1001 개를 위한 공간을 새로 잡으면 너무 아까운 것 같습니다.
이를 해결하는 것이 바로 '노드' 입니다. 노드는 이렇게 생겼습니다.
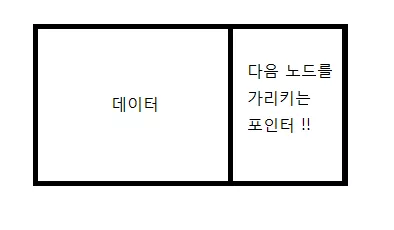
상당히 단순하지요? 이를 C 코드로 나타내면 다음과 같습니다.
struct Node { int data; /* 데이터 */ struct Node* nextNode; /* 다음 노드를 가리키는 부분 */ };
아무튼 이렇게 생긴 노드를 어떻게 사용할까요?
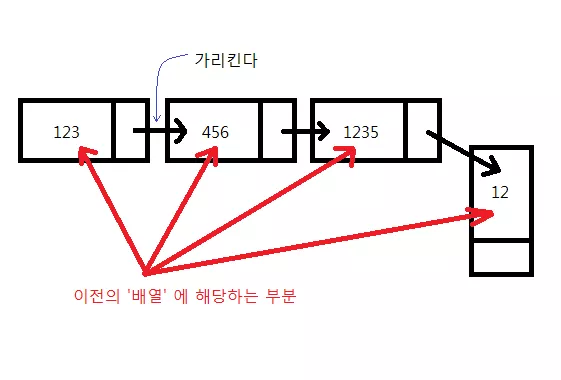
뿐만 아닙니다. 기존의 배열에서는 거의 불가능 하였던 작업인 '배열 중간에 새 원소 집어넣기' 가 가능해집니다. 다시 말해 노드 사이에 새로운 노드를 끼워 넣을 수 있게 된다는 것이지요.
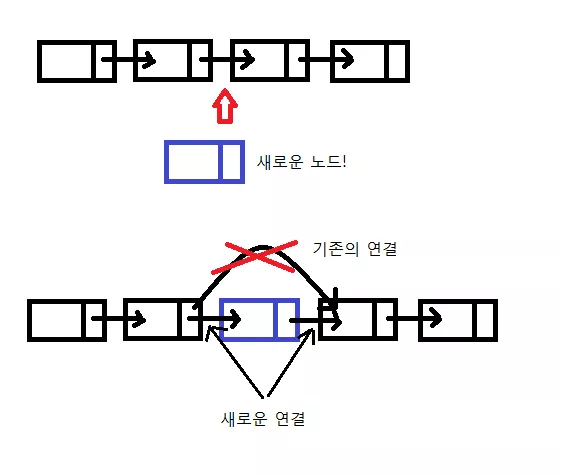
CreateNode 함수 부터 만들어봅시다. 이 함수는 노드를 생성하기만 합니다. 노드를 생성하기 위해서는 데이터와 이 노드가 가리키는 다음 노드가 필요한데 이 함수는 단순히 첫번째 노드를 만드는 역할을 한다고 하고 nextNode 를 NULL 로 줍시다./* 새 노드를 만드는 함수 */ struct Node* CreateNode(int data) { struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); newNode->data = data; newNode->nextNode = NULL; return newNode; }
따라서 CreateNode 함수는 위와 같이 만들 수 있습니다. 일단 malloc 을 통해 노드를 메모리에 할당하였고 이 할당된 노드는 newNode 가 가리키게 됩니다. 이제, newNode->data 에 data 를 집어넣고 이 노드가 가리키는 다음 노드를 NULL 로 주면 됩니다.
사실 이 함수는 노드를 생성하기만 할 뿐 노드를 어떻게 관계짓지는 못합니다. 따라서 어떠한 노드 뒤에 새로운 노드를 생성하는 함수를 만들어야 할 것입니다. 이 함수는 InsertNode 함수라고 합시다. 따라서 어떠한 노드뒤에 올지 '앞에 있는 노드' 에 관한 정보와 '새로운 노드를 위한 데이터' 가 필요하므로 struct Node *current, int data 를 인자로 가져야 합니다.
/* current 라는 노드 뒤에 노드를 새로 만들어 넣는 함수 */ struct Node* InsertNode(struct Node* current, int data) { /* current 노드가 가리키고 있던 다음 노드가 after 이다 */ struct Node* after = current->nextNode; /* 새로운 노드를 생성한다 */ struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); /* 새 노드에 값을 넣어준다. */ newNode->data = data; newNode->nextNode = after; /* current 는 이제 newNode 를 가리키게 된다 */ current->nextNode = newNode; return newNode; }
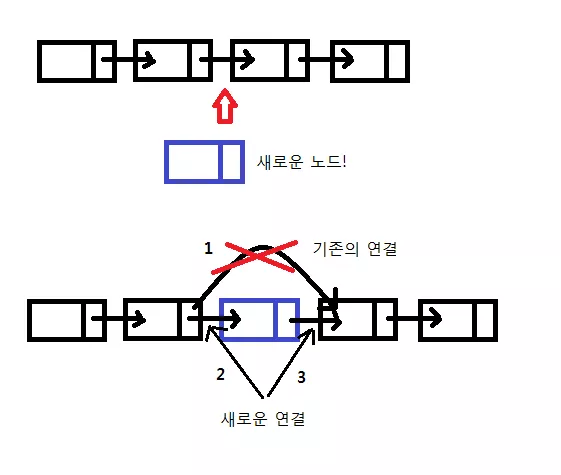
위 함수에 대한 설명을 위 그림을 보면서 해봅시다.
/* 새로운 노드를 생성한다 */ struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
일단 위 문장을 통해 새로운 노드 newNode 를 생성하였습니다.
/* 새 노드에 값을 넣어준다. */ newNode->data = data; newNode->nextNode = after;
이제 위 과정을 통해 newNode 에 nextNode 를 넣어주는 과정인데요, 이는 위 그림에서 3 번에 해당하는 과정입니다.
/* current 는 이제 newNode 를 가리키게 된다 */ current->nextNode = newNode;
또한 newNode 앞에 있던 노드의 nextNode 가 바뀌었으므로 새롭게 수정하는 과정이 위 코드인데 이는 위 그림에서 1,2 번에 해당하는 과정입니다. 이렇듯, 그림에 있던 과정들이 함수에 잘 구현이 되어 있음을 알 수 있습니다.
이렇게 노드를 잘 만들어주었다면 노드를 파괴하는 역할을 가지는 함수 역시 만들어야 합니다. 이를 위해서는 이 노드를 가리키고 있던 이전 노드가 필요하게 됩니다. 그런데 이 노드를 가리키고 있던 노드를 찾기 위해서는 맨 처음 부터 뒤져나가야 하는데, 맨 처음 노트를 헤드 라고 하며 우리의 DestoryNode 함수는 헤드를 인자로 받아야 합니다. 물론 파괴하고자 하는 노드도 인자로 받아야 하지요
/* 선택된 노드를 파괴하는 함수 */ void DestroyNode(struct Node *destroy, struct Node *head) { /* 다음 노드를 가리킬 포인터*/ struct Node *next = head; /* head 를 파괴하려 한다면 */ if (destroy == head) { free(destroy); return; } /* 만일 next 가 NULL 이면 종료 */ while (next) { /* 만일 next 다음 노드가 destroy 라면 next 가 destory 앞 노드*/ if (next->nextNode == destroy) { /* 따라서 next 의 다음 노드는 destory 가 아니라 destroy 의 다음 노드가 * 된다. */ next->nextNode = destroy->nextNode; } /* next 는 다음 노드를 가리킨다. */ next = next->nextNode; } free(destroy); }
위와 같이 만들면 됩니다. head 노드로 부터 차례 차례 하나 씩 다음 노드와 비교해가면서 찾아나가는 모습입니다. 이 과정은
while (next) { /* 만일 next 다음 노드가 destroy 라면 next 가 destory 앞 노드*/ if (next->nextNode == destroy) { /* 따라서 next 의 다음 노드는 destory 가 아니라 destroy 의 다음 노드가 된다. */ next->nextNode = destroy->nextNode; } /* next 는 다음 노드를 가리킨다. */ next = next->nextNode; }
에 잘 나타나 있습니다. 만일 next->nextNode == destroy 라면 next 의 다음 노드가 바로 destroy 가 되는 것이므로 거꾸로 생각해보면 destroy 를 가리키고 있었던 이전 노드는 next 가 됩니다. 이 때 destroy 는 메모리에서 파괴되어 사라지기 때문에 next 의 nextNode 가 destroy 가 되면 안되고 그 다음 다음 노드, 즉 destory 의 nextNode 가 되어야 한다는 것입니다. 따라서 위와 같은 과정을 수행하고침내 마지막에 free 를 해주면 됩니다.
이 과정을 한 소스에 정리하면
#include <stdio.h> #include <stdlib.h> struct Node* InsertNode(struct Node* current, int data); void DestroyNode(struct Node* destroy, struct Node* head); struct Node* CreateNode(int data); void PrintNodeFrom(struct Node* from); struct Node { int data; /* 데이터 */ struct Node* nextNode; /* 다음 노드를 가리키는 부분 */ }; int main() { struct Node* Node1 = CreateNode(100); struct Node* Node2 = InsertNode(Node1, 200); struct Node* Node3 = InsertNode(Node2, 300); /* Node 2 뒤에 Node4 넣기 */ struct Node* Node4 = InsertNode(Node2, 400); PrintNodeFrom(Node1); return 0; } void PrintNodeFrom(struct Node* from) { /* from 이 NULL 일 때 까지, 즉 끝 부분에 도달할 때 까지 출력 */ while (from) { printf("노드의 데이터 : %d \n", from->data); from = from->nextNode; } } /* current 라는 노드 뒤에 노드를 새로 만들어 넣는 함수 */ struct Node* InsertNode(struct Node* current, int data) { /* current 노드가 가리키고 있던 다음 노드가 after 이다 */ struct Node* after = current->nextNode; /* 새로운 노드를 생성한다 */ struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); /* 새 노드에 값을 넣어준다. */ newNode->data = data; newNode->nextNode = after; /* current 는 이제 newNode 를 가리키게 된다 */ current->nextNode = newNode; return newNode; } /* 선택된 노드를 파괴하는 함수 */ void DestroyNode(struct Node* destroy, struct Node* head) { /* 다음 노드를 가리킬 포인터*/ struct Node* next = head; /* head 를 파괴하려 한다면 */ if (destroy == head) { free(destroy); return; } /* 만일 next 가 NULL 이면 종료 */ while (next) { /* 만일 next 다음 노드가 destroy 라면 next 가 destory 앞 노드*/ if (next->nextNode == destroy) { /* 따라서 next 의 다음 노드는 destory 가 아니라 destroy 의 다음 노드가 된다. */ next->nextNode = destroy->nextNode; } /* next 는 다음 노드를 가리킨다. */ next = next->nextNode; } free(destroy); } /* 새 노드를 만드는 함수 */ struct Node* CreateNode(int data) { struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); newNode->data = data; newNode->nextNode = NULL; return newNode; }
성공적으로 컴파일 하였다면
실행 결과
노드의 데이터 : 100 노드의 데이터 : 200 노드의 데이터 : 400 노드의 데이터 : 300
와 같이 잘 나옵니다.
void PrintNodeFrom(struct Node *from) { /* from 이 NULL 일 때 까지, 즉 끝 부분에 도달할 때 까지 출력 */ while (from) { printf("노드의 데이터 : %d \n", from->data); from = from->nextNode; } }
일단 추가적으로 위와 같이 from 이후의 모든 노드의 값을 출력하는 함수인 PrintNodeFrom 이라는 함수를 정의하였습니다.
struct Node* Node1 = CreateNode(100); struct Node* Node2 = InsertNode(Node1, 200); struct Node* Node3 = InsertNode(Node2, 300); /* Node 2 뒤에 Node4 넣기 */ struct Node* Node4 = InsertNode(Node2, 400);
메인 함수에서 위와 같이 Node 들을 정의하였습니다. 먼저 헤드 노드인 Node1 을 CreateNode 함수를 통해 정의하였고, Node1 뒤에 Node2 , Node2 뒤에 Node3, 그리고 Node2 뒤에 Node4 를 끼워넣었습니다. 그리고 실행한 결과 100, 200, 400, 300 순으로 제대로 나온 것을 볼 수 있습니다.
이렇게 노드는 배열과는 달리 추가/삭제/삽입이 월등히 편리합니다. 그렇다고 해서 노드가 배열 보다 월등한 것일까요? 꼭 그렇다고는 말할 수 없습니다. 왜냐하면 배열의 경우 3 번째 원소에 접근하기 위해서는 단순히 arr[3] 으로 하면 되지만 노드의 경우 헤드로 부터 3 번째 까지 일일히 찾아가야만 하기 때문이죠. 따라서 N 개의 노드가 있다면 최악의 경우 N 번동안 계속 찾아야 하지만 배열의 경우 특정한 상수 시간 내에 찾아갈 수 있기 때문에 이부분에서는 배열이 월등히 좋다고 할 수 있습니다. 또한 노드의 경우 데이터를 위한 공간 말고도 다음 노드를 가리키기 위한 4 바이트가 더 필요하기 때문에 공간적으로도 약간 손해를 본다고 생각할 수 있습니다.
따라서 결론적으로 이야기 하자면 추가/삭제/삽입이 자주 일어나는 경우 노드를 사용하고 특정한 번째에 찾아가야 하는 일이 잦은 일은 배열을 사용하는 것이 이롭다는 것을 알 수 있습니다.
사실 노드 말고도 여러가지 형태의 자료 구조들이 있는데 예를 들면 스택, 큐, 트리 등이 있다고 볼 수 있습니다. 이들에 관한 자세한 내용은 여러분 스스로 찾아 보시기 바랍니다.
메모리 관련 함수
이번 단원이 메모리에 관한 것인 만큼 메모리에 관해서는 빠삭하게 알아가도록 합시다. 이를 위해 메모리에 관련된 C 표준 라이브러리에서 기본으로 지원되는 것들에 대해 알아보도록 합시다. 일단 메모리를 직접적으로 가지고 논다고 말할 수 있는 함수들은 memmove, memcpy, memcmp, memset 등이 있는데 우리는 여기서 대표적인 3 개의 함수인 memmove, memcpy, memcmp 만 알아보도록 합시다. 이 함수들 모두 string.h 에 정의되어 있습니다.
먼저 memcpy 함수 부터 봅시다.
/* memcpy 함수 */ #include <stdio.h> #include <string.h> int main() { char str[50] = "I love Chewing C hahaha"; char str2[50]; char str3[50]; memcpy(str2, str, strlen(str) + 1); memcpy(str3, "hello", 6); printf("%s \n", str); printf("%s \n", str2); printf("%s \n", str3); return 0; }
성공적으로 컴파일 하였다면
실행 결과
I love Chewing C hahaha I love Chewing C hahaha hello
와 같이 나옵니다.
memcpy 함수는 메모리의 특정한 부분으로 부터 얼마 까지의 부분을 다른 메모리 영역으로 복사해주는 함수 입니다. 위와 같이 문자열을 복사하는데 사용될 수 있죠. 물론 문자열 복사를 전문적으로 하는 함수는 strcpy 이지만 위와 같이 memcpy 함수를 사용하는 것도 나쁘지 않습니다.
memcpy(str2, str, strlen(str) + 1);
일단 위 문장은 'str 로 부터 strlen(str) + 1 만큼의 문자를 str2 로 복사해라' 라는 의미 입니다. 이 때, strlen 함수는 문자열의 길이를 리턴해주는 함수로 예를 들어 strlen("abc"); 를 하면 3 이 리턴됩니다. 이 때 마지막의 NULL 문자는 세지 않으므로 str2 에 memcpy 로 복사할 때 에는 1 을 더한만큼을 더 복사해주어야 합니다.
memcpy(str3, "hello", 6)
마찬가지로 str3 의 경우도 hello 의 5 문자와 끝에 NULL 을 위해 총 6 문자를 hello 의 시작 주소로 부터 복사를 하게 됩니다. memcpy 에 관한 자세한 내용은 여기 을 참조하시기 바랍니다.
다음으로 memmove 함수에 대해 살펴봅시다. 이 함수는 메모리의 특정한 부분의 내용을 다른 부분으로 옮겨주는 역할을 합니다. 이 때 '옮긴다' 고 해서 이전 공간에 있던 데이터가 사라지지는 않습니다.
/* memmove 함수 */ #include <stdio.h> #include <string.h> int main() { char str[50] = "I love Chewing C hahaha"; printf("%s \n", str); printf("memmove 이후 \n"); memmove(str + 23, str + 17, 6); printf("%s", str); return 0; }
성공적으로 컴파일 하였다면
실행 결과
I love Chewing C hahaha memmove 이후 I love Chewing C hahahahahaha
와 같이 나옵니다.
char str[50] = "I love Chewing C hahaha"; memmove(str + 23, str + 17, 6);
memmove 함수는 위 경우 str+17 에서 6 개의 문자를 str+23 에 옮겼습니다. 다시 말해 hahaha 의 시작 부분에서 6 개의 문자인 "hahaha" 를 str 의 맨 마지막 부분으로 복사해 넣었다는 뜻입니다. 다시 말해 str 뒤에 "hahaha" 를 추가하게 된 셈이지요. 이를 통해 문자열을 I love Chewing C hahahahahaha 로 만들 수 있게 되었습니다. memmove 함수의 장점은 memcpy 와 하는 일이 많이 비슷해보이지만 사실 memcpy 와는 달리 메모리 공간이 겹쳐도 됩니다. 위 경우도 str 과 복사하는 부분이 겹쳤지만 성공적으로 복사가 수행되었습니다. 덕분에 나중에는 memmove 함수를 아주 많이 사용하게 될 것입니다.
마지막으로 memcmp 함수를 살펴보도록 합시다. 이는 이름에서도 충분히 짐작이 되듯이 두 개의 메모리 공간을 서로 비교하는 함수 입니다.
/* memcmp 함수 */ #include <stdio.h> #include <string.h> int main() { int arr[10] = {1, 2, 3, 4, 5}; int arr2[10] = {1, 2, 3, 4, 5}; if (memcmp(arr, arr2, 5) == 0) printf("arr 과 arr2 는 일치! \n"); else printf("arr 과 arr2 는 일치 안함 \n"); return 0; }
성공적으로 컴파일 하였다면
실행 결과
arr 과 arr2 는 일치!
와 같이 나옵니다.
memcmp 함수는 꽤 유용하게 사용될 수 있습니다. 이 함수는 메모리의 두 부분을 원하는 만큼 비교를 합니다. 이 때 같다면 0, 다르다면 결과에 따라 0 이 아닌 값을 리턴하게 되지요.
if (memcmp(arr, arr2, 5) == 0)
위 문장의 경우 arr 과 arr2 를 비교해서 처음 5 개의 바이트가 같다면 0 을 리턴하게 됩니다. 주의해야 할 점은 '5 개의 원소' 가 아니라 5 바이트 라는 점 이지요. 만일 arr1 과 arr2 전체를 비교하고 싶다면 3 번째 인자로 sizeof(int) * 5 를 넣어 주어야 했었을 것입니다.
이렇게 메모리를 가지고 노는 3 개의 함수들을 모두 살펴보았습니다. 저는 이 함수를 사용하는 아주 기본적인 방법만을 가르쳐 주었을 뿐 이 함수들을 어떻게 응용시켜서 적용시키냐는 여러분들의 몫입니다. 이제, 메모리를 아주 빠삭하게 다룰 수 있기 되었으니 (동적 메모리 할당도 할 줄 알고, memmove 와 같은 놀라운 메모리 관련 함수들도 사용할 줄 아니..) 이번 강좌는 여기서 끝마치도록 하겠습니다.
생각 해보기
앞서 배운 노드는 여러모로 생각해볼 점이 많다. 다음의 과제들을 차례대로 해결해보기 바랍니다.
문제 1
head 가 주어질 때 전체 노드의 개수를 세는 int CountNode(Node* head) 함수를 작성하시오 (난이도 : 下)
문제 2
head 와 원하는 노드가 주어질 때 특정 data 를 가지는 노드가 존재하는지 확인하는 bool HasNode(Node* head) 함수를 작성하세요.
문제 3
앞서 구현하였던 Node 의 단점으로 '이 노드를 가리키는 노드' 를 쉽게 알 수 없다는 점이다. 이를 보완하기 위해
struct Node { int data; /* 데이터 */ struct Node* nextNode; /* 다음 노드를 가리키는 부분 */ struct Node* prevNode; /* 이전 노드를 가리키는 부분 */ };
형식으로 노드를 만들어보고 앞서 작성했던 모든 함수들을 다시 작성해보시오 (난이도 : 中)
문제 4
위와 같은 형식의 노드를 개량하여 head 가 맨 마지막 노드인 tail 을 prevNode 로 가리키는 원형의 노드를 만들어보시오. 다시 말해 노드의 처음과 끝이 없다고 볼 수 있다. 이러한 형태의 노드를 이용하여 앞서 구현하였던 모든 함수를 구현해보시오 (난이도 : 中上)
문제 5
이전 강좌에서 만들었던 도서 관리 프로그램을 동적 할당과 구조체를 이용하여 만들어보세요 (난이도 : 中)

댓글을 불러오는 중입니다..