모두의 코드
C 언어 레퍼런스 - strstr 함수
아직 C 언어와 친숙하지 않다면, 씹어먹는 C 언어 강좌를 보는 것이 어떻까요?
strstr
#include <string.h> // C++ 에서는 <cstring> const char* strstr(const char* str1, const char* str2); char* strstr(char* str1, const char* str2);
문자열을 검색한다.
str1 에서 str2 를 검색하여 가장 먼저 나타나는 곳의 위치를 리턴한다. 이 때 일치하는 문자열이 없다면 널 포인터를 리턴하게 된다. 검색에서 마지막 널 문자는 포함하지 않는다.
인자
str1
검색이 수행되는 C 형식 문자열
str2
찾을 C 형식 문자열
리턴값
str1 에서 str2 를 찾았다면 가장 먼저 나오는 곳의 위치를 리턴한다. 만일 str2 가 str1 에 존재하지 않는다면 널을 리턴한다.
구현 예
/*이 소스는 http://www.jbox.dk/sanos/source/lib/string.c.html에서 가져왔습니다*/ char *strstr(const char *str1, const char *str2) { char *cp = (char *)str1; char *s1, *s2; if (!*str2) return (char *)str1; while (*cp) { s1 = cp; s2 = (char *)str2; while (*s1 && *s2 && !(*s1 - *s2)) s1++, s2++; if (!*s2) return cp; cp++; } return NULL; }
문자열 검색에 관련된 알고리즘
통상적으로 구현된 strstr 함수는 위에서 사용된 코드 처럼 단순하게도 각 문자열을 일일히 검색하는 방식을 취하고 있다. 이는 짧은 문자열을 검색하는데 에는 요긴하게 사용될 수 있지만 문자열의 길이가 길어진다면, 예를 들어 수십장 짜리 문서에서 특정 단어를 찾을 때 에는 적합하지 않은 방식이라 할 수 있다.
이를 위해 여러가지 문자열 검색 알고리즘이 있는데 대표적으로 사용되는 것이 보이어 무어(Boyer-Moore) 알고리즘 이다. (이는 현재 대부분의 워드 프로세서에서 '찾기' 기능에 사용되고 있다) 그 외에도 카프- 라빈(Karp-Rabin) 검색 알고리즘, 크누스 - 모리스 - 프랫(Knuth - Morris - Pratt, KMP) 알고리즘 등이 있지만 여기서는 보이어 무어 알고리즘만 소개한다.
보이어 무어(Boyer - Moore) 알고리즘은 크게 두 가지 종류의 이동으로 구성되어 있는데 하나는 착한 접미부 이동(Good Suffix Shift) 와 다른 하나는 나쁜 문자 이동(Bad Character Shift) 이다. 가장 먼저 착한 접미부 이동이 무엇인지 보자
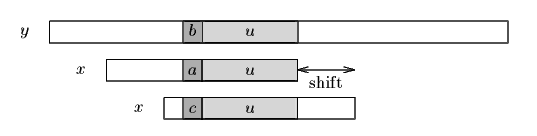
위와 같이 y 라는 문자열에서 x 라는 문자열을 찾는다고 하자. 보이어 무어 알고리즘의 특징은, 문자열의 이동 자체는 왼쪽에서 오른쪽으로 쭉 가면서 찾지만 정작 문자열의 비교는 오른쪽에서 왼쪽으로 한다. 따라서 만일 특정 위치에서 x 와 y 를 비교하는데, 오른쪽의 u 만큼의 부분이 일치되었다고 하자 (위 그림에서 u 라고 표시된 부분, 이 부분을 가리켜 '착한 접미부(Good Suffix)' 라고 부른다)
그리고 왼쪽의 'b' 와 'a' 가 일치하지 않은 부분이라고 하자. 이렇게 된다면 보이어 무어 알고리즘에서는 x 를 문자열 x 의 또다른 착한 접미부가 나오는 곳과 기존의 착한 접미부가 있던 곳으로 오게 오른쪽으로 쉬프트를 하게 된다. 위 그림에서 보듯이 기존에 u 가 위치했던 곳에 x 의 또다른 u 가 일치되었음을 볼 수 있다. 예를 들어 아래의 그림을 보면 단박에 이해가 된다.
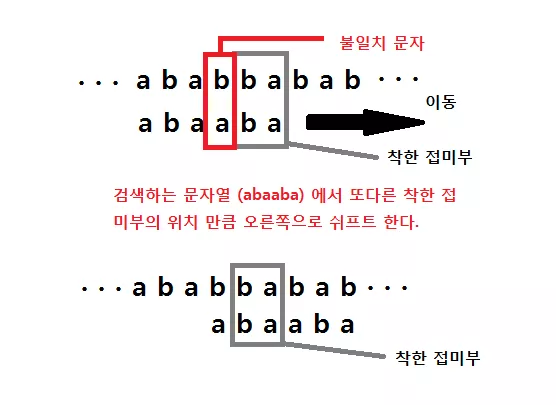
위와 같이 또다른 접미부에 도달하게 문자열을 이동시키는 것이다. 그리고는 다시 이동 시킨 문자열의 맨 오른쪽으로 부터 검사를 수행한다. 그런데, 만일 문자열에 또다른 착한 접미부가 없다면 어떻게 될까.
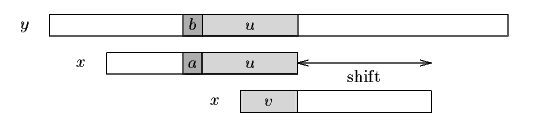
그렇게 된다면 일치하는 착한 접미부에서 x 에 들어있는 가장 긴 접미부를 찾게 된다. 위 그림에서는 v 가 착한 접미부 u 중 x 에 들어있는 가장 긴 접미부가 된다. 그리고 v 가 일치되게 오른쪽으로 쉬프트를 하게 된다. 이 과정을 예를 들어 보면
와 같이 나타난다.
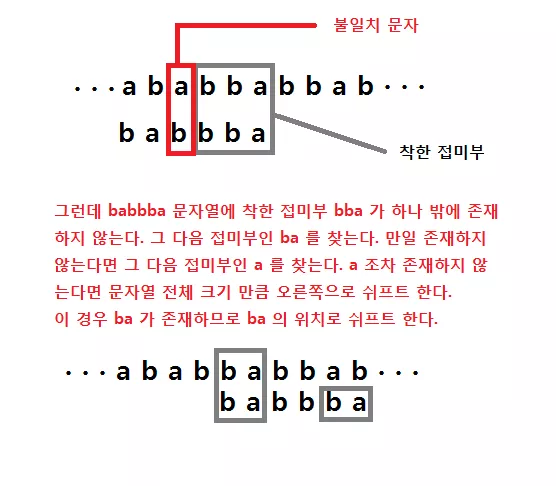
그런데 만일 착한 접미부가 나타나지 않는다면 어떻게 될까. 예를 들면 아래와 같은 상황이다.
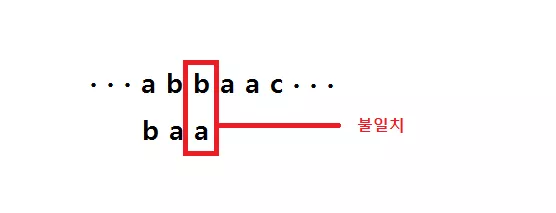
이렇게 처음 부터 불일치 되는 문자를 '나쁜 문자' 라 부르며 여기서 검색하는 문자열의 문자가 해당된다. 즉, 위 경우 나쁜 문자는 'b' 가 된다. 이렇게 나쁜 문자가 오는 경우는 검색하는 문자열에서 가장 오른쪽에 나타나는 나쁜 문자를 찾아서 그 위치로 이동 시켜 주면 된다. 즉, 아래 처럼 된다.
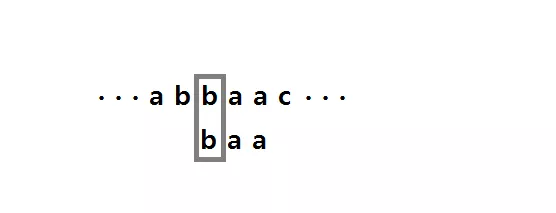
만일 나쁜 문자가 포함되어 있지 않는다면 그 문자열 전체 길이 만큼 오른쪽으로 쉬프트 해주면 된다.
위와 같이 보이어 무어 알고리즘은 두 개의 쉬프트로 구성되어 있는데, 각 쉬프트를 빠르게 처리하기 위해 테이블을 만든다. 테이블을 만드는 과정은 간단하므로 생략하도록 한다. (테이블을 만드는 방법을 보시려면 http://xenostudy.tistory.com/72로 들어가보시기 바랍니다)
이를 바탕으로 코드를 짜보면 아래와 같이 된다.
/* 참고로 다음 코드는 http://en.wikipedia.org/wiki/Boyer%E2%80%93Moore_string_search_algorithm 에서 가져왔습니다. 테이블을 생성하는 함수는 나쁜 문자 이동의 경우 static void prepare_badcharacter_heuristic, 착한 접미부 이동의 경우 void prepare_goodsuffix_heuristic 이다. */ #include <limits.h> #include <string.h> #define ALPHABET_SIZE (1 << CHAR_BIT) static void compute_prefix(const char *str, size_t size, int result[size]) { size_t q; int k; result[0] = 0; k = 0; for (q = 1; q < size; q++) { while (k > 0 && str[k] != str[q]) k = result[k - 1]; if (str[k] == str[q]) k++; result[q] = k; } } static void prepare_badcharacter_heuristic(const char *str, size_t size, int result[ALPHABET_SIZE]) { size_t i; for (i = 0; i < ALPHABET_SIZE; i++) result[i] = -1; for (i = 0; i < size; i++) result[(size_t)str[i]] = i; } void prepare_goodsuffix_heuristic(const char *normal, size_t size, int result[size + 1]) { char *left = (char *)normal; char *right = left + size; char reversed[size + 1]; char *tmp = reversed + size; size_t i; /* reverse string */ *tmp = 0; while (left < right) *(--tmp) = *(left++); int prefix_normal[size]; int prefix_reversed[size]; compute_prefix(normal, size, prefix_normal); compute_prefix(reversed, size, prefix_reversed); for (i = 0; i <= size; i++) { result[i] = size - prefix_normal[size - 1]; } for (i = 0; i < size; i++) { const int j = size - prefix_reversed[i]; const int k = i - prefix_reversed[i] + 1; if (result[j] > k) result[j] = k; } } /* * Boyer-Moore search algorithm */ const char *boyermoore_search(const char *haystack, const char *needle) { /* * Calc string sizes */ size_t needle_len, haystack_len; needle_len = strlen(needle); haystack_len = strlen(haystack); /* * Simple checks */ if (haystack_len == 0) return NULL; if (needle_len == 0) return haystack; /* * Initialize heuristics */ int badcharacter[ALPHABET_SIZE]; int goodsuffix[needle_len + 1]; prepare_badcharacter_heuristic(needle, needle_len, badcharacter); prepare_goodsuffix_heuristic(needle, needle_len, goodsuffix); /* * Boyer-Moore search */ size_t s = 0; while (s <= (haystack_len - needle_len)) { size_t j = needle_len; while (j > 0 && needle[j - 1] == haystack[s + j - 1]) j--; if (j > 0) { int k = badcharacter[(size_t)haystack[s + j - 1]]; int m; if (k < (int)j && (m = j - k - 1) > goodsuffix[j]) s += m; else s += goodsuffix[j]; } else { return haystack + s; } } /* not found */ return NULL; }
실행 예제
/* 이 예제는 http://www.cplusplus.com/reference/clibrary/cstring/strstr/ 에서 가져왔습니다. */ #include <stdio.h> #include <string.h> int main() { char str[] = "This is a simple string"; char* pch; pch = strstr(str, "simple"); strncpy(pch, "sample", 6); puts(str); return 0; }
실행 결과
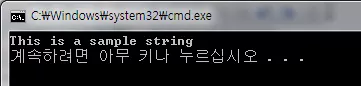
참고 자료
strspn : 특정한 문자열이 포함된 정도를 구한다.
strpbrk: 어떠한 문자열들의 문자들을 키로 하여 특정 문자열에서 그 키들을 검색한다.
strchr : 특정 문자열에서 특정 문자가 첫번째로 나타나는 곳의 위치를 구한다.

댓글을 불러오는 중입니다..