모두의 코드
씹어먹는 C++ - <20 - 3. 코드 부터 실행 파일 까지 - 링킹 (Linking)>
이번 강좌에서는
저장 방식 지정자 (Storage class specifier)
저장 기간 (Storage duration) -
automatic,static,thread링크 방식 (Linkage) - internal, external
이름 맹글링 (Name Mangling)
링킹 (Linking)
재배치 (Relocation) -
R_X86_64_PC32,R_X86_64_PLT32등등정적 링킹 (Static linking)
동적 링킹 (Dynamic linking)
에 대해서 다루어 보겠습니다.

앞선 강의 에서 링킹 과정에서 목적 코드들에 정의된 심볼들 (함수들이나 객체들) 의 위치를 확정 시킨다고 하였습니다.
이 때 C++ 에서 심볼들의 위치들을 정할 때 어떠한 방식으로 정할지 알려주는 키워들이 있는데 이들을 바로 Storage class specifier 라고 합니다. 굳이 번역하자면 저장 방식 지정자 라고 부르는 것이 좋을 것 같습니다.
저장 방식 지정자 (Storage class specifier)
C++ 에서 허용 하는 Storage class specifier 들은 아래와 같이 총 4 가지가 있습니다.
staticthread_localexternmutable(이 녀석의 경우 저장 기간과 링크 방식에 영향을 주지는 않습니다.)
이전에는 auto 와 register 지정자들도 있었는데 이들은 각각 C++ 11 과 C++ 17 에서 사라졌습니다. 이 키워드들을 통해 심볼들의 두 가지 중요한 정보들을 지정할 수 있습니다. 바로 저장 기간 (Storage duration) 과 링크 방식 (Linkage) 입니다. 각각이 무엇인지 아래에서 살펴보도록 하겠습니다.
저장 기간 (Storage duration)
프로그램에서의 모든 객체들의 경우 반드시 아래 넷 중에 한 가지 방식의 저장 기간을 가지게 됩니다.
자동 (automatic) 저장 기간
여기에 해당하는 객체들의 경우 보통 {} 안에 정의된 녀석들로 코드 블록을 빠져나가게 되면 자동으로 소멸하게 됩니다. static, extern, thread_local 로 지정된 객체들 이외의 모든 지역 객체들이 바로 이 자동 저장 기간을 가지게 됩니다. 쉽게 말해 우리가 흔히 생각하는 지역 변수들이 여기에 해당됩니다.
int func() { int a; SomeObject x; { std::string s; } static int not_automatic; }
위 경우 a, x, s 모두 자동 저장 기간을 가집니다. 반면에 not_automatic 는 아닙니다.
static 저장 기간
static 저장 기간에 해당하는 객체들의 경우 프로그램이 시작할 때 할당 되고, 프로그램이 끝날 때 소멸되는 친구들입니다. 그리고 static 객체들은 프로그램에서 유일하게 존재합니다. 예를 들어서 지역 변수의 경우 만일 여러 쓰레드에서 같은 함수를 실행한다면 같은 지역 변수의 복사본들이 여러 군데 존재하겠지만 static 객체들은 이 경우에도 유일하게 존재합니다.
보통 함수 밖에 정의된 것들이나 (즉 namespace 단위에서 정의된 것들) static 혹은 extern 으로 정의된 객체들이 static 저장 기간을 가집니다. 참고로 static 키워드와 static 저장 기간 을 가진다는 것을 구분해야 합니다. static 키워드가 붙은 객체들이 static 저장 기간을 가지는 것은 맞지만, 다른 방식으로 정의된 것들도 static 저장 기간을 가질 수 있습니다.
예를 들어서
int a; // 전역 변수 static 저장 기간 namespace ss { int b; // static 저장 기간 } extern int a; // static 저장 기간 int func() { static int x; // static 저장 기간 }
위와 같이 여러가지 방식으로 정의된 객체들이 static 저장 기간을 가지게 됩니다.
쓰레드(thread) 저장 기간
쓰레드 저장 기간에 해당하는 객체들의 경우 쓰레드가 시작할 때 할당 되고, 쓰레드가 종료될 때 소멸되는 객체들입니다. 각 쓰레드들이 해당 객체들의 복사본들을 가지게 됩니다. thread_local 로 선언된 객체들이 이 쓰레드 저장 기간을 가질 수 있습니다.
#include <iostream> #include <thread> thread_local int i = 0; void g() { std::cout << i; } void threadFunc(int init) { i = init; g(); } int main() { std::thread t1(threadFunc, 1); std::thread t2(threadFunc, 2); std::thread t3(threadFunc, 3); t1.join(); t2.join(); t3.join(); std::cout << i; }
실행 결과
3120
예를 들어서 위 예제를 살펴봅시다. 아마 몇 번 실행하다보면 1230, 2130, 3120 등과 같은 결과를 볼 수 있을 것입니다. 그 이유는 thread_local 로 정의된 i 가 각 쓰레드에 유일하게 존재하기 때문이죠. 마치 정의는 전역 변수인 것 처럼 정의되어 있지만, 실제로는 각 쓰레드에 하나씩 복사본이 존재하게 되고, 각 쓰레드 안에서 해당 i 를 전역 변수인것마냥 참조할 수 있게 됩니다.
동적 (Dynamic) 저장 기간
동적 저장 기간의 경우 동적 할당 함수를 통해서 할당 되고 해제되는 객체들을 의미 합니다. 대표적으로 new 와 delete 로 정의되는 객체들을 의미하지요.
이러한 저장 방식은 나중에 링커에서 해당 변수나 함수들을 배치시에 어디에 배치할 지 중요한 정보로 사용됩니다.
링크 방식 (Linkage)
앞선 저장 방식이 객체 들에게만 해당되는 내용이였다면 링크 방식의 경우 C++ 의 모든 객체, 함수, 클래스, 템플릿, 이름 공간 등등을 지칭하는 이름들에 적용되는 내용입니다. C++ 에선 아래와 같은 링크 방식들을 제공합니다. 이 링크 방식에 따라서 어떤 이름이 어디에서 사용될 수 있는지 지정할 수 있습니다.
링크 방식 없음 (No linkage)
블록 스코프 ({}) 안에 정의되어 있는 이름들이 이 경우에 해당합니다. (extern 으로 지정되지 않는 이상) 링크 방식이 지정되지 않는 개체들의 경우에는 같은 스코프 안에서만 참조할 수 있습니다. 예를 들어서
{ int a = 3; } a; // 오류
위 경우 a 라는 변수는 {} 안에 링크 방식이 없는 상태로 정의되어 있기 때문에 스코프 바깥에서 a 를 참조할 수 없게 됩니다.
내부 링크 방식 (Internal Linkage)
static 으로 정의된 함수, 변수, 템플릿 함수, 템플릿 변수들이 내부 링크 방식에 해당됩니다. 내부 링크 방식으로 정의된 것들의 경우 같은 TU 안에서만 참조 할 수 있습니다. 그 외에도 익명의 이름 공간에 정의된 함수나 변수들 모두 내부 링크 방식이 적용됩니다. 예를 들어서
namespace { int a; // <- 내부 링크 방식 } static int a; // 이와 동일한 의미
외부 링크 방식 (External Linkage)
마지막으로 살펴볼 방식으로 외부 링크 방식이 있습니다. 외부 링크 방식으로 정의된 개체들은 다른 TU 에서도 참조 가능합니다. 참고로 외부 링크 방식으로 정의된 개체들에 언어 링크 방식 을 정의할 수 있어서, 다른 언어 (C 와 C++) 사이에서 함수를 공유하는 것이 가능해집니다.
앞서 링크 방식이 없는 경우나 내부 링크 방식을 개체들을 정의하는 경우를 제외하면 나머지 모두 외부 링크 방식으로 정의됨을 알 수 있습니다. 참고로, 블록 스코프 안에 정의된 변수를 외부 링크 방식으로 선언하고 싶다면 extern 키워드를 사용하면 됩니다.
언어 링크 방식을 선언하고 싶다면 다음과 같이 하면 됩니다.
extern "C" int func(); // C 및 C++ 에서 사용할 수 있는 함수. // C++ 에서만 사용할 수 있는 함수. 기본적으로 C++ 의 모든 함수들에 extern "C++" // 이 숨어 있다고 보시면 됩니다. 따라서 아래처럼 굳이 명시해줄 필요가 없습니다. extern "C++" int func2(); int func2(); // 위와 동일
이름 맹글링 (Name Mangling)
앞서 C 에서 C++ 의 함수를 사용하기 위해서는 extern "C" 로 언어 링크 방식을 명시해주어야 한다고 하였습니다. 그 이유는, 목적파일 생성시 C 컴파일러가 함수 이름을 변환하는 방식과 C++ 컴파일러가 함수 이름을 변환하는 방식이 다르기 때문입니다.
일단 C 의 경우 함수 이름 변환 자체가 이루어 지지 않습니다. 만약에 아래와 같이 func 이란 함수를 정의했다고 해봅시다.
int func(const char* s) {}
이를 C 컴파일러가 컴파일 하면 변환된 이름은 그냥
$ nm a.out 0000000000000000 T func
func 임을 알 수 있습니다. 참고로 nm 은 목적 파일에 정의되어 있는 심볼들을 모두 출력해주는 프로그램입니다.
반면에 똑같은 소스코드를 C++ 컴파일러로 컴파일 해봅시다.
$ nm a.out 0000000000000000 T _Z4funcPKc
위 경우 함수의 이름이 바뀐 것을 알 수 있죠? 이와 같이 C++ 에서는 목적 코드 생성시에 컴파일러가 함수의 이름을 바꾸는 것을 볼 수 있습니다. 이를 이름 맹글링(Name mangling) 이라 하는데, 맹글링 이라는 단어의 뜻이 원래 엉망진창으로 만들다 라는 의미 입니다. 실제로 함수의 이름이 func 에서 알아보기 힘든 버전으로 바뀌었지요.
이렇게 이름 맹글링을 하는 이유는 C 와는 다르게 C++ 에서는 같은 이름의 함수를 정의할 수 있기 때문입니다. 일단 함수의 오버로딩을 통해서 인자가 다른 같은 이름의 함수들을 정의할 수 있고 인자와 이름이 모두 똑같더라도 다른 이름 공간에 들어가 있다면 다른 함수로 취급됩니다. 따라서, 함수의 이름 자체만으로는 어떤 함수를 호출할 지 구분할 수 가 없죠.
이름 맹글링을 하게 되면 원래의 함수 이름에 이름 공간 정보와 함수의 인자 타입 정보들이 추가됩니다. 따라서 같은 이름의 함수일 지라도, 이름 맹글링을 거치고 다면 다른 이름의 함수로 바뀌기 때문에 링킹을 성공적으로 수행할 수 있습니다.
실제로 아래 함수들의 이름들은 모두 같지만
int func(const char* s) {} int func(int i) {} int func(char c) {} namespace n { int func(const char* s) {} int func(int i) {} int func(char c) {} } // namespace n
맹글링 된 이름을 살펴보면
$ nm test.o 000000000000001d T _Z4funcc 000000000000000f T _Z4funci 0000000000000000 T _Z4funcPKc 000000000000004a T _ZN1n4funcEc 000000000000003c T _ZN1n4funcEi 000000000000002d T _ZN1n4funcEPKc
와 같이 전부다 다른 이름으로 변환된 것을 볼 수 있죠. 참고로 컴파일러마다 이름 맹글링을 하는 방식이 조금씩 다르기 때문에 A 라는 컴파일러에서 생성한 목적 코드를 B 컴파일러가 링킹할 때 문제가 될 수 있습니다.
아무튼 C 에서 C++ 의 함수를 호출하기 위해서는 반드시 이름 맹글링이 되지 않는 함수 심볼을 생성해야 합니다. 따라서 extern "C" 를 통해서 이 함수는 이름 맹글링을 하지 마! 라고 컴파일러에게 전달할 수 있습니다.
extern "C" int func(const char* s) {} int func(char c) {}
위 코드를 컴파일 하면
$ nm test.o 0000000000000000 T func 000000000000000f T _Z4funcc
위와 같이 extern "C" 로 표기된 func 은 이름 맹글링이 되지 않았지만 밑에 보통의 int func 의 경우 이름 맹글링이 된 것을 알 수 있습니다.
당연히도 extern "C" 가 붙은 함수들 끼리는 오버로딩을 할 수 없습니다. 왜냐하면 심볼 생성시 두 함수를 구분할 수 있는 방법이 없기 때문이죠. (이름이 같으니까.)
링킹
위 단계에서 아무런 문제가 없었더라면 이제 비로소 진짜 링킹(Linking)을 수행할 수 있습니다. 링킹이란, 각각의 TU 들에서 생성된 목적 코드들을 한데 모아서 하나의 실행 파일 을 만들어내는 작업입니다. 물론 단순히 목적 코드들을 이어 붙이는 작업만 하는 것은 아닙니다.
링킹 과정이 끝나기 전 까지 변수들과 함수, 그리고 데이터들의 위치를 확정시킬 수 없습니다. 따라서 TU 들이 생성한 목적 코드들에게는 각각의 심볼들의 저장 방식과 링크 방식에 따라서 여기 여기에 배치했으면 좋겠다 라는 희망 사항만 써져있을 뿐입니다. 예를 들어서
static int a = 3; int b = 3; const int c = 3; static int d; int func() {} static int func2() {}
위와 같은 코드를 생각해봅시다. 위 코드에 정의된 심볼들의 희망 위치들은 어떻게 나타내질까요?
$ nm test.o 0000000000000004 D b 0000000000000000 T _Z4funcv 0000000000000000 d _ZL1a 0000000000000000 r _ZL1c 0000000000000000 b _ZL1d 000000000000000b t _ZL5func2v
nm 프로그램은 심볼들의 이름들 왼쪽에 어떠한 방식으로 링크시에 심볼을 배치할지 에 대한 정보를 보여줍니다. 먼저 가운데 알파벳을 봅시다. 대문자 알파벳의 경우 해당 심볼은 외부 링크 방식으로 선언된 심볼이란 의미 입니다. 즉 해당 심볼은 다른 TU 에서 접근할 수 있는 심볼입니다. 반면에 소문자 알파벳의 경우 해당 심볼은 내부 링크 방식으로 선언된 심볼이란 의미 입니다. 따라서 해당 심볼은 이 TU 안에서만 접근 가능하죠.
위 대문자로 된 심볼들을 보면 b, func 을 볼 수 있는데 두 함수 다 외부 링크 방식임을 알 수 있습니다. 반면에 나머지 a, c, d, func2 는 모두 static 이므로 내부 링크 방식이죠.
그 다음에 알파벳 자체는 어떠한 방식으로 해당 심볼들을 배치할 지 알려줍니다. nm 의 man 페이지 에서 전체 알파벳들에 대한 설명을 볼 수 있지만 일부만 소개해본다면
B, b: 초기화 되지 않은 데이터 섹션 (BSS 섹션)D, d: 초기화 된 데이터 섹션T, t: 텍스트 (코드) 섹션R, r: 읽기 전용 (read only) 섹션
입니다. 예를 들어 전역 변수인 b 를 볼까요?
0000000000000004 D b
b 는 값을 3 으로 초기화 하였으므로 당연히 초기화 된 데이터 섹션에 가게 됩니다.
반면에 static int d 의 경우
0000000000000000 b _ZL1d
값을 초기화 하지 않았으므로 초기화 되지 않은 데이터 섹션인 BSS 로 지정되어 있음을 알 수 있습니다.
0000000000000000 T _Z4funcv // func() 000000000000000b t _ZL5func2v // func2()
마찬가지로 두 개의 함수들만 보아도 static 이 아닌 func 는 T, static 인 func2 는 t 로 표시되어 있음을 알 수 있습니다.
맨 앞에 오는 정수값은 섹션의 시작으로 부터 해당 심볼이 어디에 위치해 있는지 알려줍니다. 예를 들어서 func 함수의 경우 텍스트 섹션 시작 부분에 있다는 의미 이고 (오프셋이 0 이니까), func2 의 경우 b 만큼 떨어진 부분에 위치해있다는 의미죠. 실제로 objdump 로 코드를 살펴보면;
objdump -S s.o s.o: file format elf64-x86-64 Disassembly of section .text: 0000000000000000 <_Z4funcv>: 0: f3 0f 1e fa endbr64 4: 55 push %rbp 5: 48 89 e5 mov %rsp,%rbp 8: 90 nop 9: 5d pop %rbp a: c3 retq 000000000000000b <_ZL5func2v>: b: f3 0f 1e fa endbr64 f: 55 push %rbp 10: 48 89 e5 mov %rsp,%rbp 13: 90 nop 14: 5d pop %rbp 15: c3 retq
정확히 0xb 부분에 func2 가 자리하고 있음을 알 수 있습니다.
재배치 (Relocation)
지난 강의에서도 이야기 하였듯이 TU 에서 생성된 목적 코드들은 링킹 과정 전 까지 심볼들의 위치를 확정할 수 없기 때문에 추후에 심볼들의 위치가 확정이 되면 값을 바꿔야 할 부분들을 적어놓은 재배치 테이블 (Relocation Table) 을 생성한다고 하였습니다. 예를 들어서 아래와 같은 코드를 살펴봅시다.
static int a = 3; int b = 3; static int c; static int func2() { c += a + b; return c; } int func3() { b += c; return b; } int func() { a += func2(); a += func3(); return a; }
objdump 에 -r 옵션을 주면 재배치가 필요한 부분들을 보여줍니다. 예를 들어서 func2 의 목적 코드가 어떤 식으로 생겼는지 살펴봅시다.
objdump -Sr s.o s.o: file format elf64-x86-64 Disassembly of section .text: 0000000000000000 <_ZL5func2v>: static int a = 3; int b = 3; static int c; static int func2() { 0: f3 0f 1e fa endbr64 4: 55 push %rbp 5: 48 89 e5 mov %rsp,%rbp c = a + b; 8: 8b 15 00 00 00 00 mov 0x0(%rip),%edx # e <_ZL5func2v+0xe> a: R_X86_64_PC32 .data-0x4 e: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 14 <_ZL5func2v+0x14> 10: R_X86_64_PC32 b-0x4 14: 01 d0 add %edx,%eax 16: 89 05 00 00 00 00 mov %eax,0x0(%rip) # 1c <_ZL5func2v+0x1c> 18: R_X86_64_PC32 .bss-0x4 return c; 1c: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 22 <_ZL5func2v+0x22> 1e: R_X86_64_PC32 .bss-0x4 } 22: 5d pop %rbp 23: c3 retq
예상했던대로, 내부 및 외부 링크 방식인 변수들인 a, b, c 들은 데이터 섹션과 BSS 섹션의 위치가 확정되기 전까지 어디에 위치할 지 모르기 때문에 추후에 재배치 시켜야만 합니다. 예를 들어서 a 의 값을 읽어들이는 부분부터 봅시다.
8: 8b 15 00 00 00 00 mov 0x0(%rip),%edx # e <_ZL5func2v+0xe>
먼저 0x0(%rip),%edx 의 어셈블리는 C 코드로 바꿔서 생각했을 때 %edx = *(int*)(%rip + 0x0) 이라고 보시면 됩니다. 즉 RIP 레지스터에다 0 만큼 더한 주소값에 있는 데이터를 읽어라 라는 의미가 됩니다.
여기서 a 의 상대적 위치가 결정되지 않았기 때문에 일단 0 으로 대체되어 있습니다. 그 대신에, 만일 a 가 어디에 배치되는지 위치가 확정이 된다면,
$ readelf -r s.o Offset Info Type Sym. Value Sym. Name + Addend 00000000000a 000300000002 R_X86_64_PC32 0000000000000000 .data - 4
위와 같이 해당 부분을 R_X86_64_PC32 의 형태로 재배치 하라고 써져 있습니다. (위 objdump 출력에도 나와있죠.) 레퍼런스에 따르면 R_X86_64_PC32 은 해당 부분 4 바이트 영역을 S + A - P 를 계산한 값으로 치환해라 라는 의미 입니다. 이 때 S, A, P 는 각각
S : 재배치 후에 해당 심볼의 실제 위치
P : 재배치 해야하는 부분의 위치
A : 더해지는 값으로, 재배치 테이블에서 그 값을 확인할 수 있다.
일단 readelf 를 통해 확인했을 때 일단 A 의 값은 -4 임을 알 수 있습니다 (Addend 부분). 나머지 부분은 링킹 후에 심볼들의 위치가 정해져야지 알 수 있겠죠. 따라서 간단히 int main{} 만 있는 파일과 같이 링크해보도록 합시다.
nm 을 통해서 우리의 경우 a 는 4010 에 위치 되어 있는 것을 확인했습니다.
$ nm s 0000000000004010 d _ZL1a
따라서 S 는 0x4010 이 되겠죠.
또한 func2 는 1138 에 위치해있으므로 (마찬가지로 nm 을 통해서 확인 가능)
$ nm s 0000000000001138 t _ZL5func2v
재배치 해야 할 위치는 0x1138 에서 a 를 더한 만큼인 0x1142 가 됩니다. 따라서 P 는 0x1142 이므로, S + A - P = 0x4010 - 0x4 - 0x1142 = 0x2ECA 가 되겠죠.
과연 우리의 계산이 맞는지 확인해볼까요?
0000000000001138 <_ZL5func2v>: static int a = 3; int b = 3; static int c; static int func2() { 1138: f3 0f 1e fa endbr64 113c: 55 push %rbp 113d: 48 89 e5 mov %rsp,%rbp c = a + b; 1140: 8b 15 ca 2e 00 00 mov 0x2eca(%rip),%edx # 4010 <_ZL1a> 1146: 8b 05 c8 2e 00 00 mov 0x2ec8(%rip),%eax # 4014 <b> 114c: 01 d0 add %edx,%eax 114e: 89 05 c8 2e 00 00 mov %eax,0x2ec8(%rip) # 401c <_ZL1c> return c; 1154: 8b 05 c2 2e 00 00 mov 0x2ec2(%rip),%eax # 401c <_ZL1c> } 115a: 5d pop %rbp 115b: c3 retq
실제로 해당 부분이 ca 2e 00 00 으로 바뀐 것이 보이죠! 리틀 엔디언임을 고려하면 해당 값이 0x2ECA 임을 알 수 있습니다. 0x2eca(%rip) 의 의미는 RIP 레지스터에서 0x2ECA 만큼 떨어진 곳에 있는 곳에서 4 바이트 만큼 읽어서 EDX 레지스터에 저장하라는 의미 입니다. 해당 명령어를 실행할 때 RIP 에는 다음에 실행할 명령어의 위치가 들어가 있으니, 0x2ECA + 0x1146 = 0x4010 에 위치한 곳의 4 바이트를 읽어들이겠죠. 즉 정확히 우리의 변수인 a 가 위치해있는 곳입니다!
나머지 변수들의 위치도 비슷하게 계산됩니다. 여러분이 직접 한 번 계산해보세요.
이번에는 func3 를 한 번 살펴보겠습니다.
45: 48 89 e5 mov %rsp,%rbp a += func2(); 48: e8 b3 ff ff ff callq 0 <_ZL5func2v> 4d: 8b 15 00 00 00 00 mov 0x0(%rip),%edx # 53 <_Z4funcv+0x13> 4f: R_X86_64_PC32 .data-0x4 53: 01 d0 add %edx,%eax 55: 89 05 00 00 00 00 mov %eax,0x0(%rip) # 5b <_Z4funcv+0x1b> 57: R_X86_64_PC32 .data-0x4 a += func3(); 5b: e8 00 00 00 00 callq 60 <_Z4funcv+0x20> 5c: R_X86_64_PLT32 _Z5func3v-0x4 60: 8b 15 00 00 00 00 mov 0x0(%rip),%edx # 66 <_Z4funcv+0x26> 62: R_X86_64_PC32 .data-0x4 66: 01 d0 add %edx,%eax 68: 89 05 00 00 00 00 mov %eax,0x0(%rip) # 6e <_Z4funcv+0x2e> 6a: R_X86_64_PC32 .data-0x4 return a; 6e: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 74 <_Z4funcv+0x34> 70: R_X86_64_PC32 .data-0x4 } 74: 5d pop %rbp 75: c3 retq
먼저 static 함수인 func2 를 호출하는 부분부터 살펴봅시다.
a += func2(); 48: e8 b3 ff ff ff callq 0 <_ZL5func2v>
놀랍게도 이 부분의 경우 재배치가 지정되지 않고 실제 func2 의 위치가 그대로 들어가 있음을 알 수 있습니니다. 왜냐하면 이 callq 의 경우 현재의 RIP 에서 상대 위치를 받는데, 0xFFFFFFB3 가 2 의 보수 표현법으로 -0x4D 이므로, 정확히 주소값 0 을 의미합니다 (0x4D - 0x4D = 0). 그리고 실제로 0 번에 func2 함수가 위치하고 있죠.
그 이유는 static 함수의 경우 내부 링크 방식이기 때문에 TU 밖에서 참조될 일이 없기 때문입니다. 이 때문에 컴파이 타임에 함수의 위치를 확정시킬 수 있습니다. 반면에 외부 링크 방식으로 된 일반적인 func3 함수를 호출하는 부분을 봅시다.
a += func3(); 5b: e8 00 00 00 00 callq 60 <_Z4funcv+0x20> 5c: R_X86_64_PLT32 _Z5func3v-0x4
이 경우 R_X86_64_PLT32 의 형태로 링크를 하고 있습니다. R_X86_64_PLT32 의 경우 뒤에서 다루겠지만 프로시져 링크 테이블 (Procedure Linkage Table) 을 사용한 링킹 방식으로 후에 설명할 동적 링크 방식 (Dynamic linking) 에서 사용됩니다. 하지만 동적 링크 방식을 사용하지 않았을 경우, 그냥 R_X86_64_PC32 와 동일하다고 보시면 됩니다.
우리의 경우 실행 파일을 생성하기 위해 동적 링크 방식을 사용하지 않았으므로 그냥 R_X86_64_PC32 와 같은 식으로 계산됩니다. 실제로 완성된 코드를 살펴보자면
1194: e8 c4 ff ff ff callq 115d <_Z5func3v>
와 같이 되어 있는데, 00 00 00 00 부분이 현재의 RIP 로 부터 상대적 위치값으로 변경되어 있음을 알 수 있습니다.
링크 방식 (정적 링킹 vs 동적 링킹)
위에서 잠깐 동적 링크 방식을 언급하였는데, 컴파일러가 여러 목적 파일들을 링크하는 방식은 정적 링킹 (Static linking) 과 동적 링킹 (Dynamic Linking) 두 가지로 구분됩니다. 이 두 방식의 차이는 간단합니다. 정적 링킹은 정적 라이브러리 (Static library) 를 링크하는 방식이고, 동적 링킹은 동적 라이브러리 (Dynamic library), 다른 말로 공유 라이브러리 (Shared library) 를 링크하는 방식입니다. 뭔가 말장난 같죠? 이 두 라이브러리의 차이를 이해하기 위해서 먼저 정적 라이브러리가 뭔지 알아보도록 합시다.
정적 라이브러리
정적 라이브러리 (Static library) 가 뭔지 설명하기 전에 먼저 라이브러리 라는 개념이 무엇인지 뭔지 생각해봅시다. 라이브러리란 그냥 프로그램이 동작하기 위해 필요한 외부 목적 코드들이라고 생각하시면 됩니다.
예를 들어서 우리가 C++ 에서 iostream 헤더파일을 include 했다면, 이 프로그램이 실행하기 위해서는 iostream 라이브러리가 있어야 하겠죠.
이 때 정적 라이브러리는 우리가 필요로 하는 라이브러리가 링킹 후에 완성된 프로그램 안에 포함된다고 생각하시면 됩니다. 쉽게 말해 실행 파일 자체에 해당 라이브러리 코드가 딱 박혀서 있기 때문에 정적 (static)이라고 하는 것입니다. 예를 들어서 어떤 프로그램이 A 라는 라이브러리와 B 라는 라이브러리를 사용하고 있다면 프로그램의 어셈블리를 출력하였을 때 A 와 B 라이브러리의 모든 코드들이 들어있게 됩니다.
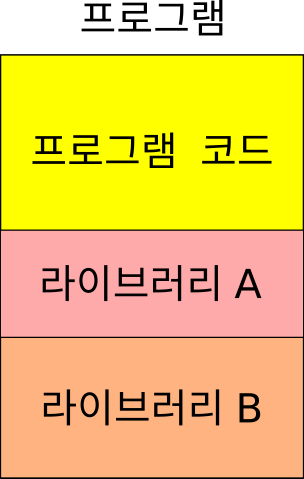
어떻게 생각하면 당연한 일이기도 합니다. 프로그램을 실행하기 위해선 당연히 해당 프로그램이 필요로 하는 코드들이 프로그램 안에 있어야 되기 때문이죠.
정적 라이브러리가 어떻게 링크 되는지 GCC 컴파일러를 사용해서 간단한 정적 라이브러리를 만들어봅시다.
정적 라이브러리 만들기
예를 들어서 foo 라는 함수를 제공하는 foo.cc 파일과 bar 라는 함수를 제공하는 bar.cc 파일이 있다고 해봅시다.
// bar.h void bar();
// bar.cc void bar() {}
// foo.h int foo();
// foo.cc #include "bar.h" int x = 1; int foo() { bar(); x++; return 1; }
이 두 파일들을 각각 컴파일 하면 foo.o 와 bar.o 라는 목적 코드가 생성이 되겠죠. 만일 이 두 함수를 제공하는 정적 라이브러리를 만들기 위해서는, 이 두 목적 파일들을 하나로 묶어주기만 하면 됩니다. 이를 위해선
$ ar crf libfoobar.a foo.o bar.o
라고 치면 libfoobar.a 라는 정적 라이브러리 파일이 만들어집니다. 리눅스에선 통상적으로 정적 라이브러리 파일은 .a 의 확장자를 가집니다. 이 libfoobar.a 은 거창한 것이 아니고 그냥 foo.o 의 내용과 bar.o 의 내용을 하나로 합쳐놓은 것이라 보시면 됩니다. 실제로 objdump 로 libfoobar.a 의 내용을 열어보면;
objdump -S libfoobar.a In archive libfoobar.a: foo.o: file format elf64-x86-64 Disassembly of section .text: 0000000000000000 <_Z3foov>: 0: f3 0f 1e fa endbr64 4: 55 push %rbp 5: 48 89 e5 mov %rsp,%rbp 8: e8 00 00 00 00 callq d <_Z3foov+0xd> d: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 13 <_Z3foov+0x13> 13: 83 c0 01 add $0x1,%eax 16: 89 05 00 00 00 00 mov %eax,0x0(%rip) # 1c <_Z3foov+0x1c> 1c: b8 01 00 00 00 mov $0x1,%eax 21: 5d pop %rbp 22: c3 retq bar.o: file format elf64-x86-64 Disassembly of section .text: 0000000000000000 <_Z3barv>: 0: f3 0f 1e fa endbr64 4: 55 push %rbp 5: 48 89 e5 mov %rsp,%rbp 8: 90 nop 9: 5d pop %rbp a: c3 retq
와 같이 그냥 foo.o 와 bar.o 가 하나로 합쳐진 파일 이라 보시면 됩니다 (마치 리눅스에서 tar 로 파일들을 합친 것과 비슷)
이 정적 라이브러리를 사용하는 방법은 간단합니다.
예를 들어서 main.cc 라는 파일에서 foo 함수를 사용하고 싶다고 해봅시다. 그렇다면 우리가 필요한 것은 foo 함수가 선언 되어 있는 헤더파일 하나 뿐입니다.
#include "foo.h" int main() { foo(); }
통상적인 상황이라면 main 을 컴파일 하면서 실행파일을 생성할 때, foo.cc 코드와 bar.cc 코드를 같이 컴파일 해서 링킹해야 했을 것입니다. 하지만 우리는 이미 foo.cc 와 bar.cc 가 이미 컴파일 되어 있는 libfoobar.a 라는 라이브러리가 있기 때문에 굳이 이들을 다시 컴파일 할 필요가 없습니다.
따라서 아래와 같이 실행 파일을 생성 시에
$ g++ main.cc libfoobar.a -o main
위 처럼 링크해주기만 하면 땡입니다. 그래고 실제로 main 의 내용을 objdump 로 살펴보면
objdump -S main ... (생략) ... 0000000000001129 <main>: 1129: f3 0f 1e fa endbr64 112d: 55 push %rbp 112e: 48 89 e5 mov %rsp,%rbp 1131: e8 07 00 00 00 callq 113d <_Z3foov> 1136: b8 00 00 00 00 mov $0x0,%eax 113b: 5d pop %rbp 113c: c3 retq 000000000000113d <_Z3foov>: 113d: f3 0f 1e fa endbr64 1141: 55 push %rbp 1142: 48 89 e5 mov %rsp,%rbp 1145: e8 16 00 00 00 callq 1160 <_Z3barv> 114a: 8b 05 c0 2e 00 00 mov 0x2ec0(%rip),%eax # 4010 <x> 1150: 83 c0 01 add $0x1,%eax 1153: 89 05 b7 2e 00 00 mov %eax,0x2eb7(%rip) # 4010 <x> 1159: b8 01 00 00 00 mov $0x1,%eax 115e: 5d pop %rbp 115f: c3 retq 0000000000001160 <_Z3barv>: 1160: f3 0f 1e fa endbr64 1164: 55 push %rbp 1165: 48 89 e5 mov %rsp,%rbp 1168: 90 nop 1169: 5d pop %rbp 116a: c3 retq 116b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
위 처럼 libfoobar.a 의 내용이 그대로 박혀있는 것 을 볼 수 있습니다.
이렇게 정적 라이브러리는 링크 타임에 바인딩 된다고 생각하시면 됩니다.
공유 라이브러리 (동적 라이브러리)
정적 라이브러리에는 프로그램 실행에 필요한 모든 코드가 들어가 있기 때문에 환경에 크게 관계 없이 프로그램을 실행 시킬 수 있습니다. 그런데 이 방식은 몇 가지 문제점들이 있습니다.
표준 C 라이브러리인 libc 의 경우 많은 프로그램들이 필요로 합니다. 그런데 libc 라이브러리에는 C 라이브러리의 모든 함수들의 구현이 들어가 있기 때문에 크기가 매우 큽니다 (제 경우 2MB 정도). 따라서 libc 를 프로그램에 정적으로 링크하게 된다면 모든 프로그램의 크기가 최소
2 MB나 된다는 뜻이겠죠? 심지어 모든 프로그램들이 동일한 libc 라이브러리를 사용하고 있다고 해도 말이죠!물론 요즘 세상에 2 MB 정도야 라고 생각할 수 있습니다. 하드 디스크는 용량이 크기 때문이죠. 하지만 문제는 메모리 입니다. 프로그램이 실행되면 프로그램이 메모리에 로드 되는데, 모든 프로그램들이 똑같은 libc 코드들을 메모리에 올린다면 엄청난 메모리 낭비가 되겠죠. 게다가 메모리는 하드 디스크 보다 훨씬 더 귀한 자원입니다.
예를 들어서 새 버전의 libc 나와서 이를 내 시스템에 적용시키고 싶다고 해봅시다. 만일 프로그램들이 libc 를 정적으로 링킹하고 있다면 이 프로그램들을 다시 컴파일해야 합니다.
마지막 문제로 정적 라이브러리 전체를 링킹하면서 사용하지 않는 함수들 까지 전부다 프로그램에 포함된다는 것입니다. 이도 마찬가지로 용량 낭비를 유발합니다.
따라서 컴퓨터 개발자들은 이 문제를 해결하기 위해 획기적인 방법을 제시합니다. 앞서 정적 라이브러리의 가장 큰 문제점으로 모든 프로그램들이 같은 라이브러리를 링킹 하더라도 정적으로 링킹할 경우 프로그램 내에 동일한 라이브러리 코드를 포함해야 한다 였습니다. 그렇다면 만약에 이렇게 많은 프로그램 상에서 사용되는 라이브러리를 컴퓨터 메모리 상에 딱 하나 올려놓고, 이를 사용하는 프로그램들이 해당 라이브러리를 공유 하면 어떨까요? 이 것이 바로 공유 라이브러리 (Shared library) 의 출발 입니다.
아래 그림은 여러 프로그램들이 메모리에 올라가 있을 때 정적 라이브러리를 사용한 프로그램과 공유 라이브러리를 사용한 라이브러리의 차이 입니다.
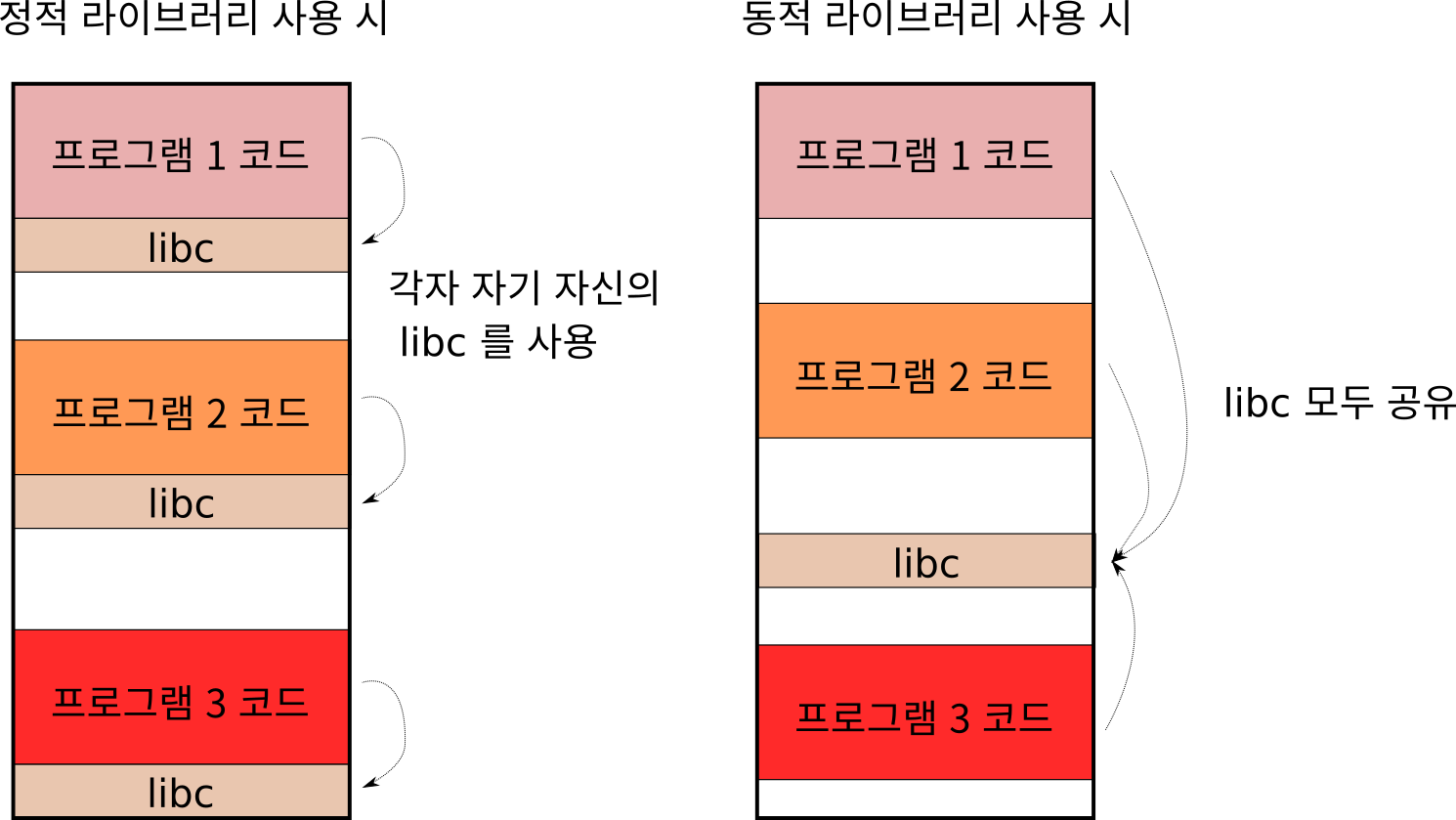
보시다시피 libc 의 경우 정적 라이브러리를 사용하게 되면 각 프로그램마다 libc 를 가지고 있게 되지만 공유 라이브러리 형태로 사용한다면 메모리에 딱 한 군데에만 libc 가 있으면 충분합니다. 예를 들어서 현재 제 프로그램에서 libc 라이브러리를 사용하는 프로세스들을 보면
$ lsof /usr/lib/x86_64-linux-gnu/libc-2.31.so
lsof: WARNING: can't stat() fuse.gvfsd-fuse file system /run/user/125/gvfs
Output information may be incomplete.
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
systemd 1632 jaebum mem REG 8,6 2029224 8390793 /usr/lib/x86_64-linux-gnu/libc-2.31.so
onedrive 1645 jaebum mem REG 8,6 2029224 8390793 /usr/lib/x86_64-linux-gnu/libc-2.31.so
pulseaudi 1646 jaebum mem REG 8,6 2029224 8390793 /usr/lib/x86_64-linux-gnu/libc-2.31.so
tracker-m 1648 jaebum mem REG 8,6 2029224 8390793 /usr/lib/x86_64-linux-gnu/libc-2.31.so
dbus-daem 1665 jaebum mem REG 8,6 2029224 8390793 /usr/lib/x86_64-linux-gnu/libc-2.31.so
gvfsd 1672 jaebum mem REG 8,6 2029224 8390793 /usr/lib/x86_64-linux-gnu/libc-2.31.so
gvfsd-fus 1682 jaebum mem REG 8,6 2029224 8390793 /usr/lib/x86_64-linux-gnu/libc-2.31.so
gvfs-udis 1700 jaebum mem REG 8,6 2029224 8390793 /usr/lib/x86_64-linux-gnu/libc-2.31.so
gvfs-goa- 1707 jaebum mem REG 8,6 2029224 8390793 /usr/lib/x86_64-linux-gnu/libc-2.31.so
... (생략) ...
lsof 프로그램을 사용하면 우리가 지정한 공유 라이브러리를 어떤 프로그램이 사용하고 있는지 알 수 있습니다. 위 처럼 많은 수의 프로그램들이 사용하고 있죠.
그런데 여기서 잠깐! 컴퓨터 구조를 배우신 분들은 각 프로세스들은 메모리는 다른 프로세스들과 독립적이고 서로 접근할 수 없는 것으로 알고 있을 것입니다. 그런데 어떻게 서로 다른 프로그램이 같은 메모리를 공유할 수 있는 것일까요? 그 이유는 간단합니다.
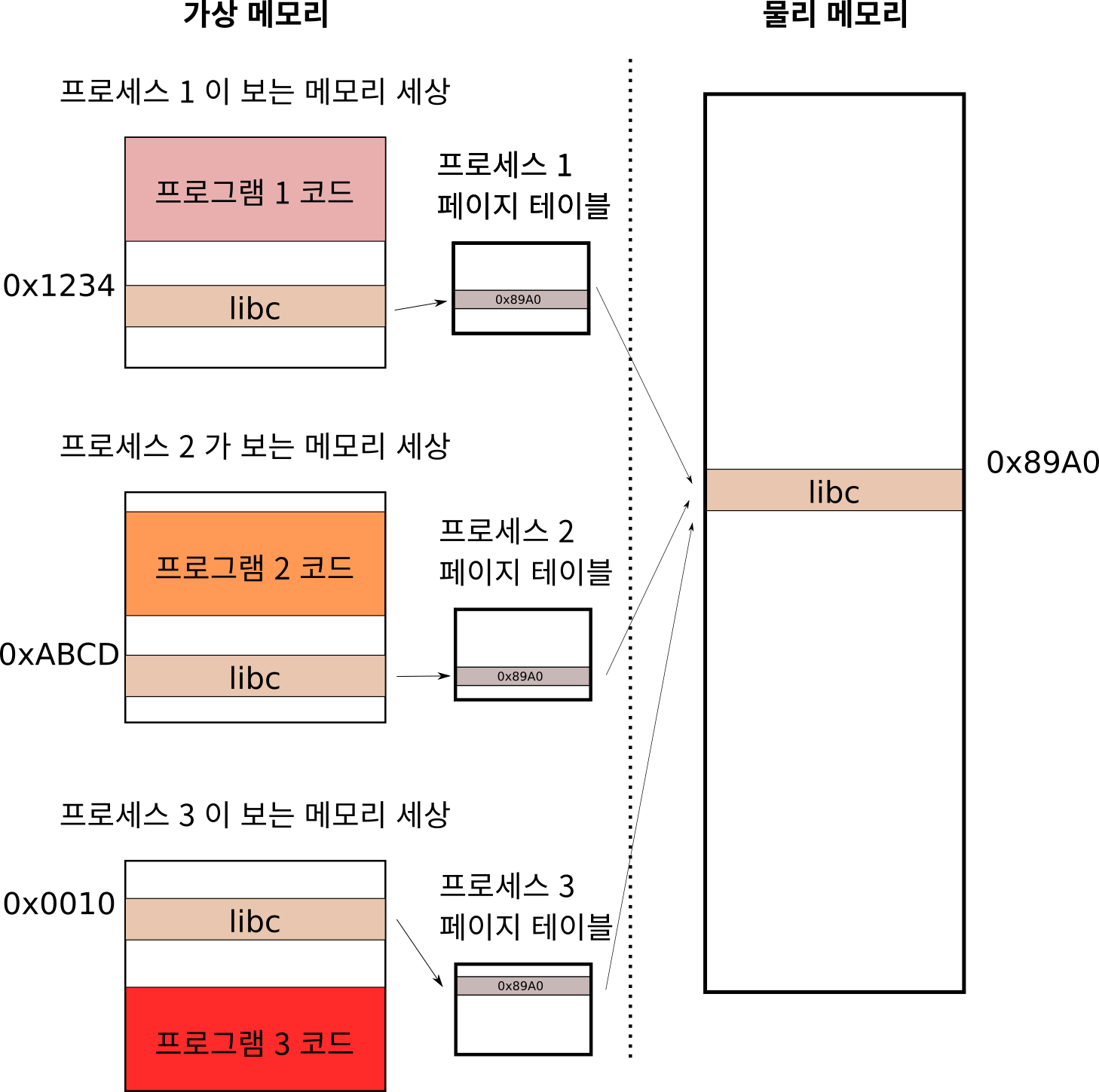
위 처럼 각각의 프로세스에는 고유의 페이지 테이블이 있습니다. 실제 프로세스가 보는 가상 메모리 에서는 (위 그림에서 왼쪽 부분) 는 오른쪽과 같습니다. 문제는 프로세스마다 코드의 크기가 다르기 때문에 공유 라이브러리가 각 프로세스의 가상 메모리에 놓이는 위치가 다르게 된다는 점입니다. 위 그림 처럼 프로세스 1 의 libc 는 0x1234 에, 프로세스 2 의 libc 는 0xABCD 에, 프로세스 3 의 libc 는 0x10 에 놓여 있습니다.
하지만 걱정할 필요 없습니다. 프로세스 마다 가상 메모리를 물리 메모리로 변환하는 페이지 테이블이 있기 때문입니다 (페이지 테이블의 뭔지 모르신다면 여기를 참조하시면 됩니다.)
따라서 실제 물리 메모리에 libc 코드를 딱 한 군데만 올려 놓고 각 프로세스의 페이지 테이블 내용을 바꿔줌으로써 마치 프로세스 마다 고유의 위치에 libc 코드가 있는 것 마냥 사용할 수 있습니다.
그렇다면 한 가지 궁금한 것이 있습니다.
그러면 그냥 정적 라이브러리를 공유 라이브러리 처럼 쓰면 안되나?
좋은 질문입니다. 앞서 말했듯이 공유 라이브러리의 경우 프로세스의 가상 메모리 안의 임의의 위치에 로드될 수 있어야 된다고 하였습니다. 그런데, 만약에 앞서 보았던 libfoobar.a 에서의 foo 함수의 어셈블리 코드를 다시 봅시다.
000000000000113d <_Z3foov>: 113d: f3 0f 1e fa endbr64 1141: 55 push %rbp 1142: 48 89 e5 mov %rsp,%rbp 1145: e8 16 00 00 00 callq 1160 <_Z3barv> 114a: 8b 05 c0 2e 00 00 mov 0x2ec0(%rip),%eax # 4010 <x> 1150: 83 c0 01 add $0x1,%eax 1153: 89 05 b7 2e 00 00 mov %eax,0x2eb7(%rip) # 4010 <x> 1159: b8 01 00 00 00 mov $0x1,%eax 115e: 5d pop %rbp 115f: c3 retq
위 처럼 x 의 값을 읽는 부분에서 실제 x 의 주소값으로 값이 대체된 것을 볼 수 있습니다. 다시 말해 정적 라이브러리는 외부 링크 방식을 가지는 심볼들을 호출하는 부분이 모두 해당 심볼들의 실제 주소값으로 대체되었다는 점입니다. 해당 라이브러리 코드를 메모리 임의의 지점에 불러온다면 우리가 원하는 심볼들을 찾을 수 없게 됩니다.
따라서 공유 라이브러리의 경우 정적 라이브러리와 다른 방식으로 외부 링크 방식을 가지는 심볼들을 불러옵니다. 그 차이를 알기 위해 먼저 공유 라이브러리를 한 번 만들어보겠습니다.
공유 라이브러리 만들기
공유 라이브러리는 컴파일러를 통해서 제작할 수 있습니다. 만약에 원래 하던 것 처럼 foo.cc 와 bar.cc 를 컴파일 했다고 해봅시다.
$ g++ -shared foo.o bar.o -o libfoobar.so /usr/bin/ld: foo.o: relocation R_X86_64_PC32 against symbol `x' can not be used when making a shared object; recompile with -fPIC /usr/bin/ld: final link failed: bad value collect2: error: ld returned 1 exit status
그렇다면 위와 같은 오류 메세지를 볼 수 있습니다. 오류 메세지를 그대로 해석해보면 x 심볼에 적용된 R_X86_64_PC32 방식은 공유 라이브러리를 만드는데 사용할 수 없다는 의미죠. 한 번 objdump 로 x 심볼이 사용되는 foo.o 의 재배치 방식을 살펴보겠습니다.
objdump -Sr foo.o foo.o: file format elf64-x86-64 Disassembly of section .text: 0000000000000000 <_Z3foov>: 0: f3 0f 1e fa endbr64 4: 55 push %rbp 5: 48 89 e5 mov %rsp,%rbp 8: e8 00 00 00 00 callq d <_Z3foov+0xd> 9: R_X86_64_PLT32 _Z3barv-0x4 d: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 13 <_Z3foov+0x13> f: R_X86_64_PC32 x-0x4 13: 83 c0 01 add $0x1,%eax 16: 89 05 00 00 00 00 mov %eax,0x0(%rip) # 1c <_Z3foov+0x1c> 18: R_X86_64_PC32 x-0x4 1c: b8 01 00 00 00 mov $0x1,%eax 21: 5d pop %rbp 22: c3 retq
실제로 x 심볼을 참조하는 부분에서 R_X86_64_PC32 방식을 사용하고 있는 것을 알 고 있습니다. 그렇다면 왜 R_X86_64_PC32 재배치 방식을 공유 라이브러리를 만드는데 사용할 수 없을까요? 그 이유는 R_X86_64_PC32 방식을 계산할 때 S + A - P 였던 것을 기억하시죠? 그런데 공유 라이브러리의 경우 임의의 위치에 라이브러리가 위치할 수 있기 때문에 섹션의 위치를 특정할 수 없습니다. 따라서 S + A - P 의 값 자체를 계산할 수 가 없죠.
따라서 결국에는 foo.cc 와 bar.cc 를 다시 컴파일 해야 합니다. 이 때 컴파일 시에 인자로 위치와 무관한 코드 (Position Independent Code - PIC) 를 만들라는 의미의 -fpic 인자를 전달해줘야 합니다.
$ g++ -c -fpic foo.cc $ g++ -c -fpic bar.cc $ g++ -shared foo.o bar.o -o libfoobar.so
를 하면 공유 라이브러리인 libfoobar.so 가 잘 생성된 것을 볼 수 있습니다. 참고로 리눅스에선 보통 공유 라이브러리의 확장자로 so 를 사용합니다 (shared object)
그렇다면 libfoobar.so 한 번 간단한 프로그램에 링크해서 사용해 보도록 하겠습니다.
#include "bar.h" #include "foo.h" int main() { bar(); foo(); }
링크 하는 방법은 이전과도 똑같이 그냥
$ g++ main.cc libfoobar.so -g -o main
하면 됩니다. 그렇다면 main 의 내용은 어떻게 생겼는지 한 번 objdump 로 까봅시다.
objdump -S main main: file format elf64-x86-64 Disassembly of section .plt: 0000000000001020 <.plt>: 1020: ff 35 92 2f 00 00 pushq 0x2f92(%rip) # 3fb8 <_GLOBAL_OFFSET_TABLE_+0x8> 1026: f2 ff 25 93 2f 00 00 bnd jmpq *0x2f93(%rip) # 3fc0 <_GLOBAL_OFFSET_TABLE_+0x10> 102d: 0f 1f 00 nopl (%rax) 1030: f3 0f 1e fa endbr64 1034: 68 00 00 00 00 pushq $0x0 1039: f2 e9 e1 ff ff ff bnd jmpq 1020 <.plt> 103f: 90 nop 1040: f3 0f 1e fa endbr64 1044: 68 01 00 00 00 pushq $0x1 1049: f2 e9 d1 ff ff ff bnd jmpq 1020 <.plt> 104f: 90 nop Disassembly of section .plt.sec: 0000000000001060 <_Z3foov@plt>: 1060: f3 0f 1e fa endbr64 1064: f2 ff 25 5d 2f 00 00 bnd jmpq *0x2f5d(%rip) # 3fc8 <_Z3foov> 106b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1) 0000000000001070 <_Z3barv@plt>: 1070: f3 0f 1e fa endbr64 1074: f2 ff 25 55 2f 00 00 bnd jmpq *0x2f55(%rip) # 3fd0 <_Z3barv> 107b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1) Disassembly of section .text: 0000000000001169 <main>: int main() { 1169: f3 0f 1e fa endbr64 116d: 55 push %rbp 116e: 48 89 e5 mov %rsp,%rbp bar(); 1171: e8 fa fe ff ff callq 1070 <_Z3barv@plt> foo(); 1176: e8 e5 fe ff ff callq 1060 <_Z3foov@plt> } 117b: b8 00 00 00 00 mov $0x0,%eax 1180: 5d pop %rbp 1181: c3 retq 1182: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1) 1189: 00 00 00 118c: 0f 1f 40 00 nopl 0x0(%rax)
참고로 위 코드는 전체 objdump 로 출력된 부분에서 설명에서 필요한 부분만 잘라낸 것입니다. 나머지 부분들이 무슨 역할을 하는지는 다음 강의에서 살펴볼 예정입니다.
아무튼 흥미롭게도, 이전에 정적으로 링크했을 경우와는 다르게 foo 나 bar 의 내용이 전혀 없음을 알 수 있습니다. foo 나 bar 의 내용이 없는데 그러면 main 은 foo 와 bar 함수를 어떻게 호출하고 있을까요?
신기하게도
bar(); 1171: e8 fa fe ff ff callq 1070 <_Z3barv@plt> foo(); 1176: e8 e5 fe ff ff callq 1060 <_Z3foov@plt>
위와 같이 foo 나 bar 을 직접 호출하는 대신에 (어차피 호출할 수 도 없습니다.), PLT 섹션에 있는 foo@plt 와 bar@plt 를 호출하고 있습니다. 그렇다면 이들은 어떻게 정의되어 있을까요?
0000000000001060 <_Z3foov@plt>: 1060: f3 0f 1e fa endbr64 1064: f2 ff 25 5d 2f 00 00 bnd jmpq *0x2f5d(%rip) # 3fc8 <_Z3foov> 106b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1) 0000000000001070 <_Z3barv@plt>: 1070: f3 0f 1e fa endbr64 1074: f2 ff 25 55 2f 00 00 bnd jmpq *0x2f55(%rip) # 3fd0 <_Z3barv> 107b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
흥미롭네요. jmpq *0x2f5d(%rip) 이 명령어에 의미는, rip + 0x2f5d 위치에 써져 있는 주소값으로 점프해라 라는 의미 입니다. 위 경우 rip + 0x2f5d 가 0x3FC8 이므로 0x3FC8 의 위치에 무엇이 써져 있는지 살펴 보아야 겠습니다. 이를 위해서 objdump 에 -s 를 주고 실행해보면 모든 섹션들의 데이터를 볼 수 있습니다.
$ objdump -s main ... (생략) ... Contents of section .got: 3fb0 a03d0000 00000000 00000000 00000000 .=.............. 3fc0 00000000 00000000 30100000 00000000 ........0....... 3fd0 40100000 00000000 00000000 00000000 @............... 3fe0 00000000 00000000 00000000 00000000 ................ 3ff0 00000000 00000000 00000000 00000000 ................
와 같이 나옴을 알 수 있습니다. 여기서 0x3FC8 부분에 무엇이 써져 있는지 보면 0x1030 임을 알 수 있죠 (리틀 엔디안 임을 감안해서!). 다시 말해 위 문장은 jmpq 0x1030 과 동일한 의미 입니다. 마찬가지로 bar 부분을 보면 0x3FD0 에 써져 있는 주소값으로 점프하라는 의미 인데, 해당 부분에는 0x1040 이 쓰여 있습니다. 따라서 main 에서 bar@plt 를 호출하게 되면 0x1040 으로 점프하게 됩니다.
그렇다면 0x1040 에는 뭐가 있을까요?
0000000000001020 <.plt>: 1020: ff 35 92 2f 00 00 pushq 0x2f92(%rip) # 3fb8 <_GLOBAL_OFFSET_TABLE_+0x8> 1026: f2 ff 25 93 2f 00 00 bnd jmpq *0x2f93(%rip) # 3fc0 <_GLOBAL_OFFSET_TABLE_+0x10> 102d: 0f 1f 00 nopl (%rax) 1030: f3 0f 1e fa endbr64 1034: 68 00 00 00 00 pushq $0x0 1039: f2 e9 e1 ff ff ff bnd jmpq 1020 <.plt> 103f: 90 nop 1040: f3 0f 1e fa endbr64 1044: 68 01 00 00 00 pushq $0x1 1049: f2 e9 d1 ff ff ff bnd jmpq 1020 <.plt> 104f: 90 nop
흥미롭네요. 스택에 1 을 푸시하고 PLT 맨 위로 점프합니다. 그리고 다시 스택에 0x2f92(%rip) 를 푸시하고, *0x2f93(%rip) 로 점프합니다. 흥미롭네요. 도대체 뭔 일이 벌어지고 있는 것일까요? 도대체 bar 함수는 어디에서 실행되는 것일까요?
일단 한 번 아래 그림으로 정리 해보도록 하겠습니다.
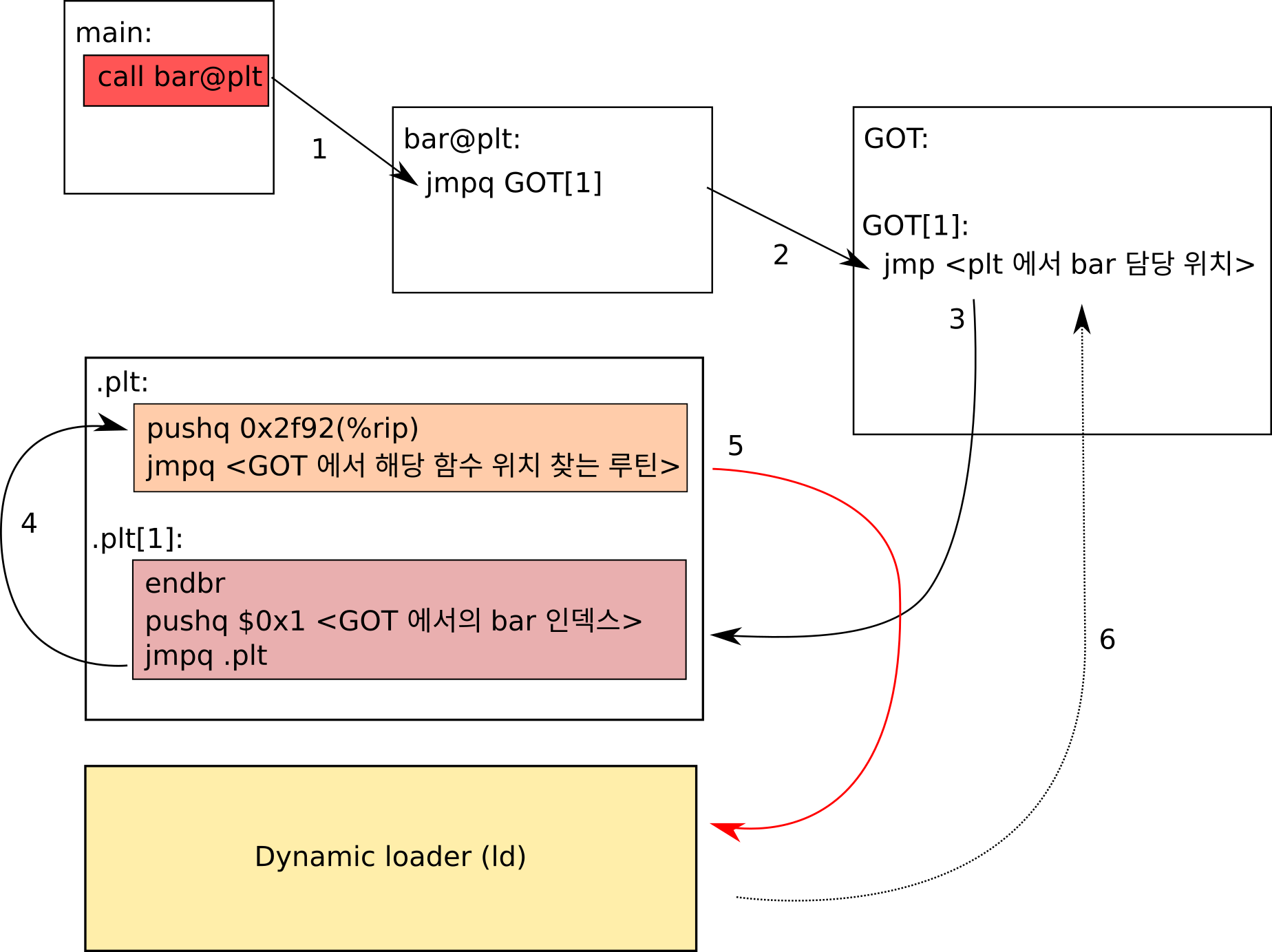
가장 먼저 main 함수에서 공유 라이브러리 안에 있는 bar 함수를 호출합니다. 만일 bar 가 정적으로 링크된 라이브러리의 함수였다면 그냥 bar 가 정의된 위치를 호출하였겠죠. 하지만 공유 라이브러리의 경우 프로그램 어디에 위치 되었는지 알 수 없기 때문에 해당 함수를 직접 호출하는 것은 불가능 합니다.
따라서 어떤 방식을 취하게 되냐면 GOT (Global Offset Table) 라는 이름의 데이터 테이블을 프로그램 내부에 만든 다음에, 실제 함수들의 주소값을 이 테이블에 적어놓습니다. 그리고 우리가 함수를 호출하게 되면 해당 함수의 실제 위치를 이 테이블을 통해서 알아내게 됩니다.
예를 들어서 bar 함수가 GOT 에 두 번째 위치에 (GOT[1]) 써져 있다고 해봅시다. 그렇다면 그냥 call *GOT[1] 을 하게 되면 bar 함수를 호출할 수 있는 것입니다. 하지만 처음 프로그램을 갓 실행한 상태에서는 bar 함수가 어디에 위치할 지 알 수 없기 때문에 GOT[1] 에 bar 의 위치를 써 넣을 수 없습니다. 따라서 이를 위해서 처음에 GOT[1] 에 bar 의 실제 위치를 알아낸 후 해당 주소값을 GOT[1] 자리에 덮어 씌우는 함수 를 써 놓는 것입니다.
자 그렇다면 위 그림을 살펴봅시다.
먼저
main에서 진짜bar을 호출 시켜주는 함수인bar@plt를 호출합니다.bar@plt는GOT에서bar에 해당하는 엔트리인GOT[1]로 점프합니다.이 경우
bar가 처음 호출된 상황 이므로GOT[1]에는bar의 주소값이 들어 있지 않고 PLT 안에 정의된 bar 의 실제 위치를 찾는 루틴 으로 점프합니다. 참고로 PLT 는 Procedure Linkage Table 의 약자로 링크 타임 시에 위치를 알 수 없는 함수들의 위치를 찾아내주는 루틴들을 모아놓은 테이블 입니다.bar의GOT상의 위치는 1 이므로, 스택에 1 을 푸시한 뒤, 해당 심볼의 위치를 찾는 루틴 으로 점프합니다. 해당 루틴은 보통 PLT 맨 상단에 정의되어 있습니다.해당 루틴에선 곧바로
Dynamic Loader라이브러리 코드로 점프합니다. 이제 이 라이브러리에서 우리가 원하는 bar 함수가 도대체 어디에 정의되어 있는지 찾게 됩니다. 참고로 왜 그냥 4 번을 거칠 필요 없이 3 에서 5 로 바로 점프할 수 없냐 궁금하실 수 있는데 일단 (1) 동적 로더 (Dynamic loader) 자체도 공유 라이브러리이고 (2)GOT의 위치를 전달해야 하기 때문 입니다.참고로 리눅스의 경우
ld.so라는 이름의 동적 로더를 사용하고 있습니다.ld.so는 필요로 하는 심볼을 찾은 뒤 해당GOT위치를 업데이트 합니다. 따라서GOT[1]에는 이제bar의 실제 주소값이 들어가게 됩니다. 어떤 로더를 사용할지는 프로그램의interop섹션에 정의되어 있습니다.마지막으로
bar함수로 점프합니다.
자 그렇다면 만약에 두 번째로 bar 을 호출하게 된다면 어떨까요?
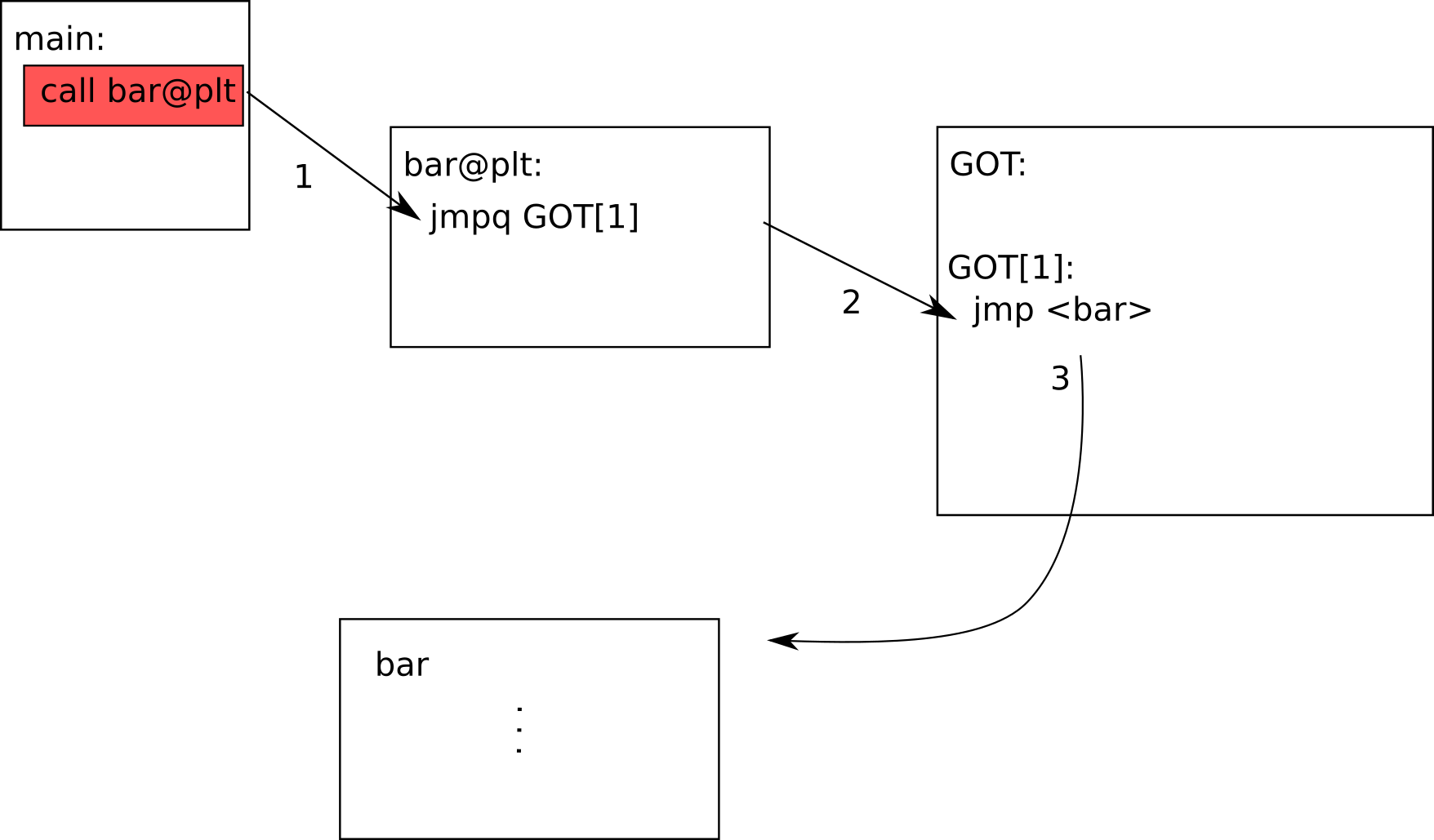
이제는 GOT[1] 안에 bar 의 주소값이 들어 있기 때문에 복잡한 루틴 필요 없이 그냥 바로 bar 을 호출할 수 있게 됩니다.
이와 같이 함수가 실행 될 때 GOT 엔트리에 등록되는 방식을 lazy binding 이라고 합니다.
Lazy binding 의 장점으로는 만약에 bar 이 프로그램 상에서 한 번도 호출되지 않았더라면 굳이 bar 의 위치를 찾을 필요가 없습니다. 동적 라이브러리에서 사용하는 함수의 위치를 찾는 작업은 결코 공짜가 아니기에 시간을 절약할 수 있습니다.
그 대신 lazy binding 의 문제로는 해당 함수를 첫 번째로 실행하는 시점에서 많은 시간이 소요된다는 것입니다. 따라서 프로그램이 실행 중에 뜨문 뜨문 렉이 걸리는 상황이 발생할 수 있죠. 차라리 프로그램 시작 시에 모든 동적으로 바인딩 되는 심볼들을 찾아버리는 것이 오히려 나을 수 도 있습니다.
따라서 프로그램에 따라서 ld 로 하여금 lazy binding 을 하지 않고 아예 프로그램 시작 시에 모든 심볼들을 GOT 에 등록하라고 설정할 수 도 있습니다. (예를 들어서 포토샵을 실행해보신 분들은 아시겠지만 프로그램 시작 시 꽤 오래걸리는 것을 알 수 있죠? 이게 대부분 공유 라이브러리에서 사용되는 함수들을 찾느라 걸리는 시간 입니다.)
동적 링킹 방식의 재배치
그렇다면 마지막으로 동적 링킹되는 라이브러리에서 재배치가 어떤 식으로 이루어지는지 살펴봅시다. 이전에 foo.cc 의 내용을 다시 가져오면
// foo.cc #include "bar.h" int x = 1; int foo() { bar(); x++; return 1; }
컴파일 시에 아래와 같이 구성됩니다.
objdump -Sr foo.o foo.o: file format elf64-x86-64 Disassembly of section .text: 0000000000000000 <_Z3foov>: #include "bar.h" int x = 1; int foo() { 0: f3 0f 1e fa endbr64 4: 55 push %rbp 5: 48 89 e5 mov %rsp,%rbp bar(); 8: e8 00 00 00 00 callq d <_Z3foov+0xd> 9: R_X86_64_PLT32 _Z3barv-0x4 x ++; d: 48 8b 05 00 00 00 00 mov 0x0(%rip),%rax # 14 <_Z3foov+0x14> 10: R_X86_64_REX_GOTPCRELX x-0x4 14: 8b 00 mov (%rax),%eax 16: 8d 50 01 lea 0x1(%rax),%edx 19: 48 8b 05 00 00 00 00 mov 0x0(%rip),%rax # 20 <_Z3foov+0x20> 1c: R_X86_64_REX_GOTPCRELX x-0x4 20: 89 10 mov %edx,(%rax) return 1; 22: b8 01 00 00 00 mov $0x1,%eax } 27: 5d pop %rbp 28: c3 retq
먼저 bar 함수를 호출하는 부분부터 봅시다. 당연히도 R_X86_64_PLT32 방식으로 bar 을 재배치 해야 한다고 명시하고 있습니다. R_X86_64_PLT32 의 경우 재배치 주소 계산 방식이 L + A - P 입니다. 여기서 A 와 P 는 기존과 동일하고 L 은 프로시져 링킹 테이블 (PLT) 의 주소값 입니다.
그 이유는 당연히도 bar 을 직접 호출하는 것이 아니라 PLT 에 등록되어 있는 bar 을 호출해주는 루틴을 호출해야 하기 때문에 (bar@plt) PLT 섹션의 위치 기준으로 계산되어야 하기 때문입니다.
그렇다면 전역 변수인 x 는 어떨까요? 이 경우 R_X86_64_REX_GOTPCRELX 형태의 재배치 방식을 사용하는데, 이 경우 계산하는 방식은 G + GOT + A - P 입니다. 여기서 G 는 GOT 안에서 해당 심볼 까지의 오프셋을 말하고, GOT 의 경우 GOT 테이블 자체의 오프셋을 의미합니다. 쉽게 말해서 G + GOT 가 프로그램 시작 부터 GOT 안에 정의 되어 있는 해당 심볼 까지의 오프셋이라 보시면 됩니다.
변수의 경우 함수와는 다르게 PLT 를 사용할 필요가 없습니다. 그냥 해당 변수를 GOT 안에 위치시키면 되기 때문이죠. 따라서 위 처럼 R_X86_64_REX_GOTPCRELX 재배치 방식을 사용해서 GOT 안에 전역 변수를 정의하는 것을 알 수 있습니다. 생각보다 간단하죠!
사실 여기 까지 다룬 재배치 방식 말고도 몇 가지 더 다른 재배치 방식들이 있습니다. 하지만 여기서 다룬 내용들을 모두 이해했다면 다른 방식들도 큰 무리 없이 이해하실 수 있을 것이라 봅니다. 이 부분에 대해서 더 공부하고 싶으신 분들은 x86-64 ABI 를 읽어보시기 바랍니다.
마무리
이렇게 C++ 에서 링킹이 어떤 식으로 구성되는지 살펴보았습니다. 생각보다 링커에서 정말 많은 일을 하고 있는 것을 알 수 있죠. 물론 아직 모든 궁금증이 해결 된 것은 아닙니다. 앞서 컴파일 된 프로그램을 objdump 로 살펴보았을 때 우리가 작성한 코드 말고도 수 많은 다른 섹션들이 있는 것을 확인할 수 있었을 것입니다. (__libc_csu_init, __do_global_dtors_aux, register_tm_clones 등등 말이죠)
도대체 얘네들은 어디서 온 녀석이고 무슨 일들을 하는 것인지, 다음 강의에서 살펴보도록 하겠습니다.

댓글을 불러오는 중입니다..