모두의 코드
씹어먹는 C++ - <5 - 3. 연산자 오버로딩 프로젝트 - N 차원 배열>
이번 강좌에서는
C++ 스타일의 캐스팅 (
static_cast등등)디폴트 인자 (default argument)
N차원 배열의 제작반복자(iterator)
에 대해 다룹니다.

이번 강좌의 내용은 C++ 을 처음 배우는 분들에게는 이해하기 버거울 수 있습니다. 만일 내용이 도저히 이해가 되지 않는 다면, 이전 연산자 오버로딩 강좌 두 개를 꼼꼼히 다시 읽어보신 다음에, 이 강좌 앞부분 (C++ 스타일의 캐스팅) 만 읽고 넘어가셔도 좋습니다. 하지만 C++ 을 어느 정도 배웠고 복습하시는 차원에서 보시는 분들은 꼭 읽어보시기 바랍니다.
안녕하세요 여러분~ 지난번 강좌의 생각해보기는 잘 해보셨나요? 아마도 꽤나 어려웠을 것이라 생각합니다. 사실 N 차원 배열을 만드는 것 까지는 하셨을 지 모르겟지만, N 차원 배열을 [] 를 이용해서 원소에 접근하는 것을 구현하는 일은 상당한 수준의 아이디어가 필요하기 마련이지요.
이번 강좌에서는 이 N 차원 배열 만들기 프로젝트를 진행하면서, C++ 여러 라이브러리에서 주요하게 사용되는 몇 가지 아이디어들을 살펴보고 갈 것입니다.
본격적으로 프로젝트에 들어가기에 앞서 C++ 에 또 새롭게 추가된 한 가지 내용을 살펴보도록 하겠습니다.
C++ 스타일의 캐스팅
기존의 C 언어에서는, 캐스팅은 크게 2 가지 방법으로 발생하였습니다. 하나는 그냥 컴파일러에서 알아서 캐스팅 하는 암시적(implicit) 캐스팅과, 우리가 직접 이러이러 하게 캐스팅 하라고 지정하는 명시적(explicit) 캐스팅이 있었지요.
암시적 캐스팅의 경우 int 와 double 변수와의 덧셈을 수행할 때, int 형 변수가 자동으로 double 변수로 캐스팅 되는 것과 같은 것을 말하고, 명시적 캐스팅의 경우 예를 들어 void * 타입의 주소를 특정 구조체 포인터 타입의 주소로 바꾼다던지 등의 캐스팅이 있습니다.
이 때, 명시적 캐스팅은 다음과 같이 수행되었지요.
ptr = (Something *)other_ptr; int_variable = (int)float_variable;
와 같이 말이지요. 즉, 괄호 안에 원하는 타입을 넣고 변환을 수행한 것입니다. 하지만 이러한 방식을 사용하다 보니까 프로그래머들 사이에서 몇 가지 문제점들을 발견하였습니다.
먼저 위와 같은 타입 캐스팅의 경우 말도 안되는 캐스팅에 대해서 컴파일러가 오류를 발생시키지 않습니다. 따라서 프로그래머의 실수에 취약합니다.
뿐만 아니라 괄호 안에 타입을 넣는 방식으로 변환을 수행하는 탓에, 코드의 가독성이 떨어지게 됩니다. 즉,
function((int)variable);
와 같이 함수 호출에도 괄호를 사용하는데, 괄호가 너무 많아지게 된다면 읽는 사람이나 코드를 유지보수하는 사람 입장에서 여러모로 불편합니다. 뿐만 아니라 우리가 캐스팅을 하는데에는 여러가지 이유가 있기 마련인데, 위와 같은 C 형식 캐스팅에서는 읽는이가 그 캐스팅의 의미를 명확하게 알 수 없습니다.
하지만 C++ 에서는 다음과 같은 4 가지의 캐스팅을 제공하고 있습니다.
static_cast: 우리가 흔히 생각하는, 언어적 차원에서 지원하는 일반적인 타입 변환const_cast: 객체의 상수성(const) 를 없애는 타입 변환. 쉽게 말해const int가int로 바뀐다.dynamic_cast: 파생 클래스 사이에서의 다운 캐스팅 (→ 정확한 의미는 나중에 다시 배울 것입니다)reinterpret_cast: 위험을 감수하고 하는 캐스팅으로 서로 관련이 없는 포인터들 사이의 캐스팅 등
이 때 이러한 캐스팅을 사용하는 방법은 다음과 같습니다.
(원하는 캐스팅 종류)<바꾸려는 타입>(무엇을 바꿀 것인가?)
예를 들어서, static_cast 로 float 타입의 float_variable 이라는 변수를 int 타입의 변수로 타입 변환하기 위해서는;
static_cast<int>(float_variable);
이렇게 해주시면 됩니다. 이는 C 언어에서
(int)(float_variable)
을 한 것과 동일한 문장 입니다. 사실 현재까지 배운 내용 정도 에서는, static_cast 만 사용하지 나머지 캐스팅들은 별로 신경 안쓰셔도 됩니다. 여러분이 C 언어에서 수행하였던 대부분의 아무런 문제없는 캐스팅들은 모두 static_cast 로 해주시면 됩니다. 강좌를 진행하면서 나머지 캐스팅들을 어떠한 상황에서 사용하는지 차근 차근 알아보도록 할 것입니다.
N 차원 배열 만들기
N 차원 배열을 구현하는 방법은 크게 두 가지 방법이 있다고 생각합니다. 사용자가 원하는 배열을 arr[x1][x2]...[xn] 이라고 해본다면, 첫 번째 방법은 말 그대로 x1 * x2 * ... * xn 크기의 일 차원 배열을 할당한 뒤에 접근할 때 정확한 위치를 찾아주는 방법이지요. 이러한 방식으로 구현한다면 메모리도 정확히 필요한 만큼만 사용할 수 있기에 좋은 방법이라고 생각합니다.이 방법으로 한번 여러분들이 직접 구현해 보시기 바랍니다.
제가 이 N 차원 배열을 구현하는 프로젝트에서 사용할 아이디어는, 이전에 2 차원 배열의 동적할당을 수행하면서 얻은 아이디어와 비슷합니다. 예전에 동적으로 2 차원 배열을 구현할 때 다음과 같이 구성하였습니다. (참고로 아래 코드에서 할당한 2 차원 배열의 크기는 arr[x1][x2] 입니다)
int** arr; arr = new int*[x1]; for (int i = 0; i < x1; i++) arr[i] = new int[x2];
즉 더블 포인터 arr 을 정의한 뒤에, arr 에 int* 타입의 x1 크기의 1 차원 배열을 먼저 할당한 다음에, 이 int* 배열의 각 원소에 대해서 또 x2 크기의 1 차원 배열을 모두 할당한 것이지요. 이와 같은 형태를 그림으로 표현하자면 다음과 같습니다.
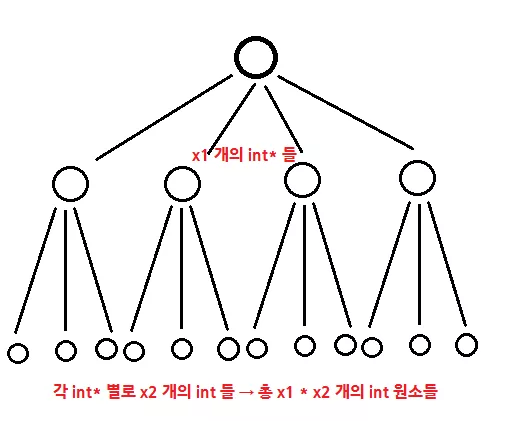
위와 같이 문어발 형식으로 맨 처음에는 x1 개의 int* 배열을 생성한 뒤에, 각 int* 에 대해서 x2 개의 int 배열을 만들게 된다면, 전체적으로 볼 때 마치 int arr[x1][x2] 를 한 것과 정확히 동일한 효과를 낼 수 있게 됩니다. 하지만 이와 같은 방식의 문제점으로는 원래 int arr[x1][x2] 를 하게 된다면 정확히 x1 * x2 만큼의 메모리만 잡아먹게 되지만, 이 방법을 할 경우, 포인터 자체가 잡아먹는 크기 때문에 x1 * x2 + x1 + 1 만큼의 메모리를 잡아먹게 된다는 뜻입니다.
하지만 위 방식의 좋은 점은, 메모리가 허용하는 한 크기가 매우 매우 큰 배열도 생성할 수 있다는 점입니다. 첫 번째 방식의 경우 전체 배열의 원소 수가 int 크기를 넘어가게 된다면, 따로 큰 수의 정수를 다룰 수 있는 라이브러리를 사용해서 메모리를 동적으로 할당해주어야 할 것입니다. 하지만, 제가 이 N 차원 배열 클래스에서 사용할 방식의 경우, 전체 원소 수가 아니라, 한 차원의 수가 int 크기만 넘어가지 않으면 됩니다. 다시 말해, (int 크기) * (int 크기) * ... * (int 크기) 개의 원소를 사용할 수 있으며, 아마 이 정도 크기는 왠만한 사이즈의 프로젝트에서는 충분할 것입니다. 3 차원 배열의 경우 가능한 최대 원소 개수가 2 의 96승, 즉 79228162514264337593543950336 개나 됩니다.
그런데 여기서 한 가지 문제점이 무엇이냐면, 우리가 만들어야 할 배열은 정해진 상수 차원의 배열이 아니라, N 차원의 배열이라는 뜻입니다. 만일 3 차원 배열을 만들었다면 int*** 을 이용하였을 것이고 4 차원 배열은 int **** 을 이용하였을 터인데 (물론 불편하기는 하지만, 쉽게 생각하자면 말입니다.) N 차원 배열의 경우 N 개의 * 들이 들어간 포인터를 정의할 수 없는 터입니다.
하지만 관점을 바꾸어서 조금만 생각해보면 이 문제는 손쉽게 해결할 수 있음을 알 수 있습니다. 위에서 포인터를 사용하는 것이 단순히 다음 레벨의 배열들을 가리키기 위함이라면, 굳이 N 포인터를 사용하지 않고도 만들 수 있기 때문입니다.
struct Address { int level; void* next; };
이 생각을 바탕으로 하나의 작은 구조체를 만들어 보자면 위와 같이 Address 라는 구조체를 생각해봅시다.
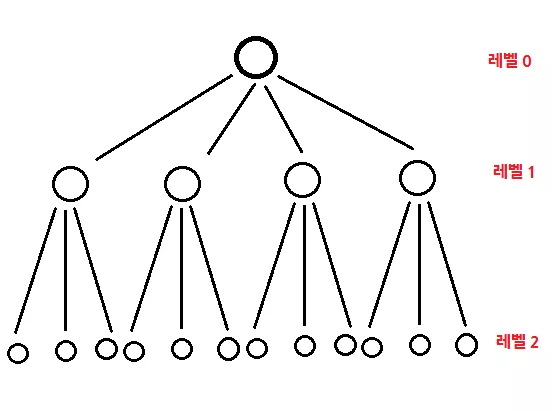
위와 같이 각각의 행들을 한 개의 레벨이라고 생각했을 때, 맨 처음에 우리가 정의하던 int ** 변수는 0 레벨, 그 다음에 int ** 가 가리키던 int * 배열들은 1 레벨, 그리고 실제 int 형 데이터가 들어가 있는 곳은 2 레벨이라고 생각할 수 있습니다. 그런데 Address 구조체를 도입한다면 굳이 int ** 등으로 귀찬게 할 필요 없이 모두 void * 포인터 하나로 정리할 수 있습니다.
이 것이 어떻게 가능하다면, top 이라는 Address 객체를 도입을 합니다. 이 top 은 위 그림에서 맨 위의 레벨 0 에 해당하며 (그래서 이름도 역시 top 입니다) 따라서 top 의 level 값은 0 이 됩니다. 그렇다면 이 top 의 next 에는 무엇이 들어가게 될까요? 이미 예상하겠지만, 레벨이 1 인 Address 배열의 시작 주소가 들어가게 됩니다. 그럼, 이 top 이 가리키고 있는 Address 배열의 각각 원소들의 level 은 당연히 1 이 되겟고, 이들의 next 에는 무엇이 들어갈까요. 예상했던 대로, 이번에는 Address 배열이 아닌, int 배열의 시작 주소가 들어가겠지요. (왜냐하면 2 차원 배열이기 때문이죠!. 실질적으로 데이터는 여기에 보관이 됩니다)
여기서 좋은 점은 포인터라는 것이 타입의 상관없이 모두 void * 으로 값을 보관할 수 있으므로 필요할 때에만 적당한 포인터 타입으로 변환하면 됩니다. 정리해보자면, N 차원 배열이라고 할때 Address 들은 총 0 레벨 부터 N - 1 레벨 까지 생성되며, N - 1 레벨의 경우 next 에 실제로 보관할 데이터에 해당하는 배열(여기서는 int) 의 시작 주소값이 들어가게 되고, 나머지 0 부터 N - 2 레벨 까지는 그 다음 레벨의 Address 배열의 시작 주소값이 들어가게 됩니다.
마지막으로 이해가 가시지 않는 분들을 위해 3차원 배열의 경우 어떻게 이 방법으로 구성할 수 있는지 예시 그림을 첨부하였습니다.
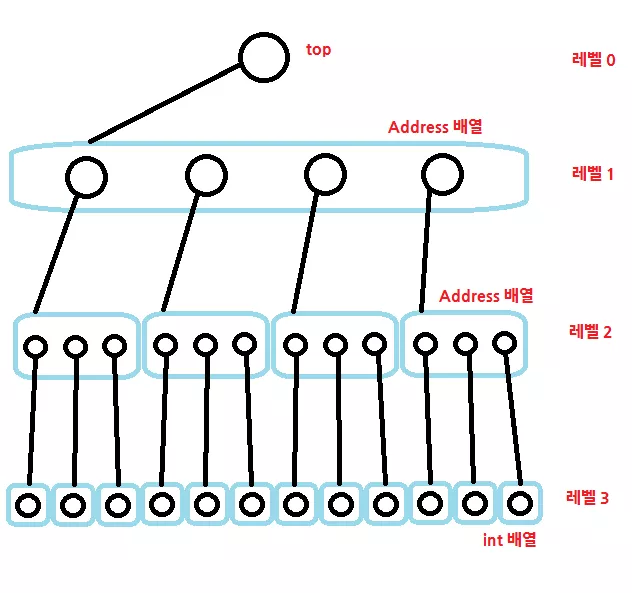
위 그림은 3차원 배열일 때 어떻게 구성할 수 있는지 나타낸 그림입니다. 그림에도 잘 표현되어 있지만, 검은색 선은 next 가 가리키고 있는 것을 의미하고, 파란색 테두리는 하나의 배열을 의미하게 됩니다. 마찬가지로 0 레벨의 next 는 1 레벨의 Address 배열의 시작 주소값을 가리키고 있고, 1 레벨의 Address 들의 next 는 각각 2 레벨의 Address 배열의 시작 주소값을 가리키고 있습니다. 이 때 3 차원 배열이므로, (3 - 1) 레벨인 2 레벨의 Address 들의 next 들은 0, 1 레벨들과는 다르게 int 배열의 시작 주소값을 가리키게 됩니다.
이러한 레벨 방식을 도입해서 처리하는 이유는 각 레벨에서의 배열 크기가 모두 다를 수 있기 때문입니다. 예를 들어서, arr[3][2][1] 을 했을 경우, 1 레벨의 배열 크기가 3, 2 레벨의 배열 크기가 2, 그리고 마지막 int 배열 (레벨 3에 해당) 크기가 1 이 되면 됩니다. 위 그림의 경우 arr[4][3][1] 을 나타낸 것이라 볼 수 있겠지요.
이러한 아이디어를 바탕으로 일단 우리의 N 차원 Array 배열의 클래스를 대략적으로 설계해보도록 합시다.
class Array { const int dim; // 몇 차원 배열인지 int* size; // size[0] * size[1] * ... * size[dim - 1] 짜리 배열이다. public: Array(int dim, int* array_size) : dim(dim) { size = new int[dim]; for (int i = 0; i < dim; i++) size[i] = array_size[i]; } };
일단 우리의 Array 배열에 들어가야 할 중요한 정보로 '몇 차원' 배열인지에 대한 정보와, 각 차원에서의 크기 정보를 반드시 포함하고 있어야만 할것입니다. 따라서, '몇 차원' 인지는 dim 에 아예 상수값으로 저장하도록 하고 (반드시 상수로 정할 필요는 없습니다만, dim 을 상수로 정한 것은 외부 사용자들에게 한 번 Array 의 차원을 정하면 바꿀 수 없다는 것을 의미합니다. 물론 여러분들이 원하신다면 굳이 상수로 안하는 대신에 배열의 차원을 조절해주는 resize 같은 함수를 추가해주어야 겠지요), size 배열에 각 차원애 대한 정보를 가지게 하였습니다.
그런데 여기서 중요한 것이 빠진것 같습니다. 바로 실질적으로 데이터를 보관하는 부분인데요, 앞에서도 설명하였듯이 우리의 거대한 N 차원 배열은 마치 거대한 나무 처럼 가느다란 줄기로 부터 시작해서 엄청나게 큰 뿌리로 퍼지는 모습입니다. 하지만 이 거대한 배열을 가리키게 위해서 Array 에서 필요한 것은 단 하나, 바로 맨 상단의 시작점일 뿐이지요. 이 시작점은 Address * 타입으로, 이를 top 이라고 부르기로 하였습니다. 따라서 최종적으로 Array 에 필요한 data 멤버들은 다음과 같습니다.
class Array { const int dim; // 몇 차원 배열인지 int* size; // size[0] * size[1] * ... * size[dim - 1] 짜리 배열이다. Address* top; public: Array(int dim, int* array_size) : dim(dim) { size = new int[dim]; for (int i = 0; i < dim; i++) size[i] = array_size[i]; } };
아 물론, Address 라는 새로운 구조체를 도입하였기 때문에 Address 의 정의 자체도 넣어야만 합니다. 한 가지 재미있는 점은 클래스 안에도 클래스를 넣을 수 있다는 사실인데, 외부에서 우리 Array 배열이 내부적으로 어떻게 작동하는지 공개하고 싶지 않고, 또 내부 정보에 접근하는 것을 원치 않기 때문에 Array 안에 Address 구조체를 넣어 버리겠습니다. (참고로 C++ 에서 구조체는 모든 멤버 함수, 변수가 디폴트로 public 인 클래스라고 생각하시면 됩니다)
class Array { const int dim; // 몇 차원 배열인지 int* size; // size[0] * size[1] * ... * size[dim - 1] 짜리 배열이다. struct Address { int level; // 맨 마지막 레벨(dim - 1 레벨) 은 데이터 배열을 가리키고, 그 위 상위 // 레벨에서는 다음 Address 배열을 가리킨다. void* next; }; Address* top; public: Array(int dim, int* array_size) : dim(dim) { size = new int[dim]; for (int i = 0; i < dim; i++) size[i] = array_size[i]; } };
따라서 최종적으로 위와 같은 모습이 됩니다.
자 그러면 이제 본격적으로 top 을 시작으로 N 차원 배열을 생성해보도록 하겠습니다. 위의 그림과 같은 구조를 구현하기 위해서는 이전에 동적으로 2 차원 배열을 생성하였을 때 처럼 for 문으로 간단히 수행할 수 있는 것이 아닙니다. 왜냐하면 일단 for 문으로 하기 위해서는 몇 중 for 문을 사용할지 컴파일 시에 정해져야 하는데, 이 경우 N 차원인 임의의 차원이므로 그럴 수 없기 때문입니다.
하지만 이와 같은 문제를 해결하는 아주 좋은 아이디어가 있는데 바로 재귀 함수를 이용하는 것입니다. 재귀 함수를 구성하기 위해서는 다음과 같은 두 가지 스텝만 머리속으로 생각하고 있으면 됩니다.
함수에서 처리하는 것, 즉 현재 단계에서 다음 단계로 넘어가는 과정은 무엇인가?
재귀 호출이 종료되는 조건은 무엇인가?
일단 우리는 두 번째 질문에 대한 해답을 이미 알고 있습니다. 재귀 함수 호출이 종료되기 위한 조건은 바로 현재 처리하고 있는 Address 배열의 레벨이 (dim - 1) 이면 됩니다. 즉, Address 배열의 레벨이 (dim - 1) 이면, 이 배열의 원소들 (즉 (dim - 1) 레벨들의 Address 들) 의 next 에는 int 배열의 데이터가 들어가게 재귀 호출이 끊나게 되지요.
그렇다면 첫 번째 질문에 대한 답, 즉 현재 단계에서 다음 단계로 넘어 가는 과정은 무엇일까요? 이 역시 사실 간단합니다. 현재 n 레벨의 Address 배열이라면, 이들의 next 에 다음 레벨인 n + 1 레벨의 Address 배열을 지정해주고, 또 이 각각의 원소에 대해 처리하도록 하면 되는 것입니다.
따라서 이 생각들을 정리하면 다음과 같은 코드를 짤 수 있습니다.
// address 를 초기화 하는 함수이다. 재귀 호출로 구성되어 있다. void initialize_address(Address *current) { if (!current) return; if (current->level == dim - 1) { // 두 번째 질문 (종료 조건) current->next = new int[size[current->level]]; return; } current->next = new Address[size[current->level]]; for (int i = 0; i != size[current->level]; i++) { // 다음 단계로 넘어가는 과정 (static_cast<Address *>(current->next) + i)->level = current->level + 1; initialize_address(static_cast<Address *>(current->next) + i); } }
위 initialize_address 함수는 인자로 들어온 current 를 처리하고 그 다음 단계로 넘어가도록 합니다. 맨 처음의 if(!current) 부분은 단순히 current 가 NULL 일 때 예외적으로 처리하는 부분이니까 무시하도록 하고, 두 번째 if 문은 위에서 설명한 '종료 조건' 이 됩니다. 이 재귀 호출이 끝나기 위한 조건으로 현재 처리하고 있는 Address 의 레벨이 dim - 1 일 때, 이들의 next 에는 Address 배열이 아닌 int 배열의 시작 주소가 들어가게 됩니다.
반면에 종료 조건에 해당하지 않는 경우 initialize_address 함수에서 어떻게 처리하는지 볼까요. 일단;
current->next = new Address[size[current->level]];
를 통해서 current 의 next 에 크기가 size [current->level] 인 새로운 시작 주소값을 만들어주고 있습니다. 이 때 왜 배열의 크기가 size [current->level] 인지는 여러분도 잘 아실 것이라 생각합니다. 예를 들어서 arr[3][4][5] 의 경우 current 가 0 레벨이라면 next 에 만드는 배열의 크기는 3, 1 레벨이라면 4, 2 레벨이라면 5 가 되는 것과 같은 이치 입니다.
이렇게 Address 배열을 만들게 된다면, 이 각각의 원소들에 대해서도 종료 조건에 도달하기 전까지 동일한 처리를 계속 반복해주어야만 하겠지요? 따라서 아래 처럼 for 문으로
for (int i = 0; i != size[current->level]; i++) { // 다음 단계로 넘어가는 과정 (static_cast<Address *>(current->next) + i)->level = current->level + 1; initialize_address(static_cast<Address *>(current->next) + i); }
새롭게 생성한 각각의 원소들에 대해 initialize_address 를 동일하게 수행하고 있습니다.
(static_cast<Address *>(current->next) + i)->level = current->level + 1;
위 처럼 그 current 의 next 가 가리키고 있는 원소들의 레벨 값을 다음 단계로 설정한 다음에
initialize_address(static_cast<Address *>(current->next) + i);
각각의 원소들에 대한 initialize_address 함수를 호출하게 됩니다. 참고로,
(static_cast<Address *>(current->next) + i)
라는 표현이 무슨 뜻인지는 C 언어를 충실히 배운 여러분이라면 무슨 의미인지 잘 알고 계실 것이라 생각합니다. (current->next 를 시작 주소로 하는 Address 배열의 i 번째 원소를 가리키는 포인터)
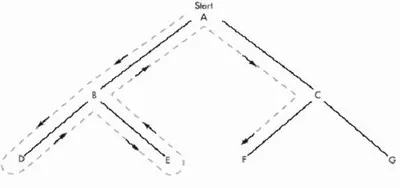
참고로 말하자면, 이러한 방식으로 함수를 재귀호출하게 된다면, 맨 위의 그림을 '깊이 우선 탐색' 하는 것과 동일합니다. (아래 그림 참조)
생성자를 만들었으므로, 소멸자도 비슷한 방식으로 만들어주면 됩니다. 다만, 소멸자의 경우 주의할 점이, 생성자는 '위에서 아래로' 메모리들을 점차 확장 시켜 나갔지만, 소멸자는 '아래에서 위로' 메모리를 점차 소멸시켜 나가야 된다는 점입니다. 물론, 이로 살짝 바꾸는 것은 별로 어려운 일이 아닙니다.
void delete_address(Address *current) { if (!current) return; for (int i = 0; current->level < dim - 1 && i < size[current->level]; i++) { delete_address(static_cast<Address *>(current->next) + i); } if (current->level == dim - 1) { delete[] static_cast<int *>(current->next); } delete[] static_cast<Address *>(current->next); }
위와 같이 delete_address 함수를 생각해 볼 수 있습니다. (여러분들이 한 번 직접 생각해보세요) 마지막 레벨에서는 int 들이 정의되어 있기 때문에 int* 로 캐스팅해서 delete 를 해야 하고, 그 전까지는 Adress 들을 delete 해야 겠죠.
이들을 조합해서, 우리의 Array 클래스의 생성자를 수정해보도록 합시다.
Array(int dim, int *array_size) : dim(dim) { size = new int[dim]; for (int i = 0; i < dim; i++) size[i] = array_size[i]; top = new Address; top->level = 0; initialize_address(top); } Array(const Array &arr) : dim(arr.dim) { size = new int[dim]; for (int i = 0; i < dim; i++) size[i] = arr.size[i]; top = new Address; top->level = 0; initialize_address(top); // 내용물 복사 copy_address(top, arr.top); } void copy_address(Address *dst, Address *src) { if (dst->level == dim - 1) { for (int i = 0; i < size[dst->level]; ++i) static_cast<int *>(dst->next)[i] = static_cast<int *>(src->next)[i]; return; } for (int i = 0; i != size[dst->level]; i++) { Address *new_dst = static_cast<Address *>(dst->next) + i; Address *new_src = static_cast<Address *>(src->next) + i; copy_address(new_dst, new_src); } } ~Array() { delete_address(top); delete[] size; }
위 두개는 Array 의 기본 생성자와 복사 생성자, 그리고 소멸자를 나타낸 것입니다. 재귀 함수의 시작으로 current 에 top 을 전달하였고, 이 top 을 시작으로 함수들이 쭈르륵 재귀 호출 되면서 거대한 N 차원 메모리 구조가 생성되거나 소멸 됩니다.
항상 유의할 점은 소멸자에서 동적으로 할당한 모든 것들을 정리해 주어야 한다는 점인데, 재귀 호출로 생성한 메모리 구조만을 소멸해야 되는 것이 아니라 size 역시 동적으로 할당한 것이므로 꼭 해제해 주어야만 합니다.
또한 복사 생성자에서 마찬가지로 트리 안에 모든 원소들을 복사해줘야만 합니다.
operator[] 문제
이제 생성을 하였는데, 문제는 어떻게 N 차원 배열의 각각의 원소에 접근하느냐 입니다. 우리의 클래스는 다른 복잡한 방법을 사용하지 않고 마치 진짜 배열을 다루던 것 처럼 [] 를 이용해서 원소에 접근하는 기능을 제공하고 싶습니다. 하지만 문제는 C++ 에는 1 개의 [] 를 취하는 연산자는 있어도 N 개의 [] 들을 취하는 연산자는 없다는 점입니다.
그렇다면, 여러개의 [] 들을 어떻게 처리하냐면 예를 들어 우리가
arr[1][2][3][4]
를 하였을 때, 제일 먼저 arr[1] 이 처리되며, 첫 번째 차원으로 1 을 선택했다는 정보가 담긴 어떠한 객체 T 를 리턴합니다. 그리고,
(T)[2][3][4]
가 수행이 되겠지요. 이 T 또한 operator[] 가 있어서, 두번째 차원으로 2 를 선택했다는 정보가 담긴 객체 T' 을 리턴합니다. 그렇다면 이제,
(T가 되겠고, 마찬가지로 계속 진행하게 된다면
T''
이 남게 됩니다. 우리는 이 T''' 가 int 타입임을 바라고 있지요. 그런데 도대체 이를 어떻게 구현해야 할까요?
일단 Array 가 아닌 새로운 타입의 객체를 만들어야 한다는 것만은 분명합니다. 왜냐하면, 만일 operator[] 가 Array& 타입이라면, 1 차원 Array 배열에 대해서
arr[1] = 3;
과 같은 문장은 말이 안되기 때문입니다. 그렇다고 해서 operator[] 가 int& 타입을 리턴할 수 도 없는 처지 입니다. 왜냐하면, 만일 int& 타입을 리턴하였을 경우에 1 차원 배열인
arr[1] = 3;
과 같은 문장은 쉽게 처리할 수 있다고 하지만, 그 보다 고차원 배열에 대해서
arr[1][2] = 3;
은 어떻게 처리할 것인가요? arr[1] 의 리턴 타입이 int& 라면 int 에 대한 operator[] 는 정의되어 있지도 않고 정의 할 수 도 없습니다. '그렇다면 상황에 따라서 1 차원이면 int 를, 그 보다 고차원 배열이면 다른 것을 리턴하면 되지 않냐?' 라고 물을 수 있지만'오버로딩' 의 원칙 상 동일한 인자를 받는 함수에 대해서는 한 가지 리턴 타입만이 가능합니다.
하지만 조금만 기억을 더듬어 올라간다면, 필요할 때 int 처럼 작동하지만 int 가 아닌 클래스를 만들 수 있었습니다. 바로int 의 Wrapper 클래스였지요. int 의 Wrapper 클래스는 타입 변환 연산자를 제공해서 int 와의 연산을 수행하거나, 대입등을 할 때 마치 int 처럼 작동하도록 만들 수 있습니다. 그렇다면 우리는 operator[] 가 int 의 Wrapper 클래스 객체를 리턴해서, 실제 int 값에 접근할 때에는 int 변수 처럼 행동하고, 위에서 T 나 T' 처럼 원소에 접근해 가는 중간 단계의 산물일 경우, 그 중간 단계의 정보를 포함하는 것으로 사용하면 됩니다.
이러한 생각을 바탕으로 int 의 Wrapper 클래스 Int 의 얼개를 그려보자면 다음과 같습니다.
class Int { void* data; int level; Array* array; };
먼저 level 정보는 반드시 포함하고 있어야만 합니다. 왜냐하면, 이 Int 가 맨 마지막 '실제 int 정보' 를 포함하고 있는 객체인지, 아니면 원소를 참조해 나가는 중간 과정에서의 산물인지를 구별할 수 있어야 하기 때문입니다.
예를 들어서
arr[1][2];
를 생각해 볼 때 맨 처음 arr[1] 은 level 이 1 인 Int 가 리턴됩니다. 이 때, 이는 int 데이터가 아니라, [1][2] 를 참조해 나가기 위한 중간 과정이지요. (이 것을 Int 가 어떻게 구별하냐면, Int 가 가지고 있는 array 의 dim 정보를 참조하면 되겠지요!)
이 때의 Int 에는 '현재 arr[1] 를 가리키고 있음' 에 대한 정보가 Int 의 data 에 들어가 있습니다. 그 다음에 Int 의 operator[] 를 수행하게 된다면 (따라서 Int 클래스의 operator[] 역시 만들어야 합니다), 이번에는 level 이 2 인 Int 가 리턴이 됩니다. 사용자가 level 이 2 인 Int 에 대입 연산을 하게 된다면, void * data 를 int 원소를 가리키고 있는 주소로 해석해서 실제로 int 변수 처럼 대입이 수행이 되겟지요.
참고로 array 는 어떤 배열의 Int 인지 가리키는 역할을 합니다.
먼저 Int 의 생성자는 아래와 같이 구성할 수 있습니다.
Int(int index, int _level = 0, void *_data = NULL, Array *_array = NULL) : level(_level), data(_data), array(_array) { if (_level < 1 || index >= array->size[_level - 1]) { data = NULL; return; } if (level == array->dim) { // 이제 data 에 우리의 int 자료형을 저장하도록 해야 한다. data = static_cast<void *>( (static_cast<int *>(static_cast<Array::Address *>(data)->next) + index)); } else { // 그렇지 않을 경우 data 에 그냥 다음 addr 을 넣어준다. data = static_cast<void *>( static_cast<Array::Address *>(static_cast<Array::Address *>(data)->next) + index); } };
Int 생성자의 내용을 설명하기 전에, 위에 Int 생성자의 인자로 이상한 것들이 보이지요? 왜 인자에 값을 미리 대입하고 있는 것인가요?
int index, int _level = 0, void *_data = NULL, Array *_array = NULL
이들은 모두 디폴트 인자(default argument)라고 부르는 것이며, 함수에 값을 전달해주지 않는다면 인자에 기본으로 이 값들이 들어가게 됩니다. 예를 들어서 우리가 Int 의 생성자에
Int(3)
이라고 호출하였다면, index 에는 3 이 들어가겠지만, _level 에는 0, _data 과 _array 에는 NULL 이 들어가겠지요. 만약에 인자를 지정해 주었다면, 디폴트 값 대신에 지정한 인자가 들어가게 됩니다. 예를 들어서
Int(3, 1)
이렇게 한다면 index 에는 3, _level 에는 1, 그리고 나머지에는 디폴트 값인 NULL 이 들어갑니다. 또한 한 가지 당연한 사실이지만, 디폴트 인자들은 함수의맨 마지막 인자 부터 '연속적으로'만 사용할 수 있습니다. 왜냐하면 만일 우리가 디폴트 인자를
int index, int _level = 0, void *_data = NULL, Array *_array
이렇게 중간에 두었다면 사용자가
Int(3, 1, ptr)
을 했을 때, 이 ptr 의 의미가 _data 는 디폴트 인자인 NULL 을 사용하고 _array 에는 ptr 을 사용하라는 것인지, 아니면 _data 에 ptr 이 들어가게 _array 에 인자를 안주는 오류인지 컴파일러가 알 수 없기 때문입니다. 이렇게 디폴트 인자를 사용하는 경우는 대부분 프로그래머들의 편의를 위해서 인데, 다만 함수의 원형을 정확히 알아야지, 일부 인자를 실수로 누락하게 된다면 디폴트 인자로 경고가 발생하지 않고, 그로 인해 함수가 이상하게 작동할 수 있으므로 주의가 필요합니다.
자 그럼 이제 Int 생성자의 내부를 살펴보도록 하겠습니다.
if (_level < 1 || index >= array->size[_level - 1]) { data = NULL; return; }
일단 위와 같이 오류가 발생하였을 경우 처리하는 모습입니다. 클래스를 구현할 때는 항상 클래스를 사용하는 사용자가 어떠한 이상한 짓을 하더라도 대처할 수 있는 자세가 필요합니다. 위와 같이 꼼꼼하게 발생할 수 있는 예외 상황을 처리하도록 합시다.
if (level == array->dim) { // 이제 data 에 우리의 int 자료형을 저장하도록 해야 한다. data = static_cast<void *>( (static_cast<int *>(static_cast<Array::Address *>(data)->next) + index)); } else { // 그렇지 않을 경우 data 에 그냥 다음 addr 을 넣어준다. data = static_cast<void *>( static_cast<Array::Address *>(static_cast<Array::Address *>(data)->next) + index); }
그 다음 부분을 살펴보자면, 상당히 중요한 부분입니다. 먼저 if 문에서 이 Int 의 level 과 array->dim 이 같다는 것은 무엇을 의미할까요? 이 말은, 원소에 접근하는 단계의 중간 산물이 아니라, 실질적으로 접근이 완료 되었다는 것입니다. 따라서, Int 의 data 에는 (int *) 타입의 포인터 주소값이 (void* 로 다시 캐스팅 되어서) 들어가겠지요. 즉, level == array->dim 이 되는 상황은 예컨대 3 차원 배열에서
arr[1][2][3];
을 하였을 때 arr[1] 은 level 1 짜리 Int 객체 T 를 리턴해서
T[2][3]
이 되고, T[2] 는 level 2 짜리 Int 객체 T' 을 리턴해서
T이 되고, 다시 T'[3] 은 level 3 짜리 Int 객체 T'' 을 리턴하게 되는데, 이 T'' 의 data 가 가리키는 포인터가 이전들과는 다르게 int 변수의 주소값이라는 것이지요. 그렇다면 당연히도 else 부분에서는, data 에 다음 Address 값이 들어갑니다.
data = static_cast<void *>( static_cast<Array::Address *>(static_cast<Array::Address *>(data)->next) + index);
위와 같이 data 를 만들게 된다면, 결과적으로 맨 마지막에서 사용자가 원하는 int 데이터를 정확히 찾아낼 수 있겠습니다.
이와 같은 사실을 바탕으로 하면 Array 의 operator[] 와 Int 의 operator[] 는 별로 어렵지 않게 만들 수 있습니다. 먼저 Array 의 operator[] 를 살펴보면
Int Array::operator[](const int index) { return Int(index, 1, static_cast<void *>(top), this); }
위와 같이 Int 를 리턴하게 되며, level 로는 1, 그리고 data 인자로는 top 을 전달합니다. 따라서 Int 생성자에서, 생성되는 객체가 top 의 next 가 가리키고 있는 index 번째 원소를 data 로 가질 수 있게 되지요.
Int operator[](const int index) { if (!data) return 0; return Int(index, level + 1, data, array); }
Int 의 operator[] 의 경우, level 에 다음 레벨을 전달함으로써 다음 단계의 Int 를 생성합니다. 그리고 위의 !data 를 검사하는 문장은 만일 data 가 NULL 이라면 (즉 예외 상황), 0 을 리턴하도록 하였습니다.
자 이제, Int 가 Wrapper 클래스로써 동작하기에 가장 필수적인 요소인 타입 변환 연산자를 살펴보면;
operator int() { if (data) return *static_cast<int *>(data); return 0; }
매우 간단합니다. 타입 변환 연산자가 호출되는 상태에서의 Int 객체의 data 에는 int 원소의 주소값이 들어가 있기 때문에 void* 를 int * 타입으로 변환에서 그 값을 리턴하면 됩니다.
자 그럼, 실제 전체 코드를 살펴보도록 합시다.
// 대망의 Array 배열 #include <iostream> namespace MyArray { class Array; class Int; class Array { friend Int; const int dim; // 몇 차원 배열 인지 int* size; // size[0] * size[1] * ... * size[dim - 1] 짜리 배열이다. struct Address { int level; // 맨 마지막 레벨(dim - 1 레벨) 은 데이터 배열을 가리키고, 그 위 상위 // 레벨에서는 다음 Address 배열을 가리킨다. void* next; }; Address* top; public: Array(int dim, int* array_size) : dim(dim) { size = new int[dim]; for (int i = 0; i < dim; i++) size[i] = array_size[i]; top = new Address; top->level = 0; initialize_address(top); } Array(const Array& arr) : dim(arr.dim) { size = new int[dim]; for (int i = 0; i < dim; i++) size[i] = arr.size[i]; top = new Address; top->level = 0; initialize_address(top); // 내용물 복사 copy_address(top, arr.top); } void copy_address(Address* dst, Address* src) { if (dst->level == dim - 1) { for (int i = 0; i < size[dst->level]; ++i) static_cast<int*>(dst->next)[i] = static_cast<int*>(src->next)[i]; return; } for (int i = 0; i != size[dst->level]; i++) { Address* new_dst = static_cast<Address*>(dst->next) + i; Address* new_src = static_cast<Address*>(src->next) + i; copy_address(new_dst, new_src); } } // address 를 초기화 하는 함수이다. 재귀 호출로 구성되어 있다. void initialize_address(Address* current) { if (!current) return; if (current->level == dim - 1) { current->next = new int[size[current->level]]; return; } current->next = new Address[size[current->level]]; for (int i = 0; i != size[current->level]; i++) { (static_cast<Address*>(current->next) + i)->level = current->level + 1; initialize_address(static_cast<Address*>(current->next) + i); } } void delete_address(Address* current) { if (!current) return; for (int i = 0; current->level < dim - 1 && i < size[current->level]; i++) { delete_address(static_cast<Address*>(current->next) + i); } if (current->level == dim - 1) { delete[] static_cast<int*>(current->next); } delete[] static_cast<Address*>(current->next); } Int operator[](const int index); ~Array() { delete_address(top); delete[] size; } }; class Int { void* data; int level; Array* array; public: Int(int index, int _level = 0, void* _data = NULL, Array* _array = NULL) : level(_level), data(_data), array(_array) { if (_level < 1 || index >= array->size[_level - 1]) { data = NULL; return; } if (level == array->dim) { // 이제 data 에 우리의 int 자료형을 저장하도록 해야 한다. data = static_cast<void*>(( static_cast<int*>(static_cast<Array::Address*>(data)->next) + index)); } else { // 그렇지 않을 경우 data 에 그냥 다음 addr 을 넣어준다. data = static_cast<void*>(static_cast<Array::Address*>( static_cast<Array::Address*>(data)->next) + index); } }; Int(const Int& i) : data(i.data), level(i.level), array(i.array) {} operator int() { if (data) return *static_cast<int*>(data); return 0; } Int& operator=(const int& a) { if (data) *static_cast<int*>(data) = a; return *this; } Int operator[](const int index) { if (!data) return 0; return Int(index, level + 1, data, array); } }; Int Array::operator[](const int index) { return Int(index, 1, static_cast<void*>(top), this); } } // namespace MyArray int main() { int size[] = {2, 3, 4}; MyArray::Array arr(3, size); for (int i = 0; i < 2; i++) { for (int j = 0; j < 3; j++) { for (int k = 0; k < 4; k++) { arr[i][j][k] = (i + 1) * (j + 1) * (k + 1); } } } for (int i = 0; i < 2; i++) { for (int j = 0; j < 3; j++) { for (int k = 0; k < 4; k++) { std::cout << i << " " << j << " " << k << " " << arr[i][j][k] << std::endl; } } } }
성공적으로 컴파일 하였다면
실행 결과
0 0 0 1 0 0 1 2 0 0 2 3 0 0 3 4 0 1 0 2 0 1 1 4 0 1 2 6 0 1 3 8 0 2 0 3 0 2 1 6 0 2 2 9 0 2 3 12 1 0 0 2 1 0 1 4 1 0 2 6 1 0 3 8 1 1 0 4 1 1 1 8 1 1 2 12 1 1 3 16 1 2 0 6 1 2 1 12 1 2 2 18 1 2 3 24
와 같이 제대로 실행됨을 볼 수 있습니다.
한 가지 중요하게 살펴볼 점은, 전체 클래스를 MyArray 라는 이름 공간으로 감쌌다는 점입니다. 이를 통해 혹여라도 다른 라이브러리에서 Array 라는 클래스를 정의하더라도 문제 없을 것입니다.
또한 주목할 점은, 두 개의 클래스를 한 파일에서 사용하기 때문에 클래스의 정의 순서가 매우 중요하다는 점입니다. 소스 상단에
class Array; class Int;
와 같이 클래스를 '선언' 하였습니다. 클래스를 선언하지 않는다면, 아래 Array 클래스에서
friend Int;
를 할 수 없게 됩니다. 왜냐하면 컴파일러 입장에서 Int 가 뭔지 알 턱이 없기 때문입니다. 따라서 friend 선언을 하기 전에, 이와 같이 class Int 를 먼저 맨 위에 선언해서 사용할 수 있도록 해야 합니다. 그럼에도 불구하고, 맨 밑에
Int Array::operator[](const int index) { return Int(index, 1, static_cast<void *>(top), this); }
를 Array 클래스 안에 넣지 않고 따로 빼 놓은 이유는 Int 를 실제로 '이용' 하기 위해서는 클래스 선언 만으로 충분하지 않기 때문입니다. 클래스 선언을 통해서는 클래스의 내부 정보가 필요가 없는 것들, 예컨대 friend 선언이나 클래스의 포인터를 정의하는 등의 행동만 가능하지, 위 Array 처럼 구체적으로 Int 클래스의 내부 정보 (생성자) 를 사용하는 경우에는 반드시 Int 클래스의 정의가 선행 되어야만 합니다. 따라서 어쩔 수 없이 Array 클래스의 operator[] 만 따로 빼 놓았습니다.
자. 여러분들은 아주 훌륭한 N 차원 Array 클래스를 제작하게 된 것입니다. 정말 놀랍지 않나요? C 언어 배우던 시절에는 정말 상상 조차 할 수 없는 위력적인 기능이 아닐 수 없습니다. C++ 에서 연산자 오버로딩을 지원한 덕택에 이러한 것들을 만들 수 있게 된 것입니다. 하지만, 사실 약간 불편한 점은 하나 있습니다. 모든 원소에 접근하려면 N 중 for 문을 사용해주어야만 합니다.
사실 2차원이나 3차원 정도의 배열을 사용한다먼 2~3 중 for 문을 사용하는 것은 기꺼히 승낙할 수 있습니다. 하지만 여러분들 4 중 for 문은 한 번이라도 돌려보셨나요? 아마도 이 정도 for 문을 중첩해서 돌린다면 보기도 안좋을 뿐더러 복잡하기만 할 것입니다. 따라서, 우리의 Array 클래스에 또다른 기능으로,모든 원소들을 순차적으로 접근할 수 있는 반복자(iterator) 라는 것을 추가해보도록 할 것입니다.
이를 위해 Array 에 Iterator 라는 클래스를 추가할 것입니다.
class Iterator { int* location; Array* arr; }
이 iterator 는 배열의 특정한 원소에 대한 포인터라고 생각하면 됩니다. C 언어에서 배열의 어떤 원소를 가리키고 있는 포인터 ptr 에 ptr ++ 을 했다면 다음 원소를 가리켰듯이, 반복자 itr 이 Array 의 어느 원소를 가리키고 있을 때 itr ++ 을 하면 그 다음 원소를 가리키게 됩니다. 따라서 사용자는 N 중 for 문을 사용해서 전체 원소를 참조하는 방법 보다는 단순히 itr 을 이용해서 Array 의 첫 원소 부터 itr ++ 을 통해 마지막 원소까지 가리킬 수 있게 할 것입니다.
이를 위해서, 우리의 Iterator 클래스에, 현재 Iterator 가 어떤 원소를 가리키고 있는지에 대한 정보를 멤버 변수로 가지게 하겠습니다. 이는 int * location 에 배열로 보관되는데, 예를 들어 3 차원 배열에서 Iterator 가
arr[1][2][3]
을 가리키고 있다면 location 배열에는 {1,2,3} 이렇게 들어가게 되는 것이지요. 상당히 단순한 방법이지요? 그렇기 때문에 operator++() 함수 자체도 매우 간단하게 만들 수 있습니다.
Iterator& operator++() { if (location[0] >= arr->size[0]) return (*this); bool carry = false; // 받아 올림이 있는지 int i = arr->dim - 1; do { // 어차피 다시 돌아온다는 것은 carry 가 true // 라는 의미 이므로 ++ 을 해야 한다. location[i]++; if (location[i] >= arr->size[i] && i >= 1) { // i 가 0 일 경우 0 으로 만들지 않는다 (이러면 begin 과 중복됨) location[i] -= arr->size[i]; carry = true; i--; } else carry = false; } while (i >= 0 && carry); return (*this); }
어떻게 위와 같은 코드가 나왔냐면 예를 들어 우리가 [2][3][4] 의 크기를 가지는 배열을 선언했다고 해봅시다. 그리고 어떤 itr 가 현재 원소 [1][1][3] 을 가리키고 있다고 해봅시다. 그럼 itr ++ 을 하게 된다면 [1][1][4] 가 되는 것이 아니라, 받아 올림이 되며 [1][2][0] 이 되겠지요.
이번에는 itr 가 [0][2][3] 인 상태에서 itr ++ 을 하면 어떨까요? 일단 [0][2][4] 가 되는 것이 아니라 1 받아 올림 되며 [0][3][0] 이 되는데, 3 역시 받아 올림 되서 [1][0][0] 이 되겠지요? 이와 같은 과정을 위에서 do - while 문으로 처리하였습니다. bool 변수 carry 는 '받아 올림이 있다' 라는 의미 입니다.
참고로 [1][2][3] 은 이 배열의 맨 마지막 원소가 됩니다. 그런데 여기서 itr ++ 을 하면, 원칙상 [0][0][0] 이 되어야 하는데, 이렇게 된다면, 이 배열을 사용하는 사람 입장에서 상당히 골치 아파 집니다. 왜냐하면 C++ 의 거의 대부분의 라이브러리에서 그러하지만 어떠한 배열의 시작(begin)은 맨 첫번째 원소를 의미하고, 마지막(end)은 맨 마지막 원소 바로 다음을 의미하기 때문입니다.
만일 우리가 배열의 처음 부터 마지막 까지 쭉 참조해 나가고 싶은데, 마지막 원소 다음에 다시 맨 처음 원소로 돌아온다면 for 문에 입장에서 이게 다시 돌아온 것인지, 새로 시작 하는 것인지 구별을 할 수 없기 때문입니다. 하지만 마지막 원소 다음을 '마지막' 이라 한다면, for 문의 조건문으로 '마지막에 도달하면 끝내라' 이렇게 명령을 한다면 쉽게 해결할 수 있습니다.
그러한 이유에서, 우리의 iterator 는 [1][2][3] 다음에는 [0][0][0] 이 아닌 [2][0][0] 이라 하고, (물론 여기에 해당하는 원소는 당연히 없습니다.) 이를 '마지막' 이라 하기로 하였습니다. 물론 마지막의 값을 참조하려고 하면 오류가 발생하겠지요.
이렇기 때문에 do - while 문 안에서도 특별히
if (location[i] >= arr->size[i] && i >= 1) { // i 가 0 일 경우 0 으로 만들지 않는다 (이러면 begin 과 중복됨) location[i] -= arr->size[i]; carry = true; i--; } else carry = false;
에서 location[i] >= arr->size[i] 말고도 i >= 1 이라는 특별한 조건을 넣어서 처리하도록 하였습니다.
참고로, 전위 증가 연산자를 만들었으므로 후위 증가 연산자도 만드는 것을 잊지 마세요.
Iterator operator++(int) { Iterator itr(*this); ++(*this); return itr; }
그렇다면 가장 중요한 * 연산자는 어떨까요. (*itr) 을 통해 실제 데이터에 접근해야 하므로, Int 를 리턴하게 됩니다. 따라서 그 모양은 다음과 같겠지요.
Int Array::Iterator::operator*() { Int start = arr->operator[](location[0]); for (int i = 1; i <= arr->dim - 1; i++) { start = start.operator[](location[i]); } return start; }
그냥 우리가 arr[][][] 해주던 일을 그냥 for 문으로 하는 것에 불과하다는 점을 알 수 있습니다. 매우 간단하지요.
이제 Array 클래스에 현재 배열의 시작과 끝을 Iterator 객체로 리턴해주는 것만 만들어주면 됩니다. 각각을 begin 와 end 라고 해보면;
Iterator begin() { int* arr = new int[dim]; for (int i = 0; i != dim; i++) arr[i] = 0; Iterator temp(this, arr); delete[] arr; return temp; } Iterator end() { int* arr = new int[dim]; arr[0] = size[0]; for (int i = 1; i < dim; i++) arr[i] = 0; Iterator temp(this, arr); delete[] arr; return temp; }
매우 단순합니다. begin 은 그냥 {0, 0, ... 0} 인 Iterator 를 리턴해주면 되는 것이고, end 는 {size[0], 0, 0, .. 0} 을 인 Iterator 를 리턴해주면 되는 것이니까요.
그럼 전체 소스 코드는 아래와 같습니다.
#include <iostream> namespace MyArray { class Array; class Int; class Array { friend Int; const int dim; // 몇 차원 배열 인지 int* size; // size[0] * size[1] * ... * size[dim - 1] 짜리 배열이다. struct Address { int level; // 맨 마지막 레벨(dim - 1 레벨) 은 데이터 배열을 가리키고, 그 위 상위 // 레벨에서는 다음 Address 배열을 가리킨다. void* next; }; Address* top; public: class Iterator { int* location; Array* arr; friend Int; public: Iterator(Array* arr, int* loc = NULL) : arr(arr) { location = new int[arr->dim]; for (int i = 0; i != arr->dim; i++) location[i] = (loc != NULL ? loc[i] : 0); } Iterator(const Iterator& itr) : arr(itr.arr) { location = new int[arr->dim]; for (int i = 0; i != arr->dim; i++) location[i] = itr.location[i]; } ~Iterator() { delete[] location; } // 다음 원소를 가리키게 된다. Iterator& operator++() { if (location[0] >= arr->size[0]) return (*this); bool carry = false; // 받아 올림이 있는지 int i = arr->dim - 1; do { // 어차피 다시 돌아온다는 것은 carry 가 true // 라는 의미 이므로 ++ 을 해야 한다. location[i]++; if (location[i] >= arr->size[i] && i >= 1) { // i 가 0 일 경우 0 으로 만들지 않는다 (이러면 begin 과 중복됨) location[i] -= arr->size[i]; carry = true; i--; } else carry = false; } while (i >= 0 && carry); return (*this); } Iterator& operator=(const Iterator& itr) { arr = itr.arr; location = new int[itr.arr->dim]; for (int i = 0; i != arr->dim; i++) location[i] = itr.location[i]; return (*this); } Iterator operator++(int) { Iterator itr(*this); ++(*this); return itr; } bool operator!=(const Iterator& itr) { if (itr.arr->dim != arr->dim) return true; for (int i = 0; i != arr->dim; i++) { if (itr.location[i] != location[i]) return true; } return false; } Int operator*(); }; friend Iterator; Array(int dim, int* array_size) : dim(dim) { size = new int[dim]; for (int i = 0; i < dim; i++) size[i] = array_size[i]; top = new Address; top->level = 0; initialize_address(top); } Array(const Array& arr) : dim(arr.dim) { size = new int[dim]; for (int i = 0; i < dim; i++) size[i] = arr.size[i]; top = new Address; top->level = 0; initialize_address(top); // 내용물 복사 copy_address(top, arr.top); } void copy_address(Address* dst, Address* src) { if (dst->level == dim - 1) { for (int i = 0; i < size[dst->level]; ++i) static_cast<int*>(dst->next)[i] = static_cast<int*>(src->next)[i]; return; } for (int i = 0; i != size[dst->level]; i++) { Address* new_dst = static_cast<Address*>(dst->next) + i; Address* new_src = static_cast<Address*>(src->next) + i; copy_address(new_dst, new_src); } } // address 를 초기화 하는 함수이다. 재귀 호출로 구성되어 있다. void initialize_address(Address* current) { if (!current) return; if (current->level == dim - 1) { current->next = new int[size[current->level]]; return; } current->next = new Address[size[current->level]]; for (int i = 0; i != size[current->level]; i++) { (static_cast<Address*>(current->next) + i)->level = current->level + 1; initialize_address(static_cast<Address*>(current->next) + i); } } void delete_address(Address* current) { if (!current) return; for (int i = 0; current->level < dim - 1 && i < size[current->level]; i++) { delete_address(static_cast<Address*>(current->next) + i); } if (current->level == dim - 1) { delete[] static_cast<int*>(current->next); } delete[] static_cast<Address*>(current->next); } Int operator[](const int index); ~Array() { delete_address(top); delete[] size; } Iterator begin() { int* arr = new int[dim]; for (int i = 0; i != dim; i++) arr[i] = 0; Iterator temp(this, arr); delete[] arr; return temp; } Iterator end() { int* arr = new int[dim]; arr[0] = size[0]; for (int i = 1; i < dim; i++) arr[i] = 0; Iterator temp(this, arr); delete[] arr; return temp; } }; class Int { void* data; int level; Array* array; public: Int(int index, int _level = 0, void* _data = NULL, Array* _array = NULL) : level(_level), data(_data), array(_array) { if (_level < 1 || index >= array->size[_level - 1]) { data = NULL; return; } if (level == array->dim) { // 이제 data 에 우리의 int 자료형을 저장하도록 해야 한다. data = static_cast<void*>(( static_cast<int*>(static_cast<Array::Address*>(data)->next) + index)); } else { // 그렇지 않을 경우 data 에 그냥 다음 addr 을 넣어준다. data = static_cast<void*>(static_cast<Array::Address*>( static_cast<Array::Address*>(data)->next) + index); } }; Int(const Int& i) : data(i.data), level(i.level), array(i.array) {} operator int() { if (data) return *static_cast<int*>(data); return 0; } Int& operator=(const int& a) { if (data) *static_cast<int*>(data) = a; return *this; } Int operator[](const int index) { if (!data) return 0; return Int(index, level + 1, data, array); } }; Int Array::operator[](const int index) { return Int(index, 1, static_cast<void*>(top), this); } Int Array::Iterator::operator*() { Int start = arr->operator[](location[0]); for (int i = 1; i <= arr->dim - 1; i++) { start = start.operator[](location[i]); } return start; } } // namespace MyArray int main() { int size[] = {2, 3, 4}; MyArray::Array arr(3, size); MyArray::Array::Iterator itr = arr.begin(); for (int i = 0; itr != arr.end(); itr++, i++) (*itr) = i; for (itr = arr.begin(); itr != arr.end(); itr++) std::cout << *itr << std::endl; for (int i = 0; i < 2; i++) { for (int j = 0; j < 3; j++) { for (int k = 0; k < 4; k++) { arr[i][j][k] = (i + 1) * (j + 1) * (k + 1) + arr[i][j][k]; } } } for (int i = 0; i < 2; i++) { for (int j = 0; j < 3; j++) { for (int k = 0; k < 4; k++) { std::cout << i << " " << j << " " << k << " " << arr[i][j][k] << std::endl; } } } }
성공적으로 컴파일 하였다면
실행 결과
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 0 0 0 1 0 0 1 3 0 0 2 5 0 0 3 7 0 1 0 6 0 1 1 9 0 1 2 12 0 1 3 15 0 2 0 11 0 2 1 15 0 2 2 19 0 2 3 23 1 0 0 14 1 0 1 17 1 0 2 20 1 0 3 23 1 1 0 20 1 1 1 25 1 1 2 30 1 1 3 35 1 2 0 26 1 2 1 33 1 2 2 40 1 2 3 47
와 같이 잘 실행됨을 알 수 있습니다. 한 가지 눈여겨 볼 점은
MyArray::Array::Iterator itr = arr.begin(); for (int i = 0; itr != arr.end(); itr++, i++) (*itr) = i;
와 같이 수행하는 부분입니다. 이와 같이 반복자를 이용하는 것은 C++ 에서 매우 많이 사용 되고 있는 방법으로, 나중에 표준 라이브러리들에 대해 살펴볼 때 다시 한번 등장하게 됩니다.
자 여러분 수고하셨습니다! 아마 이번 강좌는 제가 여태까지 진행한 강좌 중에 가장 어려웠고 저도 설명하기에 가장 어려운 내용이 아니였나 싶네요. 다음 강좌에서는 C++ 의 또 다른 쇼킹할 만한 기능들에 대해 살펴보도록 하겠습니다. 감사합니다.
생각해보기
문제 1
앞서 N 차원 배열을 구현하는 또 다른 방법 (그냥 x1 * ... * xn 개의 1 차원 배열을 만든 뒤에, [] 연산자를 위와 같이 특별한 방법을 이용하여 접근할 수 있게 하는 것) 으로 N 차원 배열을 구현해봅시다. (난이도 : 上)

댓글을 불러오는 중입니다..