모두의 코드
씹어먹는 C++ - <6 - 3. 가상함수와 상속에 관련한 잡다한 내용들>
이번 강좌에서는
virtual소멸자 (가상 소멸자)가상 함수 테이블 (virtual function table)
다중 상속
가상 상속
에 대해서 배웁니다.

안녕하세요 여러분. 지난 강좌에서는 놀라움의 연속이었던 virtual 키워드의 기능에 대해서 설명하였습니다. virtual 키워드를 통해서 동적 바인딩이라는 것을 이루어 낼 수 있었지요. 이번 강좌에서는 가상 함수와 상속에 관련하여 잡다한 내용들을 모두 짚고 넘어가도록 하겠습니다.
지난 시간에 배웠던 것을 간단히 정리해보자면 다음과 같습니다. Parent 클래스와 Child 클래스에 모두 f 라는 가상함수가 정의되어 있고, Child 클래스가 Parent 를 상속 받는다고 해봅시다. 그런 다음에 동일한 Parent* 타입의 포인터들도 각각 Parent 객체와 Child 객체를 가리킨다고 해봅시다.
Parent* p = new Parent(); Parent* c = new Child();
컴퓨터 입장에서 p 와 c 모두 Parent 를 가리키는 포인터들이므로, 당연히
p->f(); c->f();
를 했을 때 모두 Parent 의 f() 가 호출되어야 하겠지만, 실제로는 f 가 가상함수므로, '실제로 p 와 c 가 가리키는 객체의' f, 즉 p->f() 는 Parent 의 f 를, c->f() 는 Child 의 f 가 호출됩니다. 이와 같은 일이 가능한 이유는 f 를 가상함수로 만들었기 때문입니다.
virtual 소멸자
사실 클래스의 상속을 사용함으로써 중요하게 처리해야 되는 부분이 있습니다. 상속 시에, 소멸자를 가상함수로 만들어야 된다는 점입니다.
#include <iostream> class Parent { public: Parent() { std::cout << "Parent 생성자 호출" << std::endl; } ~Parent() { std::cout << "Parent 소멸자 호출" << std::endl; } }; class Child : public Parent { public: Child() : Parent() { std::cout << "Child 생성자 호출" << std::endl; } ~Child() { std::cout << "Child 소멸자 호출" << std::endl; } }; int main() { std::cout << "--- 평범한 Child 만들었을 때 ---" << std::endl; { Child c; } std::cout << "--- Parent 포인터로 Child 가리켰을 때 ---" << std::endl; { Parent *p = new Child(); delete p; } }
성공적으로 컴파일 하였다면
실행 결과
--- 평범한 Child 만들었을 때 --- Parent 생성자 호출 Child 생성자 호출 Child 소멸자 호출 Parent 소멸자 호출 --- Parent 포인터로 Child 가리켰을 때 --- Parent 생성자 호출 Child 생성자 호출 Parent 소멸자 호출
와 같이 나옵니다.
일단 평범하게 Child 객체를 만든 부분을 살펴봅시다.
std::cout << "--- 평범한 Child 만들었을 때 ---" << std::endl; { Child c; }
생성자와 소멸자의 호출 순서를 살펴보자면, Parent 생성자 → Child 생성자 → Child 소멸자 → Parent 소멸자 순으로 호출됨을 알 수 있습니다. 이와 같은 과정이 당연한 이유는 객체를 만들고 소멸시키는 일을 집을 짓고 철거하는 일로 비유할 수 있습니다.
집을 지을 때에는 큰 틀, 즉 기초공사를 하고 건물을 세운 다음에 (Parent 생성자 호출), 집 내부 공사, 인테리어, 가구 배치 등을 하게 됩니다 (Child 생성자 호출). 그리고 역으로 집을 철거할 때에는 안에 있는 내용물들을 모두 제거한 뒤에 (Child 소멸자 호출), 집 구조물을 철거하겠지요 (Parent 소멸자 호출).
그런데 문제는 그 아래 Parent 포인터가 Child 객체를 가리킬 때 입니다.
std::cout << "--- Parent 포인터로 Child 가리켰을 때 ---" << std::endl; { Parent *p = new Child(); delete p; }
delete p 를 하더라도, p 가 가리키는 것은 Parent 객체가 아닌 Child 객체 이기 때문에, 위에서 보통의 Child 객체가 소멸되는 것과 같은 순서로 생성자와 소멸자들이 호출되어야만 합니다. 그런데 실제로는, Child 소멸자가 호출되지 않습니다.
소멸자가 호출되지 않는다면 여러가지 문제가 생길 수 있습니다. 예를 들어서, Child 객체에서 메모리를 동적으로 할당하고 소멸자에서 해제하는데, 소멸자가 호출 안됬다면 메모리 누수(memory leak)가 생기겠지요.
하지만 virtual 키워드를 배운 이상 여러분은 무엇을 해야 하는지 알고 계실 것입니다. 단순히 Parent 의 소멸자를 virtual 로 만들어버리면 됩니다. Parent 의 소멸자를 virtual 로 만들면, p 가 소멸자를 호출할 때, Child 의 소멸자를 성공적으로 호출할 수 있게 됩니다.
#include <iostream> class Parent { public: Parent() { std::cout << "Parent 생성자 호출" << std::endl; } virtual ~Parent() { std::cout << "Parent 소멸자 호출" << std::endl; } }; class Child : public Parent { public: Child() : Parent() { std::cout << "Child 생성자 호출" << std::endl; } ~Child() { std::cout << "Child 소멸자 호출" << std::endl; } }; int main() { std::cout << "--- 평범한 Child 만들었을 때 ---" << std::endl; { // 이 {} 를 빠져나가면 c 가 소멸된다. Child c; } std::cout << "--- Parent 포인터로 Child 가리켰을 때 ---" << std::endl; { Parent *p = new Child(); delete p; } }
성공적으로 컴파일 하였다면
실행 결과
--- 평범한 Child 만들었을 때 --- Parent 생성자 호출 Child 생성자 호출 Child 소멸자 호출 Parent 소멸자 호출 --- Parent 포인터로 Child 가리켰을 때 --- Parent 생성자 호출 Child 생성자 호출 Child 소멸자 호출 Parent 소멸자 호출
와 같이 제대로 Child 소멸자가 호출됨을 알 수 있습니다.
여기서 한 가지 질문을 하자면, 그렇다면 왜 Parent 소멸자는 호출이 되었는가 인데, 이는 Child 소멸자를 호출하면서, Child 소멸자가 '알아서' Parent 의 소멸자도 호출해주기 때문입니다 (Child 는 자신이 Parent 를 상속받는다는 것을 알고 있습니다).
반면에 Parent 소멸자를 먼저 호출하게 되면, Parent 는 Child 가 있는지 없는지 모르므로, Child 소멸자를 호출해줄 수 없습니다 (Parent 는 자신이 누구에서 상속해주는지 알 수 없지요).
이와 같은 연유로,상속될 여지가 있는 Base 클래스들은 (위 경우 Parent) 반드시 소멸자를 virtual 로 만들어주어야 나중에 문제가 발생할 여지가 없게 됩니다.
레퍼런스도 된다
여태 까지 기반 클래스에서 파생 클래스의 함수에 접근할 때 항상 기반 클래스의 포인터를 통해서 접근하였습니다. 하지만, 사실 기반 클래스의 레퍼런스여도 문제 없이 작동합니다. 아래 간단한 예제를 통해 살펴보겠습니다.
#include <iostream> class A { public: virtual void show() { std::cout << "Parent !" << std::endl; } }; class B : public A { public: void show() override { std::cout << "Child!" << std::endl; } }; void test(A& a) { a.show(); } int main() { A a; B b; test(a); test(b); return 0; }
성공적으로 컴파일 하였다면
실행 결과
Parent ! Child!
와 같이 나옵니다.
void test(A& a) { a.show(); }
test 함수를 살펴보면 A 클래스의 레퍼런스를 받게 되어 있지만,
test(b);
를 통해서 B 클래스의 객체를 전달하였는데도 잘 작동하였습니다. 이는, B 클래스가 A 클래스를 상속 받고 있기 때문입니다. 즉, 함수에 타입이 기반 클래스여도 그 파생 클래스는 타입 변환되어 전달 할 수 있습니다.
따라서 test 함수에서 show() 를 호출하였을 때 인자로 b 를 전달하였다면, 비록 전달된 인자가A의 객체라고 표현되어 있지만 show 함수가 virtual 으로 정의되어 있기 때문에 알아서 B 의 show 함수를 찾아내서 호출하게 됩니다. 물론 test 에 a 를 전달하였을 때에는 A 의 show 함수가 호출되겠지요.
가상 함수의 구현 원리
여태 까지 virtual 키워드의 능력을 본 바로는 이러한 의문이 들 수 도 있을 것입니다.
그냥 그럼 모든 함수들을 virtual 로 만들어버리면 안되나?
사실 이는 매우 좋은 질문입니다. 왜냐하면 모든 함수들을 virtual 로 만들어버린다고 해서 문제될 것이 전혀 없기 때문입니다. 간혹 가상 이라는 이름 때문에 혼동하시는 분이 계시는데, virtual 키워드를 붙여서 가상 함수로 만들었다 해도 실제로 존재하는 함수이고 정상적으로 호출도 할 수 있습니다. 또한 모든 함수들을 디폴트로 가상 함수로 만듬으로써, 언제나 동적 바인딩이 제대로 동작하게 만들 수 있습니다.
실제로 자바의 경우 모든 함수들이 디폴트로 virtual 함수로 선언됩니다.
그렇다면 왜 C++ 에서는 virtual 키워드를 이용해 사용자가 직접 virtual 로 선언하도록 하였을까요? 그 이유는 가상 함수를 사용하게 되면 약간의 오버헤드 (overhead) 가 존재하기 때문입니다.
예를 들어서 다음과 같은 간단한 두 개의 클래스를 생각해봅시다.
class Parent { public: virtual void func1(); virtual void func2(); }; class Child : public Parent { public: virtual void func1(); void func3(); };
C++ 컴파일러는 가상 함수가 하나라도 존재하는 클래스에 대해서, 가상 함수 테이블(virtual function table; vtable)을 만들게 됩니다. 가상 함수 테이블은 전화 번호부라고 생각하시면 됩니다.
함수의 이름(전화번호부의 가게명) 과 실제로 어떤 함수 (그 가게의 전화번호) 가 대응되는지 테이블로 저장하고 있는 것입니다
위 경우 Parent 와 Child 모두 가상 함수를 포함하고 있기 때문에 두 개 다 가상 함수 테이블을 생성하게 되지요. 그 결과;
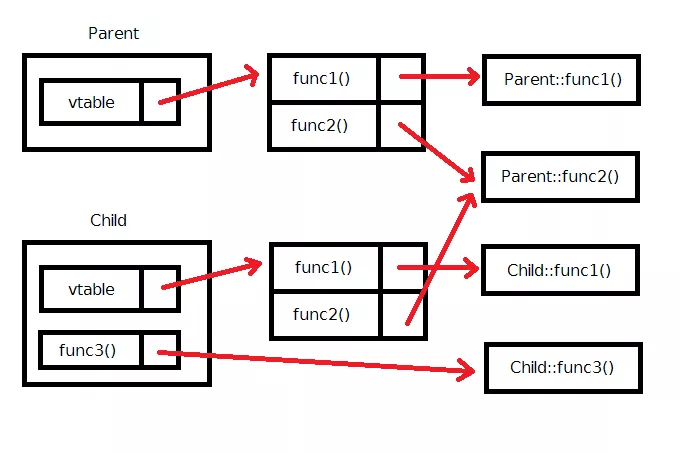
위와 같이 구성됩니다. 가상 함수와 가상 함수가 아닌 함수와의 차이점을 살펴보자면 Child 의 func3() 같이 비 가상함수들은 그냥 단순히 특별한 단계를 걸치지 않고, func3() 을 호출하면 직접 실행됩니다.
하지만, 가상 함수를 호출하였을 때는 그 실행 과정이 다릅니다. 위에서도 보이다 싶이, 가상 함수 테이블을 한 단계 더 걸쳐서, 실제로 어떤 함수를 고를지 결정하게 됩니다. 예를 들어서;
Parent* p = Parent(); p->func1();
을 해봅시다. 그러면, 컴파일러는
p가Parent를 가리키는 포인터 이니까,func1()의 정의를Parent클래스에서 찾아봐야겠다.func1()이 가상함수네? 그렇다면func1()을 직접 실행하는게 아니라, 가상 함수 테이블에서func1()에 해당하는 함수를 실행해야겠다.
그리고 실제로 프로그램 실행시에, 가상 함수 테이블에서 func1() 에 해당하는 함수(Parent::func1()) 을 호출하게 됩니다.
에 해당하는 코드를 작성하게 됩니다. 그렇다면, 다음의 경우는 어떨까요?
Parent* c = Child(); c->func1();
위 처럼 똑같이 프로그램 실행시에 가상 함수 테이블에서 func1() 에 해당하는 함수를 호출하게 되는데, 이번에는 p 가 실제로는 Child 객체를 가리키고 있으므로, Child 객체의 가상 함수 테이블을 참조하여, Child::func1() 을 호출하게 됩니다. 따라서 성공적으로 Parent::func1() 를 오버라이드 할 수 있습니다.
이와 같이 두 단계에 걸쳐서 함수를 호출함을 통해 소프트웨어적으로 동적 바인딩을 구현할 수 있게 됩니다. 이러한 이유로 가상 함수를 호출하는 경우, 일반적인 함수 보다 약간 더 시간이 오래 걸리게 됩니다.
물론 이 차이는 극히 미미하지만, 최적화가 매우 중요한 분야에서는 이를 감안할 필요가 있습니다. 아무튼 이러한 연유로 인해, 다른 언어들과는 다르게, C++ 에서는 멤버 함수가 디폴트로 가상함수가 되도록 설정하지는 않습니다.
순수 가상 함수(pure virtual function)와 추상 클래스(abstract class)
#include <iostream> class Animal { public: Animal() {} virtual ~Animal() {} virtual void speak() = 0; }; class Dog : public Animal { public: Dog() : Animal() {} void speak() override { std::cout << "왈왈" << std::endl; } }; class Cat : public Animal { public: Cat() : Animal() {} void speak() override { std::cout << "야옹야옹" << std::endl; } }; int main() { Animal* dog = new Dog(); Animal* cat = new Cat(); dog->speak(); cat->speak(); }
성공적으로 컴파일 하였다면
실행 결과
왈왈 야옹야옹
위 코드를 보면서 한 가지 특이한 점을 눈치 채셨을 것입니다.
class Animal { public: Animal() {} virtual ~Animal() {} virtual void speak() = 0; };
Animal 클래스의 speak 함수를 살펴봅시다. 다른 함수들과는 달리, 함수의 몸통이 정의되어 있지 않고 단순히 = 0; 으로 처리되어 있는 가상 함수 입니다.
그렇다면 이 함수는 무엇을 하는 함수 일까요? 그 답은, "무엇을 하는지 정의되어 있지 않는 함수" 입니다. 다시 말해 이 함수는 반드시 오버라이딩 되어야만 하는 함수 이지요.
이렇게, 가상 함수에 = 0; 을 붙여서, 반드시 오버라이딩 되도록 만든 함수를 완전한 가상 함수라 해서, 순수 가상 함수(pure virtual function)라고 부릅니다.
당연하게도, 순수 가상 함수는 본체가 없기 때문에, 이 함수를 호출하는 것은 불가능합니다. 그렇기 때문에, Animal 객체를 생성하는것 또한 불가능입니다. 왜냐하면,
Animal a; a.speak();
하면 안되기 때문이지요. 물론, speak() 함수를 호출하는 것을 컴파일러 상에서 금지하면 되지 않냐고 물을 수 있는데, C++ 개발자들은 이러한 방법 대신에 아예 Animal 의 객체 생성을 금지시키는 것으로 택하였습니다. (쉽게 말해 Animal 의 인스턴스를 생성할 수 없지요)
만일 Animal 의 객체를 생성하려고 한다면 다음과 같은 컴파일 오류를 만날 수 있습니다.
컴파일 오류
error C2259: 'Animal' : cannot instantiate abstract class 1> due to following members: 1> 'void Animal::speak(void)' : is abstract
따라서 Animal 처럼,순수 가상 함수를 최소 한 개 이상 포함하고 있는 클래스는 객체를 생성할 수 없으며, 인스턴스화 시키기 위해서는 이 클래스를 상속 받는 클래스를 만들어서 모든 순수 가상 함수를 오버라이딩 해주어야만 합니다.
이렇게 순수 가상 함수를 최소 한개 포함하고 있는- 반드시 상속 되어야 하는 클래스를 가리켜 추상 클래스 (abstract class)라고 부릅니다. (참고로, private 안에 순수 가상 함수를 정의하여도 문제 될 것이 없습니다. private 에 정의되어 있다고 해서 오버라이드 안된다는 뜻이 아니기 때문이죠. 다만 자식 클래스에서 호출을 못할 뿐입니다.)
따라서;
class Dog : public Animal { public: Dog() : Animal() {} void speak() override { std::cout << "왈왈" << std::endl; } };
위 처럼 speak() 를 오버라이딩 함으로써 (정확히 말하면 Animal 의 모든 순수 가상 함수를 오버라이딩 함으로써) Dog 클래스의 객체를 생성할 수 있게 됩니다. Cat 클래스도 마찬가지 이지요.
그렇다면 추상 클래스를 도대체 왜 사용하는 것일까요?
추상 클래스 자체로는 인스턴스화 시킬 수 도 없고 (추상 클래스의 객체를 만들 수 없다) 사용하기 위해서는 반드시 다른 누구가 상속 해줘야만 하기 때문이지요. 하지만, 추상 클래스를 '설계도' 라고 생각하면 좋습니다.
즉, 이 클래스를 상속받아서 사용하는 사람에게 "이 기능은 일반적인 상황에서 만들기 힘드니 너가 직접 특수화 되는 클래스에 맞추어서 만들어서 써라." 라고 말해주는 것이지요.
예를 들어서 위에서 예를 든 Animal 클래스의 경우
class Animal { public: Animal() {} virtual ~Animal() {} virtual void speak() = 0; };
동물들이 소리를 내는 것은 맞으므로 Animal 클래스에 speak 함수가 필요합니다. 하지만어떤 소리를 내는지는 동물 마다 다르기 때문에 speak 함수를 가상 함수로 만들기는 불가능 합니다. 따라서 speak 함수를 순수 가상 함수로 만들게 되면 모든 Animal 들은 speak() 한다라는 의미 전달과 함께, 사용자가 Animal 클래스를 상속 받아서 (위 경우 Dog 와 Cat) speak() 를 상황에 맞게 구현하면 됩니다.
추상 클래스의 또 한가지 특징은 비록 객체는 생성할 수 없지만, 추상 클래스를 가리키는 포인터는 문제 없이 만들 수 있다는 점입니다. 위 예에서도 살펴보았듯이, 아무런 문제 없이 Animal* 의 변수를 생성하였습니다.
Animal* dog = new Dog(); Animal* cat = new Cat(); dog->speak(); cat->speak();
그리고 dog 와 cat 의 speak 함수를 호출하였는데, 앞에서도 배웠듯이, 비록 dog 와 cat 이 Animal* 타입 이지만, Animal 의 speak 함수가 오버라이드 되어서, Dog 와 Cat 클래스의 speak 함수로 대체되서 실행이 됩니다.
다중 상속(multiple inheritance)
마지막으로 C++ 에서의 상속의 또 다른 특징인 다중 상속에 대해 알아보도록 합시다. C++ 에서는 한 클래스가 다른 여러 개의 클래스들을 상속 받는 것을 허용합니다. 이를 가리켜서 다중 상속 (multiple inheritance) 라고 부릅니다.
class A { public: int a; }; class B { public: int b; }; class C : public A, public B { public: int c; };
위 경우, 클래스 C 가 A 와 B 로 부터 동시에 같이 상속 받고 있습니다.
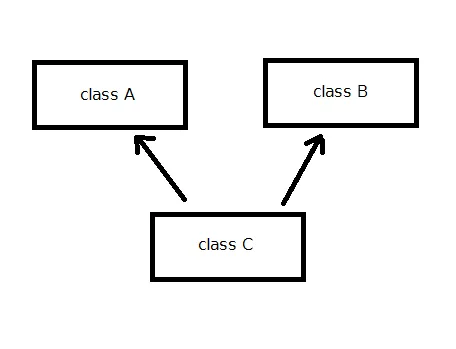
이를 그림으로 표현하자면 위 같은 모양이 되겠지요. 사실 다중 상속은 보통의 상속 하고 똑같이 생각하시면 됩니다. 단순히 그냥 A 와 B 의 내용이 모두 C 에 들어간다고 생각하시면 됩니다. 따라서;
C c; c.a = 3; c.b = 2; c.c = 4;
와 같은 것이 가능하게 되는 것이지요. 다중 상속에서 한 가지 재미있는 점은 생성자들의 호출 순서 입니다. 여러분은 과연 위 예에서 A 의 생성자가 먼저 호출될지, B 의 생성자가 먼저 호출될 지 궁금할 것입니다. 한 번 확인을 해보도록 하겠습니다.
#include <iostream> class A { public: int a; A() { std::cout << "A 생성자 호출" << std::endl; } }; class B { public: int b; B() { std::cout << "B 생성자 호출" << std::endl; } }; class C : public A, public B { public: int c; C() : A(), B() { std::cout << "C 생성자 호출" << std::endl; } }; int main() { C c; }
성공적으로 컴파일 하였다면
실행 결과
A 생성자 호출 B 생성자 호출 C 생성자 호출
위 처럼 A -> B -> C 순으로 호출됨을 알 수 있습니다. 그렇다면 이번에는,
class C : public A, public B
에서
class C : public B, public A
로 바꾸고 컴파일을 해보세요. 재미있게도;
실행 결과
B 생성자 호출 A 생성자 호출 C 생성자 호출
로 이번에는 B 의 생성자가 A 보다 먼저 호출됨을 알 수 있습니다. 몇 번 더 실험을 해보면 이 순서는 다른 것들에 의해 좌우되지 않고 오직 상속하는 순서에만 좌우 됨을 알 수 있습니다.
다중 상속 시 주의할 점
다중 상속은 C++ 에서 많이 사용되는 기법 중 하나 입니다. 하지만, 다중 상속을 올바르게 사용하기 위해서는 몇 가지 주의해야할 점들이 있습니다.
class A { public: int a; }; class B { public: int a; }; class C : public B, public A { public: int c; };
위처럼 만일 두 개의 클래스에서 이름이 같은 멤버 변수나 함수가 있다고 해봅시다. 예를 들어 위 예에서는 클래스 A 와 B 에 모두 a 라는 이름의 멤버 변수가 들어가 있습니다.
int main() { C c; c.a = 3; }
그렇다면 만일 클래스 C 의 객체를 생성해서, 위 처럼 중복되는 멤버 변수에 접근한다면;
컴파일 오류
error C2385: ambiguous access of 'a' 1> could be the 'a' in base 'B' 1> or could be the 'a' in base 'A'
위 처럼 B 의 a 인지, A 의 a 인지 구분할 수 없다는 오류를 발생하게 됩니다. 마찬가지로, 클래스 A 와 B 에 같은 이름의 함수가 있다면 똑같이 어떤 함수를 호출해야 될 지 구분할 수 없겠지요.
다중 상속 사용 시 또 한 가지 주의해야 할 점으로 다이아몬드 상속(diamond inheritance) 혹은 공포의 다이아몬드 상속(dreadful diamond of derivation) 이라고 부르는 형태의 다중 상속에 있습니다. 예를 들어 다음과 같은 형태의 상속 관계를 생각해봅시다.
class Human { // ... }; class HandsomeHuman : public Human { // ... }; class SmartHuman : public Human { // ... }; class Me : public HandsomeHuman, public SmartHuman { // ... };
일단 베이스 클래스로 Human 이라는 클래스가 있고, HandsomeHuman 과 SmartHuman 클래스는 Human 클래스를 모두 상속 받습니다.
그리고 두 가지 특성을 모두 보유한 나(Me) 라는 클래스는, HandsomeHuman 과 SmartHuman 클래스를 둘 다 상속 받습니다. 이를 그림으로 표현하자면 아래와 같은 다이아몬드 모양이 나오게 됩니다.
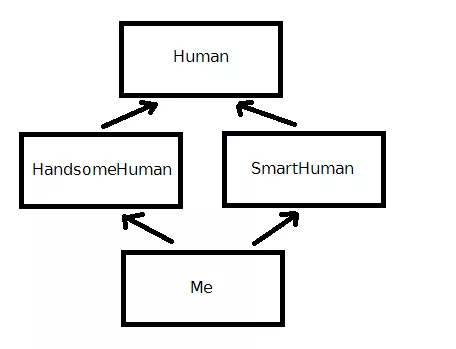
상속이 되는 두 개의 클래스가 공통의 베이스 클래스를 포함하고 있는 형태를 가리켜서 다이아몬드 상속이라고 부릅니다. 이러한 형태의 상속에 문제점은 보기에도 명백합니다.
만일 Human 에 name 이라는 멤버 변수가 있다고 해봅시다. 그러면 HandsomeHuman 과 SmartHuman 은 모두 Human 을 상속 받고 있으므로, 여기에도 name 이라는 변수가 들어가게 됩니다.
그런데 Me 가 이 두 개의 클래스를 상속 받으니 Me 에서는 name 이라는 변수가 겹치게 되는 것이지요. 결과적으로 볼 때 Handsome 과 SmartHuman 을 아무리 안겹치게 만든다고 해도, Human 의 모든 내용이 중복되는 문제가 발생하게 됩니다.
다행이도 이를 해결할 수 있는 방법이 있습니다.
class Human { public: // ... }; class HandsomeHuman : public virtual Human { // ... }; class SmartHuman : public virtual Human { // ... }; class Me : public HandsomeHuman, public SmartHuman { // ... };
이러한 형태로 Human 을 virtual 로 상속 받는다면, Me 에서 다중 상속 시에도, 컴파일러가 언제나 Human 을 한 번만 포함하도록 지정할 수 있게 됩니다. 참고로, 가상 상속 시에, Me 의 생성자에서 HandsomeHuman 과 SmartHuman 의 생성자를 호출함은 당연하고, Human 의 생성자 또한 호출해주어야만 합니다.
다중 상속은 언제 사용해야 할까?
C++ 공식 웹사이트의 FAQ 에 따르면 아래와 같은 가이드라인을 제시하고 있습니다.
예를 들어서 여러분이 차량(Vehicle) 에 관련한 클래스를 생성한다고 해봅시다. 차량의 종류로는 땅에서 다니는 차, 물에서 다니는 차, 하늘에서 다니는 차, 우주에서 다니는 차들이 있다고 해봅시다. (차 라고 하기 보다는 운송 수단이 좀 더 적절한 표현이겠네요..)
또한, 이 차량들은 각기 다른 동력원들을 사용하는데, 휘발유를 사용할 수 도 있고, 풍력으로 갈 수 도 있고 원자력으로 갈 수도 있고, 페달을 밟아서 갈 수 도 있습니다.
이러한 차량들을 클래스로 나타내기 위해서, 다중 상속을 활용할 수 있지만 그 전에, 아래와 같은 질문들에 대한 대답을 생각해봅시다.
LandVehicle을 가리키는Vehicle&레퍼런스를 필요로 할까? 다시 말해,Vehicle레퍼런스가 실제로는LandVehicle을 참조하고 있다면,Vehicle의 멤버 함수를 호출하였을 때, LandVehicle 의 멤버 함수가 오버라이드 되서 호출되기를 바라나요?GasPoweredVehicle의 경우도 마찬가지 입니다. 만일Vehicle레퍼런스가 실제로는GasPoweredVehicle을 참조하고 있을 때,Vehicle레퍼런스의 멤버함수를 호출한다면,GasPoweredVehicle의 멤버 함수가 오버라이드 되서 호출되기를 원하나요?
만일 두 개의 질문에 대한 대답이 모두 예 라면 다중 상속을 사용하는 것이 좋을 것입니다. 하지만 그 전에, 몇 가지 고려할 점이 더 있습니다. 만약에 이 차량이 작동하는 환경이 개가 있고 (땅, 물, 하늘, 우주 등등), 동력원의 종류가 개가 있다고 해봅시다.
이를 위해서, 크게 3 가지 방법으로 이러한 클래스를 디자인 할 수 있습니다. 바로 브리지 패턴 (bridge pattern), 중첩된 일반화 방식 (nested generalization), 다중 상속 입니다. 각각의 방식에는 모두 장단점이 있습니다.
브리지 패턴의 경우 차량을 나타내는 한 가지 카테고리를 아예 멤버 포인터로 만들어버립니다. 예를 들어서
Vehicle클래스의 파생 클래스로LandVehicle,SpaceVehicle클래스들이 있고,Vehicle클래스의 멤버 변수로 어떤 엔진을 사용하는지 가리키는Engine*멤버 변수가 있습니다. 이Engine은GasPowered,NuclearPowered와 같은Engine의 파생 클래스들의 객체들을 가리키게 됩니다. 그리고 런타임 시에 사용자가Engine을 적절히 설정해주면 됩니다. 이 경우 동력원 이나 환경을 하나 추가하더라도 클래스를 1 개만 더 만들면 됩니다. 즉, 총 개의 클래스만 생성하면 된다는 뜻입니다.하지만 오버라이딩 가지수가 개 뿐이므로 최대 개 알고리즘 밖에 사용할 수 없습니다. 만일 여러분이 개의 모든 상황에 대한 섬세한 제어가 필요하다면 브리지 패턴을 사용하지 않는 것이 좋습니다. 또한, 컴파일 타임 타입 체크를 적절히 활용할 수 없다는 문제가 있습니다. 예를 들어서
Engine이 페달이고 작동 환경이 우주라면, 애초에 해당 객체를 생성할 수 없어야 하지만 이를 컴파일 타임에서 강제할 방법이 없고 런타임에서나 확인할 수 있게 됩니다. 뿐만 아니라, 우주에서 작동하는 모든 차량을 가리킬 수 있는 기반 클래스를 만들 수 있지만 (SpaceVehicle클래스), 작동 환경에 관계 없이 휘발유를 사용하는 모든 차량을 가리킬 수 있는 기반 클래스를 만들 수 는 없습니다.중첩된 일반화 방식을 사용하게 된다면, 한 가지 계층을 먼저 골라서 파생 클래스들을 생성합니다. 예를 들어서
Vehicle클래스의 파생 클래스들로LandVehicle,WaterVehicle, 등등이 있겠지요. 그 후에, 각각의 클래스들의 대해 다른 계층에 해당하는 파생 클래스들을 더 생성합니다. 예컨대LandVehicle의 경우 동력원으로 휘발유를 사용한다면GasPoweredLandVehicle, 원자력을 사용한다면NuclearPoweredLandVehicle클래스를 생성할 수 있겠지요.따라서 최대 가지의 파생 클래스들을 생성할 수 있게 됩니다. 따라서 브릿지 패턴에 비해서 좀 더 섬세한 제어를 할 수 있게 됩니다. 왜냐하면 오버라이딩 가지수가 이 아닌 이 되기 때문이지요. 하지만 동력원을 하나 더 추가하게 된다면 최대 개의 파생 클래스를 더 만들어야 합니다. 뿐만 아니라 앞서 브릿지 패턴에서 나왔던 문제 - 휘발유를 사용하는 모든 차량을 가리킬 수 있는 기반 클래스를 만들 수 없다가 여전히 있습니다. 따라서 만약에 휘발유를 사용하는 차량들에서 공통적으로 사용되는 코드가 있다면 매 번 새로 작성해줘야만 합니다.
다중 상속을 이용하게 된다면, 브리지 패턴 처럼 각 카테고리에 해당하는 파생 클래스들을 만들게 되지만, 그 대신
Engine*멤버 변수를 없애고 동력원과 환경에 해당하는 클래스를 상속받는 파생 클래스들을 최대 개 만들게 됩니다. 예를 들어서 휘발유를 사용하며 지상에서 다니는 차량을 나타내는GasPoweredLandVehicle클래스의 경우GasPoweredEngine과LandVehicle두 개의 클래스를 상속받겠지요.따라서 이 방식을 통해서 브리지 패턴에서 불가능 하였던 섬세한 제어를 수행할 수 있을 뿐더러, 말도 안되는 조합을 (예컨대
PedalPoweredSpaceVehicle) 컴파일 타입에서 확인할 수 있습니다 (애초에 정의 자체를 안하면 되니까요!). 또한 이전에 두 방식에서 발생하였던 휘발유를 사용하는 모든 차량을 가리킬 수 없다 문제를 해결할 수 있습니다. 왜냐하면 이제GasPoweredEngine을 통해서 휘발유를 사용하는 모든 차량을 가리킬 수 있기 때문이지요.
가장 중요한 점은, 위 3 가지 방식 중에서 절대적으로 우월한 방식은 없다는 것입니다. 상황에 맞게 최선의 방식을 골라서 사용해야 합니다.
다중 상속은 만능 툴이 아닙니다. 실제로 다중 상속을 이용해서 해결해야 될 것 같은 문제도 알고보면 단일 상속을 통해 해결할 수 있는 경우들이 있습니다. 하지만 적절한 상황에 다중 상속을 이용한다면 위력적인 도구가 될 수 있을 것입니다.
아무래도 이번 강좌는 상속에 대한 중요한 요소들을 간단 하게 짚고 넘어가는 것이라 실질적인 프로그램은 만들지 않았습니다. 하지만, 가상 함수와 상속이 어떻게 돌아가는지 완벽히 이해하는 것이 좋습니다. 저의 경우, C++ 처음 배울 때, 이 부분에서 많이 헷갈려서 고생을 한 기억이 있습니다. 여러분들도 가상 함수를 포함하는 간단한 프로그램을 작성해서 어떻게 함수들이 호출되는지 살펴보시기 바랍니다.

댓글을 불러오는 중입니다..