모두의 코드
씹어먹는 C++ - <8 - 1. Excel 만들기 프로젝트 1부>
이번 강좌에서는
Excel 만들기 프로젝트의 1번째 문제를 해결할 것입니다.

안녕하세요 여러분! 이번 강좌에서는 여태 까지 배운 내용들을 바탕으로 하나의 작은 C++ 프로젝트를 진행해볼 예정입니다. 지난번 강좌의 생각해보기에서 공지하기는 했지만, 바로 콘솔로 Excel 을 만드는 것입니다. 물론 마이크로소프트의 그것 처럼 거대하게 만들 수 는 없지만, 그래도 기본적인 것들은 지원 할 수 있는 형태로 만들어 볼 예정입니다.
본격적으로 Excel 을 구현하기에 앞서서, 몇 가지 자료 구조를 만들 것입니다.자료구조라고 함은, 컴퓨터에서 데이터를 저장하는 방식이라 할 수 있는데, 그 구현에 따라서 장단점이 각각 있습니다. (장점만을 가진 자료 구조는 없습니다. 항상 무언가를 위해서 다른 무언가를 포기해야 되는 법이지요)
이 Excel 프로그램에서 사용할 자료구조는 크게 Vector 와 Stack 입니다.참고로 이들은 수식을 분석하기 위해, 즉 ExprCell 객체의 to_numeric 함수 내에서 사용될 예정입니다.
각 자료구조들은 다음과 같은 특징을 가지고 있습니다.
벡터 (Vector) : 수학의 그 벡터와는 살짝 다른 느낌인데, 그냥 배열의 크기를 맘대로 조절할 수 있는 가변길이 배열이라 보시면 됩니다. 즉, 배열 처럼
[]연산자로 임의의 위치에 있는 원소에 마음대로 접근할 수 있고 또 임의의 위치에 원소를 추가하거나 뺄 수 있습니다. 벡터를 만드는 방법은 이전에 문자열 클래스를 만들 때와 거의 비슷합니다. 문자열 역시char데이터를 담는 가변 길이 배열과 마찬가지 이기 때문이지요.스택 (Stack) : 벡터와는 다르게 임의의 위치에 있는 원소에 접근할 수 없고 항상 최 상단에 있는 데이터에만 접근할 수 있습니다. 그리고 새로운 데이터를 추가하면 최상단에 오게 됩니다. 쉽게 말해서 설거지 용으로 쌓아 놓는 접시들이라 보면 됩니다. 새로운 설거지 거리가 오면 쌓여 있는 접시 맨 위에 오게 되고(push). 설거지를 위해서 접시를 뺄 때 맨 위의 접시 부터 빼겠지요(pop).
물론 스택은 그냥 벡터를 활용해서 만들 수 있습니다. 하지만 이는 마치 소 잡는 칼을 닭 잡는 데 쓰는 것이라고나 할까요. 보통 스택의 경우 링크드 리스트(Linked List - 이 강좌의 Node 부분을 살펴보세요) 를 이용해서 구현을 합니다. 스택은 임의의 위치에 데이터에 접근할 필요가 없습니다. 단순히 최상위에 뭐가 있을 지 궁금하고 또 거기에 새로운 것을 추가하던지 빼기만 하면 되겠지요. 아래 스택을 간단히 어떻게 구현 할 지 그림으로 보여드리겠습니다.
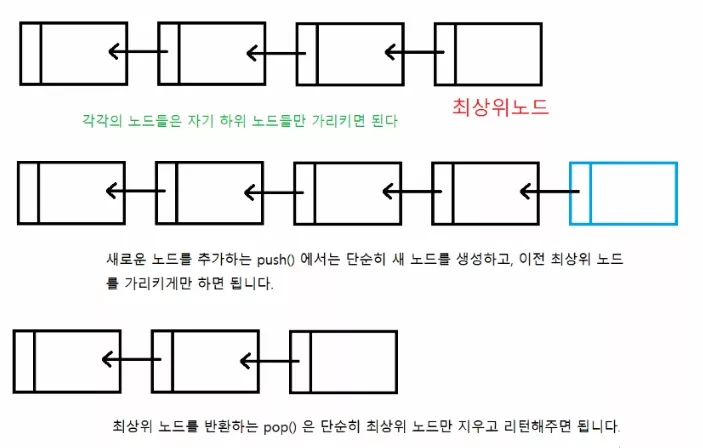
즉 스택의 경우 복잡하게 생각할 필요 없이 위와 같이 구성하면 됩니다.
벡터 클래스 (Vector)
먼저 문자열을 보관하기 위한 벡터 부터 만들겠습니다. 우리의 벡터 클래스는 다음과 같이 구성되어 있습니다.
class Vector { string* data; int capacity; int length; public: // 생성자 Vector(int n = 1); // 맨 뒤에 새로운 원소를 추가한다. void push_back(string s); // 임의의 위치의 원소에 접근한다. string operator[](int i); // x 번째 위치한 원소를 제거한다. void remove(int x); // 현재 벡터의 크기를 구한다. int size(); ~Vector(); };
먼저 클래스 소스를 살펴보도록 합시다.
string* data; int capacity; int length;
Vector 클래스는 위와 같이 데이터를 보관하기 위한 data (문자열 배열로 만들 것입니다), 현재 할당되어 있는 크기를 알려주는 capacity, 그리고 현재 실제로 사용하는 양인 length 와 같은 변수로 구성되어 있습니다.
// 생성자 Vector(int n = 1);
한 가지 특이한 점은 생성자에서 인자가 저렇게 int n = 1 과 같이 지정되어 있다는 것입니다. 이는 무엇이냐면, 만일 사용자가 인자를 지정하지 않으면, 알아서 n = 1 이 되게 지정한다는 것입니다. 다시 말해서
Vector a() Vector a(1)
은 동일한 작업입니다. 물론 사용자가 인자를 지정하면 해당 인자가 들어가겠지요. 이렇게 해당 인자의 기본 값을 지정해 놓은 것을 디폴트 인자 (Default argument) 라고 합니다. 이렇게 하면 사용자가 인자를 지정하지 않아도 디폴트 값이 들어가기 때문에 문제 없이 사용할 수 있습니다.
Vector::Vector(int n) : data(new string[n]), capacity(n), length(0) {}
Vector 의 생성자를 살펴보면 위와 같습니다. 한 가지 흥미로운 점은 여기서는 디폴트 인자가 명시되지 않은 점입니다. 이는 C++ 규칙이기도 한데, 클래스 내부 함수 선언에서 디폴드 인자를 명시하였다면 함수 본체에서 명시하면 안되고, 반대로 함수 본체에서 명시하였다면 클래스 내부 함수 선언에 명시하면 안됩니다. 즉, 둘 중 한 곳에서만 표시해야 합니다.
void Vector::push_back(string s) { if (capacity <= length) { string* temp = new string[capacity * 2]; for (int i = 0; i < length; i++) { temp[i] = data[i]; } delete[] data; data = temp; capacity *= 2; } data[length] = s; length++; } string Vector::operator[](int i) { return data[i]; } void Vector::remove(int x) { for (int i = x + 1; i < length; i++) { data[i - 1] = data[i]; } length--; } int Vector::size() { return length; } Vector::~Vector() { if (data) { delete[] data; } }
간단히 위 처럼 Vector 클래스의 함수들을 만들어 보았습니다. 이 Vector 클래스는 일반적으로 다른 사람들이 사용할 것이 아니라 제가 이 프로젝트에서 간단히 사용하기 위해 만들어놓은 것이므로 몇 가지 문제점들이나 구현하지 않는 함수들 (보통 Vector 클래스에는 중간에 원소를 추가하는 insert 나 검색하는 find 함수들도 세트로 다닙니다) 이 있습니다. 물론 이렇게 한 이유는 이 정도로도 Excel 프로젝트에는 충분하기 때문에 문제 없습니다.
void Vector::push_back(string s) { if (capacity <= length) { string* temp = new string[capacity * 2]; for (int i = 0; i < length; i++) { temp[i] = data[i]; } delete[] data; data = temp; capacity *= 2; } data[length] = s; length++; }
우리 Vector 클래스의 push_back 함수는 배열 맨 끝에 원소를 집어넣는 클래스 입니다. 위 방법은 기존에 문자열 클래스에서 썼던 방법으로, 만일 배열이 다 차게 되면 1 칸을 더 늘리는 것이 아니라 현재 크기의 두 배 만큼을 새로 할당하고 새로 할당단 공간에 복사하는 것입니다. 이렇게 된다면 가장 효율적으로 공간과 시간을 활용할 수 있습니다.
스택 클래스
이번에는 스택 클래스 입니다. 스택의 경우 위에서 말한 것 처럼 링크드 리스트를 사용하기 때문에 데이터를 보관하기 위해서 배열을 사용하는 것이 아니라 하나의 노드를 만들어서 노드들을 체인 처럼 엮을 것입니다. 이를 위해 아래와 같이 Stack 클래스 안에 Node 라는 구조체를 정의하였습니다.
struct Node { Node* prev; string s; Node(Node* prev, string s) : prev(prev), s(s) {} };
Node 객체에는 자기 보다 하위 Node 를 가리키는 포인터(prev)와, 자신이 보관하는 데이터에 관한 값(s)을 보관하는 두 개의 변수로 구성되어 있습니다. 그냥 맨 위에 그려놓은 스택 구현 모습을 그대로 표현하였다고 생각하면 됩니다. 아래는 전체 Stack 클래스의 모습입니다.
class Stack { struct Node { Node* prev; string s; Node(Node* prev, string s) : prev(prev), s(s) {} }; Node* current; Node start; public: Stack(); // 최상단에 새로운 원소를 추가한다. void push(string s); // 최상단의 원소를 제거하고 반환한다. string pop(); // 최상단의 원소를 반환한다. (제거 안함) string peek(); // 스택이 비어있는지의 유무를 반환한다. bool is_empty(); ~Stack(); };
Node 들의 리스트를 정확하게 관리하기 위해서, current 와 start 를 만들어서 current 는 현재 최상위 노드를 가리키게 하고, start 는 맨 밑바닥을 이루는 노드, 즉 최하위 노드를 가리키게 하였습니다. start 노드를 둔 이유는, 마지막 노드에 도달하였을 때 그 여부를 알아야 하기 때문이지요.
Stack::Stack() : start(NULL, "") { current = &start; } void Stack::push(string s) { Node* n = new Node(current, s); current = n; } string Stack::pop() { if (current == &start) return ""; string s = current->s; Node* prev = current; current = current->prev; // Delete popped node delete prev; return s; } string Stack::peek() { return current->s; } bool Stack::is_empty() { if (current == &start) return true; return false; } Stack::~Stack() { while (current != &start) { Node* prev = current; current = current->prev; delete prev; } }
위와 같이 간단하게 Stack 을 구성하였습니다. 주의해야 할 점은, 소멸자에서 최상위 원소 부터 줄줄이 바닥에 도달할 때 까지 메모리에서 해제시켜야 완전히 Stack 객체를 소멸시킬 수 있습니다.
스택의 경우 위와 같이 문자열을 받는 것 말고도, 숫자 데이터를 보관하는 스택인 NumStack 클래스 또한 string 만 int 로 바꿔서 동일하게 만들었습니다.
최종적으로 아래는 우리가 만든 벡터와 스택 클래스의 헤더 파일인 utils.h 의 전체 내용입니다.
#ifndef UTILS_H #define UTILS_H #include <string> using std::string namespace MyExcel { class Vector { string* data; int capacity; int length; public: // 생성자 Vector(int n = 1); // 맨 뒤에 새로운 원소를 추가한다. void push_back(string s); // 임의의 위치의 원소에 접근한다. string operator[](int i); // x 번째 위치한 원소를 제거한다. void remove(int x); // 현재 벡터의 크기를 구한다. int size(); ~Vector(); }; class Stack { struct Node { Node* prev; string s; Node(Node* prev, string s) : prev(prev), s(s) {} }; Node* current; Node start; public: Stack(); // 최상단에 새로운 원소를 추가한다. void push(string s); // 최상단의 원소를 제거하고 반환한다. string pop(); // 최상단의 원소를 반환한다. (제거 안함) string peek(); // 스택이 비어있는지의 유무를 반환한다. bool is_empty(); ~Stack(); }; class NumStack { struct Node { Node* prev; double s; Node(Node* prev, double s) : prev(prev), s(s) {} }; Node* current; Node start; public: NumStack(); void push(double s); double pop(); double peek(); bool is_empty(); ~NumStack(); }; } #endif
마찬가지로 아래는 해당 헤더파일 내용을 구현한 utility.cpp 입니다.
#include "utils.h" namespace MyExcel { Vector::Vector(int n) : data(new string[n]), capacity(n), length(0) {} void Vector::push_back(string s) { if (capacity <= length) { string* temp = new string[capacity * 2]; for (int i = 0; i < length; i++) { temp[i] = data[i]; } delete[] data; data = temp; capacity *= 2; } data[length] = s; length++; } string Vector::operator[](int i) { return data[i]; } void Vector::remove(int x) { for (int i = x + 1; i < length; i++) { data[i - 1] = data[i]; } length--; } int Vector::size() { return length; } Vector::~Vector() { if (data) { delete[] data; } } Stack::Stack() : start(NULL, "") { current = &start; } void Stack::push(string s) { Node* n = new Node(current, s); current = n; } string Stack::pop() { if (current == &start) return ""; string s = current->s; Node* prev = current; current = current->prev; // Delete popped node delete prev; return s; } string Stack::peek() { return current->s; } bool Stack::is_empty() { if (current == &start) return true; return false; } Stack::~Stack() { while (current != &start) { Node* prev = current; current = current->prev; delete prev; } } NumStack::NumStack() : start(NULL, 0) { current = &start; } void NumStack::push(double s) { Node* n = new Node(current, s); current = n; } double NumStack::pop() { if (current == &start) return 0; double s = current->s; Node* prev = current; current = current->prev; // Delete popped node delete prev; return s; } double NumStack::peek() { return current->s; } bool NumStack::is_empty() { if (current == &start) return true; return false; } NumStack::~NumStack() { while (current != &start) { Node* prev = current; current = current->prev; delete prev; } } }
참고로 우리의 Excel 관련한 모든 코드는 MyExcel 이라는 이름 공간에 담겨 있을 것입니다.
본격적인 `Cell` 과 `Table` 클래스
class Cell { protected: int x, y; Table* table; string data; public: virtual string stringify(); virtual int to_numeric(); Cell(string data, int x, int y, Table* table); };
Cell 클래스는 큰 테이블에서 한 칸을 의미하는 객체로, 해당 내용을 보관하는 문자열 data 와 어느 테이블에 위치해 있는지에 관련한 정보를 가지고 있는 table 과 그 위치 x, y 로 구성되어 있습니다.
또한, 가상 함수로 해당 셀 값을 문자열로 변환하는 stringify 함수와, 정수 데이터로 변환하는 to_numeric 함수도 선언되어 있습니다. 물론 문자열에 to_numeric 을 수행하게 되면 당연히 0 을 리턴하겠지만, 나중에 Cell 클래스를 NumberCell 과 같은 클래스들이 상속 받기 위한 큰 그림이라고 보시면 됩니다.
따라서 Cell 멤버 함수들의 정의는 아래와 같이 간단하게 나타낼 수 있습니다.
Cell::Cell(string data, int x, int y, Table* table) : data(data), x(x), y(y), table(table) {} string Cell::stringify() { return data; } int Cell::to_numeric() { return 0; }
자 그럼 Table 클래스의 정의를 살펴보도록 하겠습니다.
class Table { protected: // 행 및 열의 최대 크기 int max_row_size, max_col_size; // 데이터를 보관하는 테이블 // Cell* 을 보관하는 2차원 배열이라 생각하면 편하다 Cell*** data_table; public: Table(int max_row_size, int max_col_size); ~Table(); // 새로운 셀을 row 행 col 열에 등록한다. void reg_cell(Cell* c, int row, int col); // 해당 셀의 정수값을 반환한다. // s : 셀 이름 (Ex. A3, B6 과 같이) int to_numeric(const string& s); // 행 및 열 번호로 셀을 호출한다. int to_numeric(int row, int col); // 해당 셀의 문자열을 반환한다. string stringify(const string& s); string stringify(int row, int col); virtual string print_table() = 0; };
일단 Table 클래스는 Cell 객체들을 2 차원 배열로 보관하게 됩니다. 이 때, 객체 자체를 보관하는 것이 아니라, 객체는 필요할 대 마다 동적으로 생성하고, 그 객체에 대한 포인터를 2차원 배열로 보관하고 있게 됩니다.
Table::Table(int max_row_size, int max_col_size) : max_row_size(max_row_size), max_col_size(max_col_size) { data_table = new Cell**[max_row_size]; for (int i = 0; i < max_row_size; i++) { data_table[i] = new Cell*[max_col_size]; for (int j = 0; j < max_col_size; j++) { data_table[i][j] = NULL; } } }
따라서 Table 클래스의 생성자는 위와 같이 정의될 수 있습니다.
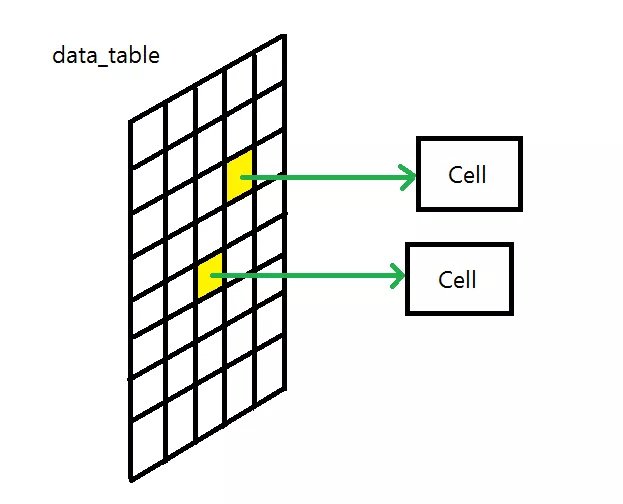
위 그림을 보면 쉽게 이해할 수 있듯이, 동적 할당으로 Cell* 배열을 생성한 후에, Cell 객체가 필요 할 때 마다 생성해서 배열의 원소들이 이를 가리킬 수 있게 하였습니다.
Table::~Table() { for (int i = 0; i < max_row_size; i++) { for (int j = 0; j < max_col_size; j++) { if (data_table[i][j]) delete data_table[i][j]; } } for (int i = 0; i < max_row_size; i++) { delete[] data_table[i]; } delete[] data_table; }
Table 소멸자도 이와 비슷합니다. 일단, 동적으로 생성된 Cell 객체를 모두 지워야 하고 그 다음에 Cell 배열 (1차원) 을 지워야 하고 마지막으로 2차원 테이블 자체를 메모리에서 지워야 합니다. 3 단계에 걸쳐서 Cell 의 흔적으로 메모리에서 날려버릴 수 있습니다.
void Table::reg_cell(Cell* c, int row, int col) { if (!(row < max_row_size && col < max_col_size)) return; if (data_table[row][col]) { delete data_table[row][col]; } data_table[row][col] = c; }
위는 Table 의 셀을 등록하는 함수 입니다. 등록하고자 하는 위치를 인자로 받는데, 만일 해당 위치에 이미 다른 셀 객체가 등록되어 있다면 해당 객체를 delete 한 후에 등록시켜주면 됩니다.
int Table::to_numeric(const string& s) { // Cell 이름으로 받는다. int col = s[0] - 'A'; int row = atoi(s.c_str() + 1) - 1; if (row < max_row_size && col < max_col_size) { if (data_table[row][col]) { return data_table[row][col]->to_numeric(); } } return 0; } int Table::to_numeric(int row, int col) { if (row < max_row_size && col < max_col_size && data_table[row][col]) { return data_table[row][col]->to_numeric(); } return 0; } string Table::stringify(const string& s) { // Cell 이름으로 받는다. int col = s[0] - 'A'; int row = atoi(s.c_str() + 1) - 1; if (row < max_row_size && col < max_col_size) { if (data_table[row][col]) { return data_table[row][col]->stringify(); } } return 0; } string Table::stringify(int row, int col) { if (row < max_row_size && col < max_col_size && data_table[row][col]) { return data_table[row][col]->stringify(); } return ""; } std::ostream& operator<<(std::ostream& o, Table& table) { o << table.print_table(); return o; }
마지막으로 해당하는 셀의 값을 반환하는 함수들로, 두 가지 형태로 구성되어 있는데 하나는 셀 이름(A1, B2 이렇게)을 받아서 해당하는 위치의 값을 리턴하는 함수와 행과 열 값을 받아서 해당 위치에 셀이 있으면 그 값을 리턴하는 함수들로 구성되어 있습니다.
또한 맨 마지막에 ostream 클래스의 << 연산자를 오버로딩하는 함수를 하나 만들어서 파일이나 표준 스트림(cout) 입출력에 쉽게 사용할 수 있도록 하였습니다.
하지만 이 Table 클래스의 객체는 생성할 수 없습니다. 왜냐하면 아래와 같은 순수 가상 함수가 포함되어 있기 때문이지요.
virtual string print_table() = 0;
우리는 이 Table 클래스를 상속 받는 다른 클래스를 만들어서 이 함수를 구현해주어야만 합니다.
class TxtTable : public Table { string repeat_char(int n, char c); // 숫자로 된 열 번호를 A, B, .... Z, AA, AB, ... 이런 순으로 매겨준다. string col_num_to_str(int n); public: TxtTable(int row, int col); // 텍스트로 표를 깨끗하게 출력해준다. string print_table(); };
위는 Table 클래스를 상속 받는 TxtTable 클래스 입니다. 이 클래스는 Table 의 내용을 텍스트의 형태로 예쁘게 정리해서 출력해주는 역할을 하고 있습니다.
TxtTable::TxtTable(int row, int col) : Table(row, col) {} // 텍스트로 표를 깨끗하게 출력해준다. string TxtTable::print_table() { string total_table; int* col_max_wide = new int[max_col_size]; for (int i = 0; i < max_col_size; i++) { unsigned int max_wide = 2; for (int j = 0; j < max_row_size; j++) { if (data_table[j][i] && data_table[j][i]->stringify().length() > max_wide) { max_wide = data_table[j][i]->stringify().length(); } } col_max_wide[i] = max_wide; } // 맨 상단에 열 정보 표시 total_table += " "; int total_wide = 4; for (int i = 0; i < max_col_size; i++) { if (col_max_wide[i]) { int max_len = max(2, col_max_wide[i]); total_table += " | " + col_num_to_str(i); total_table += repeat_char(max_len - col_num_to_str(i).length(), ' '); total_wide += (max_len + 3); } } total_table += "\n"; // 일단 기본적으로 최대 9999 번째 행 까지 지원한다고 생각한다. for (int i = 0; i < max_row_size; i++) { total_table += repeat_char(total_wide, '-'); total_table += "\n" + to_string(i + 1); total_table += repeat_char(4 - to_string(i + 1).length(), ' '); for (int j = 0; j < max_col_size; j++) { if (col_max_wide[j]) { int max_len = max(2, col_max_wide[j]); string s = ""; if (data_table[i][j]) { s = data_table[i][j]->stringify(); } total_table += " | " + s; total_table += repeat_char(max_len - s.length(), ' '); } } total_table += "\n"; } return total_table; } string TxtTable::repeat_char(int n, char c) { string s = ""; for (int i = 0; i < n; i++) s.push_back(c); return s; } // 숫자로 된 열 번호를 A, B, .... Z, AA, AB, ... 이런 순으로 매겨준다. string TxtTable::col_num_to_str(int n) { string s = ""; if (n < 26) { s.push_back('A' + n); } else { char first = 'A' + n / 26 - 1; char second = 'A' + n % 26; s.push_back(first); s.push_back(second); } return s; }
위는 그 구현 입니다. repeat_char 과 col_num_to_str 함수는 단순히 print_table 에서 사용할 부가적인 함수들 입니다. print_table 함수는 각 열의 최대 문자열 길이를 계산한 뒤에, 이를 바탕으로 각 열의 폭을 결정해서 표를 출력해줍니다.
참고로 이 구현 방식에서 한 가지 중요한 것이 빠졌는데, 셀의 문자열 데이터에서 개행 문자가 있는 경우(즉 특정 셀이 여러 줄이 될 때)를 고려하지 않았습니다. 즉, 모든 셀은 최대 1 줄로만 그려지게 됩니다. 따라서 실제로는 각 행의 최대 높이 역시 열과 마찬가지로 계산해서 그려야 합니다. (이는 여러분의 몫으로 남기겠습니다)
// 생략 int main() { MyExcel::TxtTable table(5, 5); std::ofstream out("test.txt"); table.reg_cell(new Cell("Hello~", 0, 0, &table), 0, 0); table.reg_cell(new Cell("C++", 0, 1, &table), 0, 1); table.reg_cell(new Cell("Programming", 1, 1, &table), 1, 1); std::cout << std::endl << table; out << table; }
성공적으로 컴파일 하였다면
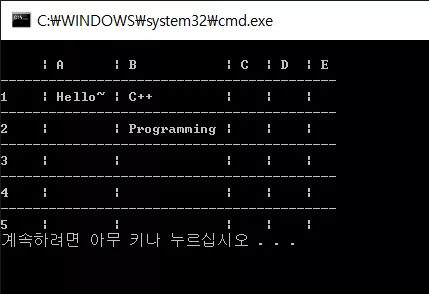
와 같이 잘 나오게 됩니다.
또한 test.txt 파일에도 역시

위와 같이 표가 잘 출력됩니다.
마찬가지로 저는 CSV 파일 형태와 HTML 형태로 데이터를 표현해주는 두 개의 클래스들을 더 만들었습니다.
class HtmlTable : public Table { public: HtmlTable(int row, int col); string print_table(); }; class CSVTable : public Table { public: CSVTable(int row, int col); string print_table(); };
딱히 특별한 것은 없고, HTML 파일 형식이나 CSV 파일 형식을 잘 알고 있다면 만드는데 큰 문제가 없을 것입니다. (HTML 표, CSV 파일 형식)
// 생략 int main() { MyExcel::CSVTable table(5, 5); std::ofstream out("test.csv"); table.reg_cell(new Cell("Hello~", 0, 0, &table), 0, 0); table.reg_cell(new Cell("C++", 0, 1, &table), 0, 1); table.reg_cell(new Cell("Programming", 1, 1, &table), 1, 1); out << table; MyExcel::HtmlTable table2(5, 5); std::ofstream out2("test.html"); table2.reg_cell(new Cell("Hello~", 0, 0, &table), 0, 0); table2.reg_cell(new Cell("C++", 0, 1, &table), 0, 1); table2.reg_cell(new Cell("Programming", 1, 1, &table), 1, 1); out2 << table2; }
그리고 그 구현 내용은 다음과 같습니다.
HtmlTable::HtmlTable(int row, int col) : Table(row, col) {} string HtmlTable::print_table() { string s = "<table border='1' cellpadding='10'>"; for (int i = 0; i < max_row_size; i++) { s += "<tr>"; for (int j = 0; j < max_col_size; j++) { s += "<td>"; if (data_table[i][j]) s += data_table[i][j]->stringify(); s += "</td>"; } s += "</tr>"; } s += "</table>"; return s; } CSVTable::CSVTable(int row, int col) : Table(row, col) {} string CSVTable::print_table() { string s = ""; for (int i = 0; i < max_row_size; i++) { for (int j = 0; j < max_col_size; j++) { if (j >= 1) s += ","; // CSV 파일 규칙에 따라 문자열에 큰따옴표가 포함되어 있다면 "" 로 // 치환하다. string temp; if (data_table[i][j]) temp = data_table[i][j]->stringify(); for (int k = 0; k < temp.length(); k++) { if (temp[k] == '"') { // k 의 위치에 " 를 한 개 더 집어넣는다. temp.insert(k, 1, '"'); // 이미 추가된 " 를 다시 확인하는 일이 없게 하기 위해 // k 를 한 칸 더 이동시킨다. k++; } } temp = '"' + temp + '"'; s += temp; } s += '\n'; } return s; }
성공적으로 컴파일 하였다면
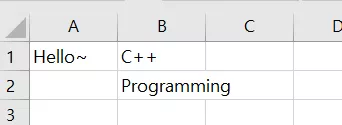
CSV 파일의 경우 위와 같이 (실제) 엑셀에서 잘 열리고
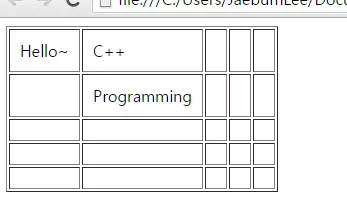
HTML 파일로 변환한 경우 위와 같이 브라우저 상에서 잘 표현됨을 알 수 있습니다.
이상으로 간단히 엑셀 만들기 프로젝트 1 부를 마치도록 하겠습니다. 다음 강좌에서는 Cell 을 상속 받는 클래스들을 만들어서 마치 실제 엑셀 처럼 작동하는 엑셀을 만들어 보도록 하겠습니다.

댓글을 불러오는 중입니다..