모두의 코드
씹어먹는 C++ - <6 - 2. 가상(virtual) 함수와 다형성>
이번 강좌에서는
is - a 와 has - a 관계
오버라이딩(overriding)
virtual키워드와 가상함수(virtual function)다형성(polymorphism)
에 대해서 배웁니다.

안녕하세요 여러분! 지난번 강좌는 재미있으셨나요. C++ 이란 산을 넘기 위해 아직도 지나가야 할 관문이 앞에 수 없이 많지만, 그래도 이번 강좌를 통해서 그 관문 하나는 지나갈 수 있으리라 생각합니다. 이번 강좌에서는 객체지향프로그래밍의 핵심 개념 하나에 대해서 배울 것입니다. 기대하세요 :)
is `- a` 와 `has - a`
일단 이야기를 진행하기 전에, 어떠한 경우에서 상속을 사용하는지 생각해봅시다. C++ 에서 상속을 도입한 이유는 단순히 똑같은 코드를 또 쓰는 것을 막기 위한 Ctrl + C, Ctrl + V 방지용으로 위한 것이 아닙니다 (물론 그러한 이유도 약간 있겠지만). 실제 이유는 상속이라는 기능을 통해서 객체지향프로그래밍에서 추구하는 실제 객체의 추상화를 좀 더 효과적으로 할 수 있게 되었습니다.
이게 무슨 말이냐면 상속이란 것이 없던 C 언어에서는 어떠한 구조체 사이의 관계를 표현할 수 있는 방법이 없었습니다. 하지만 C++ 에서 상속이란 것을 도입함으로써, 클래스 사이에 관계를 표현할 수 있게 되었는데, 예를 들어서 Manager 가 Employee 를 상속한다;
class Manager : public Employee
의 의미는,
Manager클래스는Employee의 모든 기능을 포함한다Manager클래스는Employee의 기능을 모두 수행할 수 있기 때문에 (Manager 에게는 약간 기분 나쁘겠지만)Manager를Employee라고 칭해도 무방하다즉, 모든
Manager는Employee이다Manager is a Employee !!
따라서, 모든 상속 관계는 is a 관계라고 볼 수 있습니다. 당연한 점은, 이를 뒤바꾸면 성립되지 않는 다는 점입니다. 즉 Manager 는 Employee 이지만 Employee 는 Manager 가 아닙니다. 이렇기에, Manager 를 Employee 로 부를 수 있지만, Employee 는 Manager 로 (미안하게도) 부를 수 없습니다.
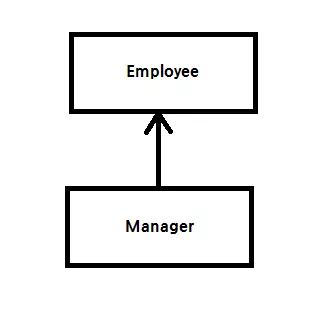
프로그램 설계 시에 클래스들 간의 상속 관계를 도표로 나타내는 경우가 종종 있는데, 많은 경우 파생 클래스가 기반 클래스를 화살표로 가리키게 그립니다.
실제 세상에서 is a 관계로 이루어진 것들은 수 없이 많습니다. 예를 들어, '사람' 이라는 클래스가 있다면, '프로그래머는 사람이다 (A programmer is a human)' 이므로, 만일 우리가 프로그래머 클래스를 만든다면 사람 이라는 클래스를 상속 받을 수 있도록 구성할 수 있습니다.
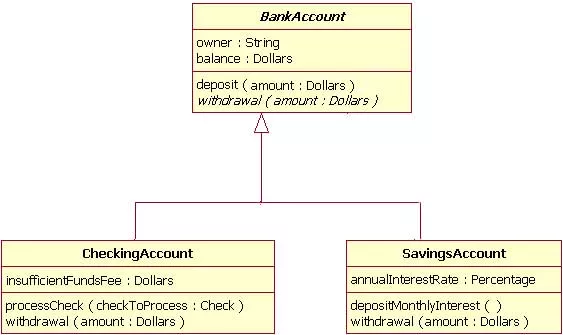
위는 또 다른 is - a 관계의 예로, BankAccount (은행 계좌) 라는 클래스가 있고 Checking Account (자유롭게 입출금이 가능한 계좌지만 이자가 없다) 와 Savings Account (비교적 자유롭게 입출금이 불가능하지만, 매 달 이자가 붙음) 가 이를 상속 받고 있습니다. 즉, 같은 계좌지만 기능이 약간 씩 다른 두 계좌 클래스들이 좀 더 '일반적인' BankAccount 클래스를 상속 받았지요.
이를 통해서 상속의 또 하나의 중요한 특징을 알 수 있습니다. 바로 클래스가 파생되면 파생될 수 록 좀 더 특수화 (구체화;specialize) 된다는 의미 입니다. 즉, Employee 클래스가 일반적인 사원을 위한 클래스 였다면 Manager 클래스 들은 그 일반적인 사원들 중에서도 좀 더 특수한 부류의 사원들을 의미하게 됩니다.
또, BankAccount 도 일반적인 은행 계좌를 위한 클래스 였다면, 이를 상속 받는 CheckingAccount, SavingsAccount 들은 좀 더 구체적인 클래스가 되지요. 반대로, 기반 클래스로 거슬러 올라가면 올라갈 수 록 좀 더 일반화 (generalize) 된다고 말합니다.
그렇다면 모든 클래스들의 관계를 is - a 로만 표현할 수 있을까요? 당연히 그렇지 않습니다. 어떤 클래스들 사이에서는 is - a 대신에 has - a 관계가 성립하기도 합니다. 예를 들어서, 간단히 자동차 클래스를 생각해봅시다. 자동차 클래스를 구성하기 위해서는 엔진 클래스, 브레이크 클래스, 오디오 클래스 등 수 많은 클래스들이 필요합니다. 그렇다고 이들 사이에 is a 관계를 도입 할 수 없습니다. (자동차 is a 엔진? 자동차 is a 브레이크?) 그 대신, 이들 사이는 has - a 관계로 쉽게 표현할 수 있습니다.
즉, 자동차는 엔진을 가진다 (자동차 has a 엔진), 자동차는 브레이크를 가진다 (자동차 has a 브레이크) 이와 같이 말이지요. 이런 has - a 관계는 우리가 흔히 해왔듯이 다음과 같이 클래스로 나타내면 됩니다.
class Car { private: Engine e; Brake b; // 아마 break 아니냐고 생각하는 사람들이 있을 텐데 :) .... };
또 다른 예로 바로 우리의 EmployeeList 를 들을 수 도 있습니다. EmployeeList 는 Employee 들과 has - a 관계 이지요. 따라서, 실제로 EmployeeList 클래스를 보면
class EmployeeList { int alloc_employee; // 할당한 총 직원 수 int current_employee; // 현재 직원 수 Employee **employee_list; // 직원 데이터
와 같이 Employee 를 포함하고 있음을 알 수 있습니다.
(다시 보는) 오버라이딩
#include <iostream> #include <string> class Base { std::string s; public: Base() : s("기반") { std::cout << "기반 클래스" << std::endl; } void what() { std::cout << s << std::endl; } }; class Derived : public Base { std::string s; public: Derived() : s("파생"), Base() { std::cout << "파생 클래스" << std::endl; } void what() { std::cout << s << std::endl; } }; int main() { std::cout << " === 기반 클래스 생성 ===" << std::endl; Base p; p.what(); std::cout << " === 파생 클래스 생성 ===" << std::endl; Derived c; c.what(); return 0; }
성공적으로 컴파일 하였다면
실행 결과
=== 기반 클래스 생성 === 기반 클래스 기반 === 파생 클래스 생성 === 기반 클래스 파생 클래스 파생
이미 저번 강좌에서도 이야기 했었지만, Base 에서 what 을 호출하면 당연히 Base 의 what 이 실행되어서 '기반' 라고 나오고, Base 를 상속받는 Derived 클래스에서 what 을 호출하면, Derived 의 what 이 Base 의 what 을 오버라이드 해서 Derived 의 what 이 호출되게 됩니다.
이번에는 코드를 약간 변형해보도록 하겠습니다.
#include <iostream> #include <string> class Base { std::string s; public: Base() : s("기반") { std::cout << "기반 클래스" << std::endl; } void what() { std::cout << s << std::endl; } }; class Derived : public Base { std::string s; public: Derived() : s("파생"), Base() { std::cout << "파생 클래스" << std::endl; } void what() { std::cout << s << std::endl; } }; int main() { Base p; Derived c; std::cout << "=== 포인터 버전 ===" << std::endl; Base* p_c = &c; p_c->what(); return 0; }
성공적으로 컴파일 하였다면
실행 결과
기반 클래스 기반 클래스 파생 클래스 === 포인터 버전 === 기반
이번에는 Derived 의 객체 c 를 Base 객체를 가리키는 포인터에 넣었습니다.
Base* p_c = &c;
어떤 분들은 이와 같은 대입이 가능하냐고 물을 수 있습니다. Base 와 Derived 는 다른 클래스 이니까요. 하지만, 그 분들이 간과하고 있는 점은 Derived 가 Base 를 상속 받고 있다는 점입니다. 상속 받는다면 뭐죠? Derived is a Base
즉 (말이 조금 이상하지만) Derived 객체 c 도 어떻게 보면 Base 객체이기 때문에 Base 객체를 가리키는 포인터가 c 를 가리켜도 무방하다는 것입니다. 이를 그림으로 표현한다면 아래와 같습니다.
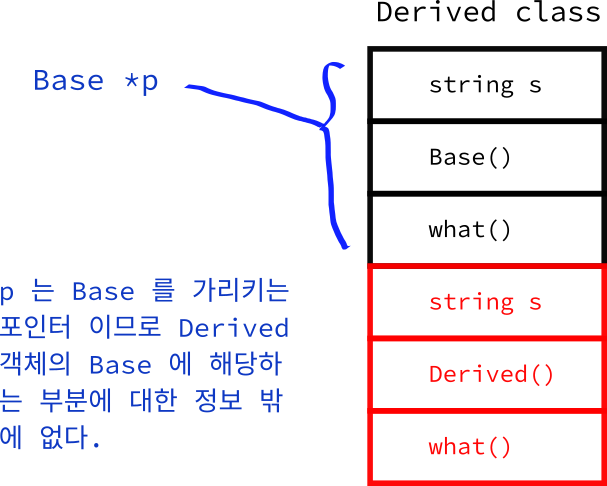
그 대신 p 는 엄연한 Base 객체를 가리키는 포인터 입니다. 따라서, p 의 what 을 실행한다면 p 는 당연히 '아 Base 의 what 을 실행해 주어야 겠구나' 하고, Base 의 what 을 실행해서, Base 의 what 은 Base 의 s 를 출력 하게 됩니다. 따라서 위 처럼 '기반' 가 출력됩니다.
이러한 형태의 캐스팅을 (즉 파생 클래스에서 기반 클래스로 캐스팅 하는 것) 을 업 캐스팅 이라고 부릅니다.
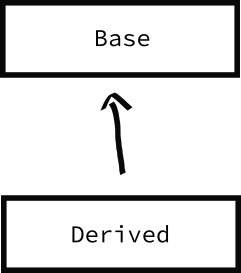
위 그림을 보면 왜 업 캐스팅이라 부르는지 이해가 확 되지요.
그렇다면 업 캐스팅의 반대인 다운 캐스팅도 있을까요?
#include <iostream> #include <string> class Base { std::string s; public: Base() : s("기반") { std::cout << "기반 클래스" << std::endl; } void what() { std::cout << s << std::endl; } }; class Derived : public Base { std::string s; public: Derived() : s("파생"), Base() { std::cout << "파생 클래스" << std::endl; } void what() { std::cout << s << std::endl; } }; int main() { Base p; Derived c; std::cout << "=== 포인터 버전 ===" << std::endl; Derived* p_p = &p; p_p->what(); return 0; }
컴파일 한다면 다음과 같은 오류 메세지를 볼 수 있습니다.
컴파일 오류
error C2440: 'initializing' : cannot convert from 'Base *' to 'Derived *'
사실 위와 같은 오류가 발생한 이유는 간단합니다.
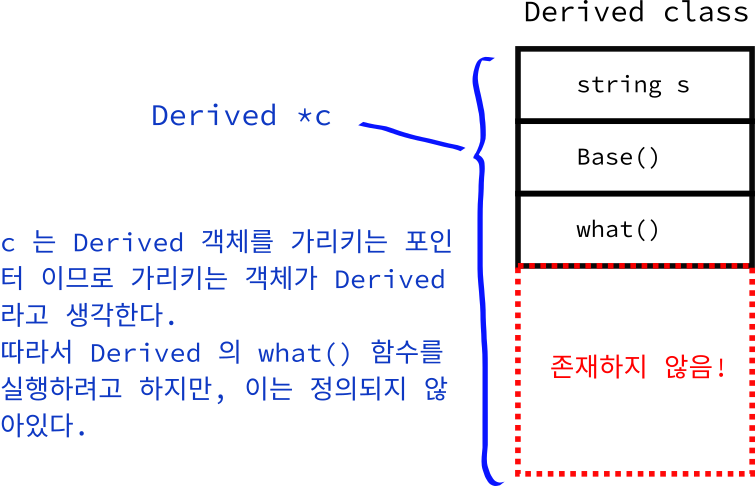
만일 Derived* 포인터가 Base 객체를 가리킨다고 해봅시다. 그렇다면 p_p->what() 하게 된다면 Derived 의 what 함수가 호출되어야만 하는데, 이는 불가능 합니다. (왜냐하면 p_p 가 가리키는 객체는 Base 객체 이므로 Derived 에 대한 정보가 없습니다). 따라서, 이와 같은 문제를 막기 위해서 컴파일러 상에서 함부로 다운 캐스팅 하는 것을 금지하고 있습니다.
하지만 다음과 같은 상황은 어떨까요.
#include <iostream> #include <string> class Base { std::string s; public: Base() : s("기반") { std::cout << "기반 클래스" << std::endl; } void what() { std::cout << s << std::endl; } }; class Derived : public Base { std::string s; public: Derived() : s("파생"), Base() { std::cout << "파생 클래스" << std::endl; } void what() { std::cout << s << std::endl; } }; int main() { Base p; Derived c; std::cout << "=== 포인터 버전 ===" << std::endl; Base* p_p = &c; Derived* p_c = p_p; p_c->what(); return 0; }
컴파일 하였다면
컴파일 오류
error C2440: 'initializing' : cannot convert from 'Base *' to 'Derived *'
Derived* p_c 에 Base * 를 대입하면 안된다는 똑같은 오류가 발생합니다. 하지만 우리는 p_p 가 가리키는 것이 Base 객체가 아니라 Derived 객체라는 사실을 알고 있습니다. 그렇기 때문에 비록 Base * 포인터를 다운 캐스팅 함에도 불구하고 p_p 가 실제로는 Derived 객체를 가리키기 때문에
Derived* p_c = p_p;
를 해도 전혀 문제가 없습니다. 이를 위해서는 아래 처럼 강제적으로 타입 변환을 하면 됩니다.
Derived* p_c = static_cast<Derived*>(p_p);
비록 약간은 위험하지만 (만일 p_p 가 사실은 Derived 객체를 가리키지 않는다면?) 컴파일 오류를 발생시키지 않고 성공적으로 컴파일 할 수 있습니다. 그렇다면 만일 p_p 가 사실 Base 객체를 가리키는데 강제적으로 타입 변환을 해서 what 을 실행한다면 어떨까요?
#include <iostream> #include <string> class Base { std::string s; public: Base() : s("기반") { std::cout << "기반 클래스" << std::endl; } void what() { std::cout << s << std::endl; } }; class Derived : public Base { std::string s; public: Derived() : s("파생"), Base() { std::cout << "파생 클래스" << std::endl; } void what() { std::cout << s << std::endl; } }; int main() { Base p; Derived c; std::cout << "=== 포인터 버전 ===" << std::endl; Base* p_p = &p; Derived* p_c = static_cast<Derived*>(p_p); p_c->what(); return 0; }
성공적으로 컴파일 하였다면
와 같은 런타임 오류가 발생하게 됩니다.
이러한 강제적으로 다운 캐스팅을 하는 경우, 컴파일 타임에서 오류를 찾아내기 매우 힘들기 때문에 다운 캐스팅은 작동이 보장되지 않는 한 매우매우 권장하지 않는 바입니다.
dyanmic_cast
이러한 캐스팅에 따른 오류를 미연에 방지하기 위해서, C++ 에서는 상속 관계에 있는 두 포인터들 간에 캐스팅을 해주는 dynamic_cast 라는 것을 지원합니다. 이를 사용하는 방법은 static_cast 와 거의 동일합니다.
Derived* p_c = dyanmic_cast<Derived*>(p_p);
하지만 위의 경우 컴파일 하게 된다면
컴파일 오류
test.cc: In function 'int main()': test.cc:27:44: error: cannot dynamic_cast 'p_p' (of type 'class Base*') to type 'class Derived*' (source type is not polymorphic) Derived* p_c = dynamic_cast<Derived*>(p_p);
와 같이 캐스팅 할 수 없다는 컴파일 오류가 발생하게 됩니다.
EmployeeList 다시 보기
자, 그럼 이제 위에서 다룬 내용을 가지고 EmployeeList 를 어떻게 하면 좀 더 간단하게 만들 수 있을 지 생각해봅시다.
class EmployeeList { int alloc_employee; // 할당한 총 직원 수 int current_employee; // 현재 직원 수 int current_manager; // 현재 매니저 수 Employee **employee_list; // 직원 데이터 Manager **manager_list; // 매니저 데이터 // ...
위와 같은 구성에서 가장 문제가 되는 것이 각 클래스 별로 데이터를 따로 보관해야 된다는 것입니다. 즉 Employee 들은 Employee * 가 가리켜야 하고, Manager 들은 Manager * 가 가리켜야 합니다. 만일 무한 상사에서 클래스 하나를 더 추가해달라고 연락이 왔다간 때릴 지도 모르겠지요.
하지만, 한 가지 위에서 배운 사실은, 업 캐스팅은 매우 자유롭게 수행될 수 있다는 점입니다. 즉, Employee * 가 Manager 객체를 가리켜도 별 문제가 없다는 것이지요. 그렇다면 manager_list 를 그냥 지워 버리고, employee_list 가 Employee, Manager 상관없이 가리키게 해도 될까요? 그러면 참 좋겠지만 다음과 같은 문제점이 있습니다.
void print_employee_info() { int total_pay = 0; for (int i = 0; i < current_employee; i++) { employee_list[i]->print_info(); total_pay += employee_list[i]->calculate_pay(); } ...
바로 여기서, employee_list[i]->print_info() 를 하게 되면 무조건 Employee 클래스의 print_info 함수가 호출된다는 것입니다. 왜냐하면 위에서도 이야기 하였듯이, employee_list[i] 는 Employee 객체를 가리키는 포인터 이기 때문에 자신이 가리키는 객체가 Employee 객체라고 생각합니다.
하지만 우리는 Manager 객체와 Employee 객체 모두 Employee* 가 가리키도록 하였으므로, 만일 employee_list[i] 가 가리키는 것이 Manager 객체 일 때, Manager 의 print_info 함수가 아니라 Employee 의 print_info 함수가 호출되서 다른 결과를 냅니다.
마찬가지로 calculate_pay 함수도 Manager 의 calculate_pay 가 호출 되어야 하는데 Employee 의 calculate_pay 가 호출되어서 (월급이 더 적게나오는 ㅠㅠ) 틀린 결과가 나옵니다. 나쁜 회사였으면 환영할 일이였겠지만 착한 우리의 입장에선 이 문제를 꼭 해결해야 합니다.
실제로,
#include <iostream> #include <string> class Employee { protected: std::string name; int age; std::string position; // 직책 (이름) int rank; // 순위 (값이 클 수록 높은 순위) public: Employee(std::string name, int age, std::string position, int rank) : name(name), age(age), position(position), rank(rank) {} // 복사 생성자 Employee(const Employee& employee) { name = employee.name; age = employee.age; position = employee.position; rank = employee.rank; } // 디폴트 생성자 Employee() {} void print_info() { std::cout << name << " (" << position << " , " << age << ") ==> " << calculate_pay() << "만원" << std::endl; } int calculate_pay() { return 200 + rank * 50; } }; class Manager : public Employee { int year_of_service; public: Manager(std::string name, int age, std::string position, int rank, int year_of_service) : year_of_service(year_of_service), Employee(name, age, position, rank) {} // 복사 생성자 Manager(const Manager& manager) : Employee(manager.name, manager.age, manager.position, manager.rank) { year_of_service = manager.year_of_service; } // 디폴트 생성자 Manager() : Employee() {} int calculate_pay() { return 200 + rank * 50 + 5 * year_of_service; } void print_info() { std::cout << name << " (" << position << " , " << age << ", " << year_of_service << "년차) ==> " << calculate_pay() << "만원" << std::endl; } }; class EmployeeList { int alloc_employee; // 할당한 총 직원 수 int current_employee; // 현재 직원 수 Employee** employee_list; // 직원 데이터 public: EmployeeList(int alloc_employee) : alloc_employee(alloc_employee) { employee_list = new Employee*[alloc_employee]; current_employee = 0; } void add_employee(Employee* employee) { // 사실 current_employee 보다 alloc_employee 가 더 // 많아지는 경우 반드시 재할당을 해야 하지만, 여기서는 // 최대한 단순하게 생각해서 alloc_employee 는 // 언제나 current_employee 보다 크다고 생각한다. // (즉 할당된 크기는 현재 총 직원수 보다 많음) employee_list[current_employee] = employee; current_employee++; } int current_employee_num() { return current_employee; } void print_employee_info() { int total_pay = 0; for (int i = 0; i < current_employee; i++) { employee_list[i]->print_info(); total_pay += employee_list[i]->calculate_pay(); } std::cout << "총 비용 : " << total_pay << "만원 " << std::endl; } ~EmployeeList() { for (int i = 0; i < current_employee; i++) { delete employee_list[i]; } delete[] employee_list; } }; int main() { EmployeeList emp_list(10); emp_list.add_employee(new Employee("노홍철", 34, "평사원", 1)); emp_list.add_employee(new Employee("하하", 34, "평사원", 1)); emp_list.add_employee(new Manager("유재석", 41, "부장", 7, 12)); emp_list.add_employee(new Manager("정준하", 43, "과장", 4, 15)); emp_list.add_employee(new Manager("박명수", 43, "차장", 5, 13)); emp_list.add_employee(new Employee("정형돈", 36, "대리", 2)); emp_list.add_employee(new Employee("길", 36, "인턴", -2)); emp_list.print_employee_info(); return 0; }
성공적으로 컴파일 하였다면
실행 결과
노홍철 (평사원 , 34) ==> 250만원 하하 (평사원 , 34) ==> 250만원 유재석 (부장 , 41) ==> 550만원 정준하 (과장 , 43) ==> 400만원 박명수 (차장 , 43) ==> 450만원 정형돈 (대리 , 36) ==> 300만원 길 (인턴 , 36) ==> 100만원 총 비용 : 2300만원
와 같이 전부다 Employee 의 print_info 와 calculate_pay 함수가 호출되서 원래 결과와 달라집니다.
그런데 놀랍게도 이러한 문제를 5초 만에 해결할 수 있는 방법이 있습니다.
virtual 키워드
EmployeeList 문제를 해결하기 전에 좀 더 간단한 예시로 살펴보겠습니다.
#include <iostream> class Base { public: Base() { std::cout << "기반 클래스" << std::endl; } virtual void what() { std::cout << "기반 클래스의 what()" << std::endl; } }; class Derived : public Base { public: Derived() : Base() { std::cout << "파생 클래스" << std::endl; } void what() { std::cout << "파생 클래스의 what()" << std::endl; } }; int main() { Base p; Derived c; Base* p_c = &c; Base* p_p = &p; std::cout << " == 실제 객체는 Base == " << std::endl; p_p->what(); std::cout << " == 실제 객체는 Derived == " << std::endl; p_c->what(); return 0; }
성공적으로 컴파일 하였다면
실행 결과
기반 클래스 기반 클래스 파생 클래스 == 실제 객체는 Base == 기반 클래스의 what() == 실제 객체는 Derived == 파생 클래스의 what()
어라? 위 결과를 보셨다면 놀라움을 금치 못하셨을 것입니다.
Base* p_c = &c; Base* p_p = &p; std::cout << " == 실제 객체는 Base == " << std::endl; p_p->what(); std::cout << " == 실제 객체는 Derived == " << std::endl; p_c->what();
분명히 여기서 p_p 와 p_c 모두 Base 객체를 가리키는 포인터 입니다. 따라서, p_p->what() 와 p_c->what() 을 하면 모두 Base 객체의 what() 함수가 실행되서 둘 다 '기반' 라고 출력이 되어야만 했습니다.
그런데, 놀랍게도, 실제 p_p 와 p_c 가 무엇과 결합해 있는지 아는 것 처럼 (p_p 는 Base 객체를 가리키고, p_c 는 Derived 객체를 가리킴) 이에 따른 적절한 what 함수를 호출해준 것입니다.
이와 같은 일이 가능해진 이유는 바로;
class Base { public: Base() { std::cout << "기반 클래스" << std::endl; } virtual void what() { std::cout << "기반 클래스의 what()" << std::endl; } };
이 virtual 키워드 하나 때문입니다. 이 virtual 키워드는, 다음과 같은 역할을 합니다.
p_c->what();
위 코드를 실행시에 (런타임), 컴퓨터 입장에서;
"흠, p_c 는 Base 포인터니까 Base 의 what() 을 실행해야지" "어 근데 what 이 virtual 이네?" "잠깐. 이거 실제 Base 객체 맞어? 아니네 Derived 객체네" "그럼 Derived 의 what 을 실행해야지"
반면에
p_p->what();
였을 경우에는
"흠, p_c 는 Base 포인터니까 Base 의 what() 을 실행해야지" "어 근데 what 이 virtual 이네?" "잠깐. 이거 실제 Base 객체 맞어? 어 맞네." "Base 의 what 을 실행하자"
이렇게 컴파일 시에 어떤 함수가 실행될 지 정해지지 않고 런타임 시에 정해지는 일을 가리켜서 동적 바인딩(dynamic binding) 이라고 부릅니다. 즉,
p_c->what();
에서 Derived 의 what 을 실행할지, Base 의 what 을 실행하지 결정은 런타임에 이루어지게 됩니다. 물론 위 코드에선 컴파일 시에 무조건 p_c->what() 이 Derived 의 what 이 실행되도록 정해진 거 아니냐고 물을 수 있지만 다음과 같은 상황을 생각해보세요.
// i 는 사용자로부터 입력받는 변수 if (i == 1) { p_p = &c; } else { p_p = &p; } p_p->what();
이렇게 된다면 p_p->what() 이 어떤 what 일지에는 런타임에 정해지겠지요? 물론 동적 바인딩의 반대말로 정적 바인딩(static binding) 이란 말도 있습니다. 이는 컴파일 타임에 어떤 함수가 호출될 지 정해지는 것으로 여태까지 여러분이 알고 오셨던 함수에 해당합니다.
덧붙여서, virtual 키워드가 붙은 함수를 가상 함수(virtual function) 라고 부릅니다. 이렇게 파생 클래스의 함수가 기반 클래스의 함수를 오버라이드 하기 위해서는 두 함수의 꼴이 정확히 같아야 합니다.
override 키워드
#include <iostream> #include <string> class Base { std::string s; public: Base() : s("기반") { std::cout << "기반 클래스" << std::endl; } virtual void what() { std::cout << s << std::endl; } }; class Derived : public Base { std::string s; public: Derived() : s("파생"), Base() { std::cout << "파생 클래스" << std::endl; } void what() override { std::cout << s << std::endl; } };
C++ 11 에서는 파생 클래스에서 기반 클래스의 가상 함수를 오버라이드 하는 경우, override 키워드를 통해서 명시적으로 나타낼 수 있습니다.
void what() override { std::cout << s << std::endl; }
위 경우 Derived 클래스의 what 함수는 Base 클래스의 what 함수를 오버라이드 하므로, override 키워드를 통해 이를 알려주고 있습니다.
override 키워드를 사용하게 되면, 실수로 오버라이드를 하지 않는 경우를 막을 수 있습니다. 예를 들어서;
#include <iostream> #include <string> class Base { std::string s; public: Base() : s("기반") { std::cout << "기반 클래스" << std::endl; } virtual void incorrect() { std::cout << "기반 클래스 " << std::endl; } }; class Derived : public Base { std::string s; public: Derived() : Base(), s("파생") {} void incorrect() const { std::cout << "파생 클래스 " << std::endl; } }; int main() { Base p; Derived c; Base* p_c = &c; Base* p_p = &p; std::cout << " == 실제 객체는 Base == " << std::endl; p_p->incorrect(); std::cout << " == 실제 객체는 Derived == " << std::endl; p_c->incorrect(); return 0; }
성공적으로 컴파일 하였다면
실행 결과
기반 클래스 기반 클래스 == 실제 객체는 Base == 기반 클래스 == 실제 객체는 Derived == 기반 클래스
와 같이 incorrect 함수가 제대로 오버라이드 되지 않았음을 알 수 있습니다. 그 이유는 Base 의 incorrect 함수와 Derived 의 incorrect 함수는 거의 똑같이 생기기는 했지만 사실 다르기 때문입니다. 왜냐하면 Derived 의 incorrect 함수는 상수 함수 이고, Base 의 incorrect 는 아니기 때문이지요.
따라서 컴파일러 입장에서 두 함수는 다른 함수로 간주되므로, p_c->incorrect() 를 하였을 때 Derived 의 incorrect 함수가 Base 의 incorrect 함수를 오버라이드 하는 것이 아니라, 그냥 Base 의 incorrect 함수를 호출하는 셈이 됩니다.
만약에 여러분의 의도가 Derived 의 incorrect 함수가 기반 클래스를 오버라이드 하는 것이였다면 큰 문제가 될 것입니다. 이 버그는 컴파일 타임에 잡을 수 없게 되니까요.
하지만, 실제로 Derived 의 incorrect 함수를 기반 클래스의 incorrect 함수를 오버라이드 하기 위해서 만들었다면, override 키워드를 써야겠지요.
#include <iostream> #include <string> class Base { std::string s; public: Base() : s("기반") { std::cout << "기반 클래스" << std::endl; } virtual void incorrect() { std::cout << "기반 클래스 " << std::endl; } }; class Derived : public Base { std::string s; public: Derived() : Base(), s("파생") {} void incorrect() const override { std::cout << "파생 클래스 " << std::endl; } }; int main() { Base p; Derived c; Base* p_c = &c; Base* p_p = &p; std::cout << " == 실제 객체는 Base == " << std::endl; p_p->incorrect(); std::cout << " == 실제 객체는 Derived == " << std::endl; p_c->incorrect(); return 0; }
컴파일 하였다면
컴파일 오류
test.cc:19:8: error: 'void Derived::incorrect() const' marked 'override', but does not override
위와 같이 Derived 의 incorrect 함수가 override 한다고 써있지만, 실제로는 아무것도 오버라이드 하지 않는다고 오류가 발생하게 됩니다. 만일 const 키워드를 지워준다면
#include <iostream> #include <string> class Base { std::string s; public: Base() : s("기반") { std::cout << "기반 클래스" << std::endl; } virtual void incorrect() { std::cout << "기반 클래스 " << std::endl; } }; class Derived : public Base { std::string s; public: Derived() : Base(), s("파생") {} void incorrect() override { std::cout << "파생 클래스 " << std::endl; } }; int main() { Base p; Derived c; Base* p_c = &c; Base* p_p = &p; std::cout << " == 실제 객체는 Base == " << std::endl; p_p->incorrect(); std::cout << " == 실제 객체는 Derived == " << std::endl; p_c->incorrect(); return 0; }
성공적으로 컴파일 하였다면
실행 결과
기반 클래스 기반 클래스 == 실제 객체는 Base == 기반 클래스 == 실제 객체는 Derived == 파생 클래스
제대로 실행됨을 알 수 있습니다.
그렇다면 Employee 문제를 어떻게 해결할까
이제 여러분은 그동안 골머리를 썩여왔던 EmployeeList 문제도 해결할 수 있게 되었습니다. 단순히 Employee 클래스의 calculate_pay 함수와 print_info 함수 앞에 virtual 만 붙여주면 깔끔하게 정리 되지요.
#include <iostream> #include <string> class Employee { protected: std::string name; int age; std::string position; // 직책 (이름) int rank; // 순위 (값이 클 수록 높은 순위) public: Employee(std::string name, int age, std::string position, int rank) : name(name), age(age), position(position), rank(rank) {} // 복사 생성자 Employee(const Employee& employee) { name = employee.name; age = employee.age; position = employee.position; rank = employee.rank; } // 디폴트 생성자 Employee() {} virtual void print_info() { std::cout << name << " (" << position << " , " << age << ") ==> " << calculate_pay() << "만원" << std::endl; } virtual int calculate_pay() { return 200 + rank * 50; } }; class Manager : public Employee { int year_of_service; public: Manager(std::string name, int age, std::string position, int rank, int year_of_service) : year_of_service(year_of_service), Employee(name, age, position, rank) {} int calculate_pay() override { return 200 + rank * 50 + 5 * year_of_service; } void print_info() override { std::cout << name << " (" << position << " , " << age << ", " << year_of_service << "년차) ==> " << calculate_pay() << "만원" << std::endl; } }; class EmployeeList { int alloc_employee; // 할당한 총 직원 수 int current_employee; // 현재 직원 수 Employee** employee_list; // 직원 데이터 public: EmployeeList(int alloc_employee) : alloc_employee(alloc_employee) { employee_list = new Employee*[alloc_employee]; current_employee = 0; } void add_employee(Employee* employee) { // 사실 current_employee 보다 alloc_employee 가 더 // 많아지는 경우 반드시 재할당을 해야 하지만, 여기서는 // 최대한 단순하게 생각해서 alloc_employee 는 // 언제나 current_employee 보다 크다고 생각한다. // (즉 할당된 크기는 현재 총 직원수 보다 많음) employee_list[current_employee] = employee; current_employee++; } int current_employee_num() { return current_employee; } void print_employee_info() { int total_pay = 0; for (int i = 0; i < current_employee; i++) { employee_list[i]->print_info(); total_pay += employee_list[i]->calculate_pay(); } std::cout << "총 비용 : " << total_pay << "만원 " << std::endl; } ~EmployeeList() { for (int i = 0; i < current_employee; i++) { delete employee_list[i]; } delete[] employee_list; } }; int main() { EmployeeList emp_list(10); emp_list.add_employee(new Employee("노홍철", 34, "평사원", 1)); emp_list.add_employee(new Employee("하하", 34, "평사원", 1)); emp_list.add_employee(new Manager("유재석", 41, "부장", 7, 12)); emp_list.add_employee(new Manager("정준하", 43, "과장", 4, 15)); emp_list.add_employee(new Manager("박명수", 43, "차장", 5, 13)); emp_list.add_employee(new Employee("정형돈", 36, "대리", 2)); emp_list.add_employee(new Employee("길", 36, "인턴", -2)); emp_list.print_employee_info(); return 0; }
성공적으로 컴파일 하였다면
실행 결과
노홍철 (평사원 , 34) ==> 250만원 하하 (평사원 , 34) ==> 250만원 유재석 (부장 , 41, 12년차) ==> 610만원 정준하 (과장 , 43, 15년차) ==> 475만원 박명수 (차장 , 43, 13년차) ==> 515만원 정형돈 (대리 , 36) ==> 300만원 길 (인턴 , 36) ==> 100만원 총 비용 : 2500만원
와 같이 비록 Employee* 가 가리키고 있음에도 불구하고 Manager 면 Manager 의 함수를, Employee 면 Employee 의 함수를 잘 호출하고 있음을 알 수 있습니다. 물론 바뀐 것은 단 두 단어. virtual 키워들을 Employee 의 함수들 앞에 추가해놓은 것 뿐이지요.
employee_list[i]->print_info(); total_pay += employee_list[i]->calculate_pay();
이 두 부분은 employee_list[i] 가 Employee 냐 Manager 에 따라서 다르게 동작하게 됩니다. 이렇게 같은 print_info 함수를 호출했음에도 불구하고 어떤 경우는 Employee 의 것이, 어떤 경우는 Manager 의 것이 호출되는 일; 즉 하나의 메소드를 호출했음에도 불구하고 여러가지 다른 작업들을 하는 것을 바로 다형성(polymorphism) 이라고 부릅니다.
참고로, 다형성을 뜻하는 영어 단어인 polymorphism 은,여러개를 의미하는 그리스어 'poly' 와, 모습, 모양을 뜻하는 그리스어 'morphism' 에서 온 단어로 '여러가지 형태' 라는 의미 입니다.
자 그러면 이번 강좌는 여기에서 마치도록 하겠습니다. 아마도 virtual 키워드를 처음 접했더라면 머가 어떻게 되는지 많이 헷갈릴 수 있는데 꼭 여러번 테스트 프로그램을 만들어보아서 확실히 이해하고 넘어가도록 합시다 :)
생각해보기
문제 1
그렇다면 프로그램 내부적으로 virtual 함수들은 어떻게 처리될까요? 즉, 이 포인터가 어떠한 객체를 가리키는지 어떻게 알 수 있을까요? (난이도 : 上)

댓글을 불러오는 중입니다..