모두의 코드
씹어먹는 C++ - <10 - 2. C++ STL - 셋(set), 맵(map), unordered_set, unordered_map>
이번 강좌에서는
set,map,multiset,multimapunordered_set,unordered_map커스텀 클래스 객체를
set/map혹은unordered_set/map에 추가하기
에 대해 다룹니다.

안녕하세요 여러분! 지난 강좌에서 시퀀스 컨테이너들 (vector, list, deque) 에 대해서 다루어보았습니다. 시퀀스 컨테이너들은 말 그대로 '원소' 자체를 보관하는 컨테이너들 입니다.
이번 강좌에서는 다른 종류의 컨테이너인 연관 컨테이너(associative container) 에 대해서 다루어볼 것입니다. 연관 컨테이너는 시퀀스 컨테이너와는 다르게 키(key) - 값(value) 구조를 가집니다. 다시 말해 특정한 키를 넣으면 이에 대응되는 값을 돌려준다는 것이지요. 물론 템플릿 라이브러리 이기 때문이 키와 값 모두 임의의 타입의 객체가 될 수 있습니다.
예를 들어서 어떤 웹사이트에서 회원 관리를 한다고 생각해봅시다. 사용자의 로그인을 처리하기 위해서는 아이디를 키로 가지고, 비밀번호를 값으로 가지는 데이터 구조가 필요할 것입니다. 왜냐하면 사용자가 로그인을 할 때 올바르게 입력하였는지 확인하기 위해선, 입력한 아이디에 대응되어 있던 비밀번호를 가지고, 실제 사용자가 입력한 비밀번호와 비교를 해야 되기 때문이지요.
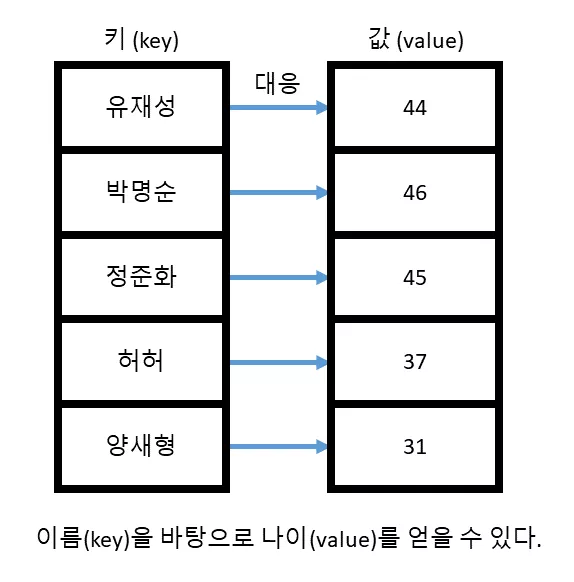
위 처럼 연관 컨테이너는 키를 바탕으로 이에 대응되는 값을 얻을 수 있는 구조 입니다.
우리는 위와 같이 주어진 자료에서 보통 두 가지 종류의 질문을 할 수 있습니다.
박명순이 데이터에 존재하나요? (특정 키가 연관 컨테이너에 존재하는지 유무) → True
만약 존재한다면 이에 대응되는 값이 무엇인가요? (특정 키에 대응되는 값이 무엇인지 질의) → 46
C++ 에서는 위 두 가지 작업을 처리할 수 있 C++ 에서는 위 두 가지 작업을 처리할 수 있는 연관 컨테이너라는 것을 제공합니다. 전자의 경우 셋(set) 과 멀티셋(multiset) 이고, 후자의 경우 맵(map) 과 멀티맵(multimap) 입니다. 물론 맵과 멀티맵을 셋 처럼 사용할 수 있습니다. 왜냐하면 해당하는 키가 맵에 존재하지 않으면 당연히 대응되는 값을 가져올 수 없기 때문이지요.
하지만 맵의 경우 셋 보다 사용하는 메모리가 크기 때문에 키의 존재 유무 만 궁금하다면 셋을 사용하는 것이 좋습니다. 그렇다면 셋 부터 어떻게 사용하는지 살펴보겠습니다.
셋(set)
#include <iostream> #include <set> template <typename T> void print_set(std::set<T>& s) { // 셋의 모든 원소들을 출력하기 std::cout << "[ "; for (typename std::set<T>::iterator itr = s.begin(); itr != s.end(); ++itr) { std::cout << *itr << " "; } std::cout << " ] " << std::endl; } int main() { std::set<int> s; s.insert(10); s.insert(50); s.insert(20); s.insert(40); s.insert(30); std::cout << "순서대로 정렬되서 나온다" << std::endl; print_set(s); std::cout << "20 이 s 의 원소인가요? :: "; auto itr = s.find(20); if (itr != s.end()) { std::cout << "Yes" << std::endl; } else { std::cout << "No" << std::endl; } std::cout << "25 가 s 의 원소인가요? :: "; itr = s.find(25); if (itr != s.end()) { std::cout << "Yes" << std::endl; } else { std::cout << "No" << std::endl; } }
성공적으로 컴파일 하였다면
실행 결과
순서대로 정렬되서 나온다 [ 10 20 30 40 50 ] 20 이 s 의 원소인가요? :: Yes 25 가 s 의 원소인가요? :: No
와 같이 나옵니다.
s.insert(10); s.insert(50); s.insert(20); s.insert(40); s.insert(30);
셋에 원소를 추가하기 위해서는 시퀀스 컨테이너 처럼 insert 함수를 사용하면 됩니다. 한 가지 다른점은, 시퀀스 컨테이너 처럼 '어디에' 추가할지에 대한 정보가 없다는 점입니다. 시퀀스 컨테이너가 상자 하나에 원소를 한 개 씩 담고, 각 상자에 번호를 매긴 것이라면, 셋은 그냥 큰 상자 안에 모든 원소들을 쑤셔 넣은 것이라 보면 됩니다. 그 상자 안에 원소가 어디에 있는지는 중요한게 아니고,그 상자 안에 원소가 '있냐/없냐' 만이 중요한 정보입니다.
셋에 원소를 추가하거나 지우는 작업은 에 처리됩니다. 시퀀스 컨테이너의 경우 임의의 원소를 지우는 작업이 으로 수행되었다는 점을 생각하면 훨씬 빠르다고 볼 수 있습니다.
template <typename T> void print_set(std::set<T>& s) { // 셋의 모든 원소들을 출력하기 std::cout << "[ "; for (typename std::set<int>::iterator itr = s.begin(); itr != s.end(); ++itr) { std::cout << *itr << " "; } std::cout << " ] " << std::endl; }
셋 역시 셋에 저장되어 있는 원소들에 접근하기 위해 반복자를 제공하며, 이 반복자는 BidirectionalIterator 입니다. 즉, 시퀀스 컨테이너의 리스트 처럼 임의의 위치에 있는 원소에 접근하는 것은 불가능 하고 순차적으로 하나 씩 접근하는 것 밖에 불가능 합니다.
한 가지 흥미로운 점은 우리 셋에 원소를 넣었을 때 10 -> 50 -> 20 -> 40 -> 30 으로 넣었지만 실제로 반복자로 원소들을 모두 출력했을 때 나온 순서는 10 -> 20 -> 30 -> 40 -> 50 순으로 나왔다는 점입니다.다시 말해 셋의 경우 내부에 원소를 추가할 때 정렬된 상태를 유지하며 추가합니다.
앞서 셋을 큰 상자라 생각하고 그 안에 원소들을 쑤셔 넣은 것이라 했는데, 실제로 마구 쑤셔넣지는 않고 순서를 지키면서 쑤셔 넣습니다. 이 때문에 시퀀스 컨테이너와는 다르게 원소를 추가하는 작업이 으로 진행됩니다.
또한 셋의 진가는 앞서 말했듯이 원소가 있냐 없냐를 확인할 때 드러납니다.
std::cout << "20 이 s 의 원소인가요? :: "; auto itr = s.find(20); if (itr != s.end()) { std::cout << "Yes" << std::endl; } else { std::cout << "No" << std::endl; }
셋에는 find 함수가 제공되며, 이 find 함수를 통해 이 셋에 원소가 존재하는지 아닌지 확인할 수 있습니다. 만일 해당하는 원소가 존재한다면 이를 가리키는 반복자를 리턴하고 (std::set<>::iterator 타입입니다) 만일 존재하지 않는다면 s.end() 를 리턴하게 되지요.
만일 벡터였다면 원소가 존재하는지 아닌지 확인하기 위해 벡터의 처음 부터 끝 까지 하나씩 비교해가면서 찾았어야 했겠죠. 만일 원소가 없었더라면 벡터에 있는 모든 원소를 확인하였을 것입니다 (즉 벡터에서 find 는 이라 볼 수 있습니다).
하지만셋의 경우 놀랍게도 으로 원소가 존재하는지 확인할 수 있습니다. 이것이 가능한 이유는 셋 내부적으로 원소들이 정렬된 상태를 유지하기 때문에 비교적 빠르게 원소의 존재 여무를 확인할 수 있습니다.
따서 20 을 찾았을 때 Yes 가 나오고 셋에 없는 원소인 25 를 찾는다면 No 가 출력됩니다.
셋이 이러한 방식으로 작업을 수행할 수 있는 이유는 바로 내부적으로 트리 구조로 구성되어 있기 때문입니다.
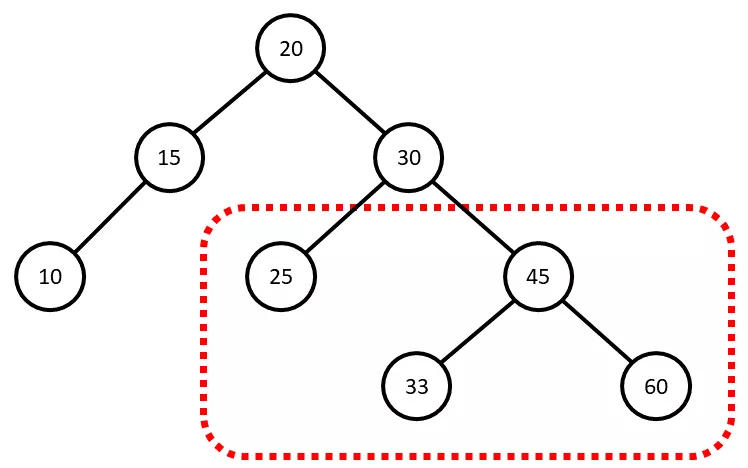
위 그림은 흔히 볼 수 있는 트리 구조를 나타냅니다. 각각의 원소들은 트리의 각 노드들에 저장되어 있고, 다음과 같은 규칙을 지키고 있습니다.
왼쪽에 오는 모든 노드들은 나보다 작다
오른쪽에 있는 모든 노드들은 나보다 크다
예를 들어 오른쪽의 30 을 살펴볼까요 (위 그림에서 점선으로 표시한 부분). 30 왼쪽에 오는 노드는 25 로 30 보다 작고, 오른쪽에 오는 노드들은 33, 45, 60 으로 모두 30 보다 큽니다. 어떤 노드들을 살펴보아도 이러한 규칙을 지키고 있음을 알 수 있습니다.
그렇다면 위 구조에서 25 를 찾으려면 어떻게 할까요?
일단 최상위 노드 (루트 노드라 합니다) 와 비교 : 25 > 20 → 오른쪽 노드로 간다
30 과 비교 : 25 < 30 → 왼쪽 노드로 간 30 과 비교 : 25 < 30 → 왼쪽 노드로 간다
25 와 비교 : 25 == 25 → 당첨 25 와 비교 : 25 == 25 → 당첨!
전체 원소 개수는 8개 이지만, 단 3번의 비교로 원소를 정확히 찾을 수 있습니다.
그렇다면 12 를 찾으려면 어떻게 할까요? 참고로 12 는 위 셋에 들어있지 않은 원소 입니다.
루트 노드와 비교 : 12 < 20 → 왼쪽 노드로 간다
15 와 비교 : 12 < 15 → 왼쪽 노드로 간 15 와 비교 : 12 < 15 → 왼쪽 노드로 간다
10 과 비교 : 12 > 10 → 오른쪽 노드로 가야하지만 오른쪽에 아무것도 없다. 따라서 이 원소는 존재하지 않는다 10 과 비교 : 12 > 10 → 오른쪽 노드로 가야하지만 오른쪽에 아무것도 없다. 따라서 이 원소는 존재하지 않는다.
만일 벡터 였다면 원소들을 처음 부터 끝까지 확인해봐야 했지만 셋의 경우 단 3번의 비교만으로 12 가 셋에 존재하는지 아닌지 여부를 판단할 수 있었습니다.
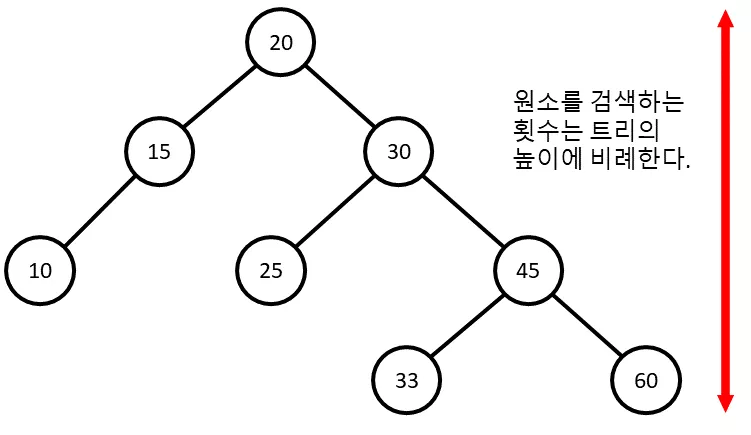
아마 깨달으신 분들도 있겠지만, 원소를 검색하는데 필요한 횟수는 트리의 높이와 정확히 일치합니다. 즉, 15 는 단 2번의 비교로 찾아낼 수 있고, 맨 밑에 있는 60 이나 33 의 경우 총 4번의 비교가 필요하겠지요. 따라서, 트리의 경우 최대한 모든 노드들을 꽉 채우는 것이 중요합니다. 예를 들어서
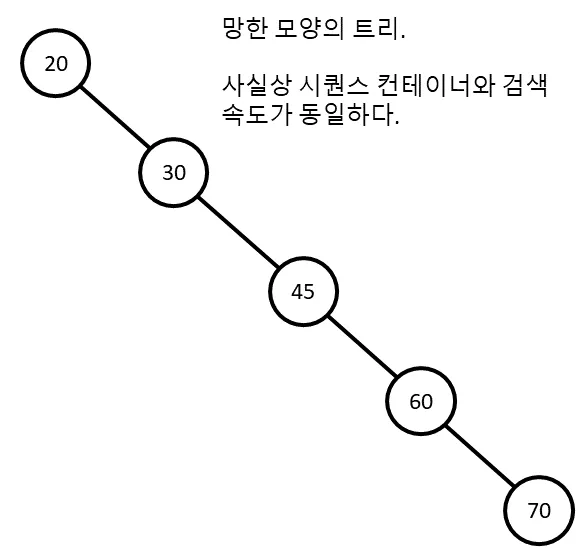
어쩌다 보니 트리가 위 처럼 되버렸다면 사실상 시퀀스 컨테이너와 검색 속도가 동일할 것입니다. 위와 같이 한쪽으로 아예 치우쳐버린 트리를 군형잡히지 않은 트리 (unbalanced tree) 라고 부릅니다. 실제 셋의 구현을 보면 위와 같은 상황이 발생하지 않도록 앞서 말한 두 개의 단순한 규칙 보다 더 많은 규칙들을 도입해서 트리를 항상 균형 잡히도록 유지하고 있습니다.
따라서 셋의 구현 상 으로 원소를 검색할 수 있다는 것이 보장됩니다. (궁금하신 분들만! 대부분의 셋 구현에서 사용하고 있는 트리 구조는 여기서 볼 수 있습니다)
또한 셋의 중요한 특징으로 바로 셋 안에는 중복된 원소들이 없다는 점이 있습니다.
#include <iostream> #include <set> template <typename T> void print_set(std::set<T>& s) { // 셋의 모든 원소들을 출력하기 std::cout << "[ "; for (const auto& elem : s) { std::cout << elem << " "; } std::cout << " ] " << std::endl; } int main() { std::set<int> s; s.insert(10); s.insert(20); s.insert(30); s.insert(20); s.insert(10); print_set(s); }
성공적으로 컴파일 하였다면
실행 결과
[ 10 20 30 ]
와 같이 나옵니다. 분명히
s.insert(10); s.insert(20); s.insert(30); s.insert(20); s.insert(10);
위와 같이 10 과 20 을 두 번씩 넣었지만 실제로는 한 번씩 밖에 나오지 않습니다. 이는 셋 자체적으로 이미 같은 원소가 있다면 이를 insert 하지 않기 때문입니다. 따라서 마지막 두 insert 작업은 무시되었을 것입니다.
참고로 시퀀스 컨테이너들과 마찬가지로 set 역시 범위 기반 for 문을 지원합니다. 원소들의 접근 순서는 반복자를 이용해서 접근하였을 때와 동일합니다.
만약에 중복된 원소를 허락하고 싶다면 멀티셋(multiset) 을 사용하면 되는데, 이는 후술 하겠습니다.
여러분이 만든 클래스 객체를 셋에 넣고 싶을 때
위와 같이 기본 타입들 말고, 여러분이 만든 클래스의 객체를 셋의 원소로 사용할 때 한 가지 주의해야 할 점이 있습니다. 아래는 할 일 (Todo) 목록을 저장하기 위해 셋을 사용하는 예시 입니다. Todo 클래스는 2 개를 멤버 변수로 가지는데 하나는 할 일의 중요도이고, 하나는 해야할 일의 설명 입니다.
#include <iostream> #include <set> #include <string> template <typename T> void print_set(std::set<T>& s) { // 셋의 모든 원소들을 출력하기 std::cout << "[ "; for (const auto& elem : s) { std::cout << elem << " " << std::endl; } std::cout << " ] " << std::endl; } class Todo { int priority; // 중요도. 높을 수록 급한것! std::string job_desc; public: Todo(int priority, std::string job_desc) : priority(priority), job_desc(job_desc) {} }; int main() { std::set<Todo> todos; todos.insert(Todo(1, "농구 하기")); todos.insert(Todo(2, "수학 숙제 하기")); todos.insert(Todo(1, "프로그래밍 프로젝트")); todos.insert(Todo(3, "친구 만나기")); todos.insert(Todo(2, "영화 보기")); }
그런데 컴파일 하였다면 아래와 같은 오류가 발생합니다.
컴파일 오류
binary '<': no operator found which takes a left-hand operand of type 'const Todo' (or there is no acceptable conversion)
왜 발생하였을까요? 생각을 해봅시다. 앞서 셋은 원소들을 저장할 때 내부적으로 정렬된 상태를 유지한다고 하였습니다. 즉 정렬을 하기 위해서는 반드시 원소 간의 비교를 수행해야 겠지요. 하지만, 우리의 Todo 클래스에는 operator< 가 정의되어 있지 않습니다. 따라서 컴파일러는 < 연산자를 찾을 수 없기에 위와 같은 오류를 뿜어내는 것입니다.
그렇다면 직접 Todo 클래스에 operator< 를 만들어주는 수 밖에 없습니다.
#include <iostream> #include <set> #include <string> template <typename T> void print_set(std::set<T>& s) { // 셋의 모든 원소들을 출력하기 for (const auto& elem : s) { std::cout << elem << " " << std::endl; } } class Todo { int priority; std::string job_desc; public: Todo(int priority, std::string job_desc) : priority(priority), job_desc(job_desc) {} bool operator<(const Todo& t) const { if (priority == t.priority) { return job_desc < t.job_desc; } return priority > t.priority; } friend std::ostream& operator<<(std::ostream& o, const Todo& td); }; std::ostream& operator<<(std::ostream& o, const Todo& td) { o << "[ 중요도: " << td.priority << "] " << td.job_desc; return o; } int main() { std::set<Todo> todos; todos.insert(Todo(1, "농구 하기")); todos.insert(Todo(2, "수학 숙제 하기")); todos.insert(Todo(1, "프로그래밍 프로젝트")); todos.insert(Todo(3, "친구 만나기")); todos.insert(Todo(2, "영화 보기")); print_set(todos); std::cout << "-------------" << std::endl; std::cout << "숙제를 끝냈다면!" << std::endl; todos.erase(todos.find(Todo(2, "수학 숙제 하기"))); print_set(todos); }
컴파일 하였다면
실행 결과
[ 중요도: 3] 친구 만나기 [ 중요도: 2] 수학 숙제 하기 [ 중요도: 2] 영화 보기 [ 중요도: 1] 농구 하기 [ 중요도: 1] 프로그래밍 프로젝트 ------------- 숙제를 끝냈다면! [ 중요도: 3] 친구 만나기 [ 중요도: 2] 영화 보기 [ 중요도: 1] 농구 하기 [ 중요도: 1] 프로그래밍 프로젝트
와 같이 잘 실행됩니다.
먼저 < 연산자를 어떻게 구현하였는지 살펴보겠습니다.
bool operator<(const Todo& t) const { if (priority == t.priority) { return job_desc < t.job_desc; } return priority > t.priority; }
셋이서 < 를 사용하기 위해서는 반드시 위와 같은 형태로 함수를 작성해야 합니다. 즉 const Todo 를 레퍼런스로 받는 const 함수로 말이지요. 이를 지켜야 하는 이유는 셋 내부적으로 정렬 시에 상수 반복자를 사용하기 때문입니다. (상수 반복자는 상수 함수만을 호출할 수 있습니다 . 이를 지켜야 하는 이유는 셋 내부적으로 정렬 시에 상수 반복자를 사용하기 때문입니다. (상수 반복자는 상수 함수만을 호출할 수 있습니다)
우리의 Todo < 연산자는 중요도가 다르면,
return priority > t.priority;
로 해서 중요도 값이 높은 일이 위로 가게 하였습니다. 만약 중요도가 같다면
return job_desc < t.job_desc;
로 비교해서 job_desc 가 사전상에서 먼저 오는것이 먼저 나오게 됩니다.
한 가지 유의해야 할 점은 셋 내부에서 두 개의 원소가 같냐 다르냐를 판별하기 위해서 == 를 이용하지 않는다는 점입니다. 두 원소 A 와 B 가 셋 내부에서 같다는 의미는 A.operator<(B) 와 B.operator<(A) 가 모두 false 라는 뜻입니다. (예를 들어서 a 와 b 가 값이 같다고 하면 a < b 가 false 이고 b < a 도 false 이므로 a == b 이라 생각함)
만약에 우리가 중요도가 같을 때 따로 처리하지 않고 그냥
bool operator<(const Todo& t) const { return priority > t.priority; }
게 했다면 어떻게 되었을까요? 그 결과는 아래와 같습니다.
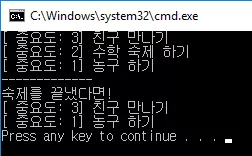
위와 같이 중요도가 같은 애들은 추가 되지 않습니다. 왜냐하면 앞서 말했듯이 셋에는 중복된 원소를 허락하지 않습니다. 그런데, 셋의 입장에서
Todo(1, "농구 하기")
와
Todo(1, "프로그래밍 프로젝트")
를 보았을 때
Todo(1, "농구 하기") < Todo(1, "프로그래밍 프로젝트"); Todo(1, "프로그래밍 프로젝트") > Todo(1, "농구 하기");
가 둘다 false 이므로, 두 개의 원소는 같은 것이라 생각하기 때문입니다! 따라서 나중에 추가된 '프로그래밍 프로젝트' 는 셋에 추가되지 않습니다. 같은 이유로 영화 보기도 추가되지 않습니다.
따라서 operator< 를 설계할 때 반드시 다른 객체는 operator< 상에서도 구분될 수 있도록 만들어야 합니다. 다시 말해 A 랑 B 가 다른 객체라면, A < B 혹은 B < A 중 하나는 반드시 True 여야 합니다.
엄밀히 말하자면 operator< 는 다음과 같은 조건들을 만족해야 합니다. (A 랑 B 가 다른 객체라면)
A < A는 거짓A < B != B < AA < B이고B < C이면A < CA == B이면A < B와 B< A둘 다 거짓A == B이고B == C이면A == C
위와 같은 조건을 만족하는 < 연산자는 strict weak ordering 을 만족한다고 합니다. 지켜야 할 조건들이 꽤나 많이 보이는데 사실, 상식적으로 operator< 를 설계하였다면 위 조건들은 모두 만족할 수 있습니다.
만약에, 위 중 하나라도 조건이 맞지 않는면 set 이 제대로 동작하지 않고 (컴파일 타임에는 오류가 발생하지 않습니다), 런타임 상에서 오류가 발생할 텐데 정말 디버깅 하기 힘들 것입니다 :(
마지막으로 보여드릴 것은, 클래스 자체에 operator< 를 두지 않더라도 셋을 사용하는 방법입니다. 예를 들어서 우리가 외부 라이브러리를 사용하는데, 만약에 그 라이브러리의 한 클래스의 객체를 셋에 저장하고 싶다고 해봅시다. 우리가 사용하는 외부 클래스에 operator< 가 정의되어 있지 않다는 점입니다. 이럴 경우, 셋을 사용하기 위해서는 따로 객체를 비교할 수 있는 방법을 알려주어야 합니다.
아래 예제를 보실까요.
#include <iostream> #include <set> #include <string> template <typename T, typename C> void print_set(std::set<T, C>& s) { // 셋의 모든 원소들을 출력하기 for (const auto& elem : s) { std::cout << elem << " " << std::endl; } } class Todo { int priority; std::string job_desc; public: Todo(int priority, std::string job_desc) : priority(priority), job_desc(job_desc) {} friend struct TodoCmp; friend std::ostream& operator<<(std::ostream& o, const Todo& td); }; struct TodoCmp { bool operator()(const Todo& t1, const Todo& t2) const { if (t1.priority == t2.priority) { return t1.job_desc < t2.job_desc; } return t1.priority > t2.priority; } }; std::ostream& operator<<(std::ostream& o, const Todo& td) { o << "[ 중요도: " << td.priority << "] " << td.job_desc; return o; } int main() { std::set<Todo, TodoCmp> todos; todos.insert(Todo(1, "농구 하기")); todos.insert(Todo(2, "수학 숙제 하기")); todos.insert(Todo(1, "프로그래밍 프로젝트")); todos.insert(Todo(3, "친구 만나기")); todos.insert(Todo(2, "영화 보기")); print_set(todos); std::cout << "-------------" << std::endl; std::cout << "숙제를 끝냈다면!" << std::endl; todos.erase(todos.find(Todo(2, "수학 숙제 하기"))); print_set(todos); }
성공적으로 컴파일 하였다면
실행 결과
[ 중요도: 3] 친구 만나기 [ 중요도: 2] 수학 숙제 하기 [ 중요도: 2] 영화 보기 [ 중요도: 1] 농구 하기 [ 중요도: 1] 프로그래밍 프로젝트 ------------- 숙제를 끝냈다면! [ 중요도: 3] 친구 만나기 [ 중요도: 2] 영화 보기 [ 중요도: 1] 농구 하기 [ 중요도: 1] 프로그래밍 프로젝트
와 같이 나옵니다. 달라진 점은 일단 Todo 클래스에서 operator< 가 삭제되었습니다. 하지만 셋을 사용하기 위해 반드시 Todo 객체간의 비교를 수행해야 하기 때문에 다음과 같은 클래스를 만들었습니다.
struct TodoCmp { bool operator()(const Todo& t1, const Todo& t2) const { if (t1.priority == t2.priority) { return t1.job_desc < t2.job_desc; } return t1.priority > t2.priority; } };
앞서 템플릿 첫 강좌에서 함수 객체를 배운 것이 기억 나시나요? 위 클래스는 정확히 함수 객체를 나타내고 있습니다. 이 TodoCmp 타입을
std::set<Todo, TodoCmp> todos;
위 처럼 set 에 두번째 인자로 넘겨주게 되면 셋은 이를 받아서 TodoCmp 클래스에 정의된 함수 객체를 바탕으로 모든 비교를 수행하게 됩니다. 실제로 set 클래스의 정의를 살펴보면;
template <class Key, class Compare = std::less<Key>, class Allocator = std::allocator<Key> // ← 후에 설명하겠습니다 > class set;
와 같이 생겼는데, 두 번째 인자로 Compare 를 받는 다는 것을 알 수 있습니다. (템플릿 디폴트 인자로 std::less<Key> 가 들어있는데 이는 Key 클래스의 operator< 를 사용한다는 의미와 같습니다. Compare 타입을 전달하지 않으면 그냥 Key 클래스의 operator< 로 비교를 수행합니다.)
결과적으로 셋은 원소의 삽입과 삭제를 원소의 탐색도 에 수행하는 자료 구조 입니다.
맵 (map)
맵은 셋과 거의 똑같은 자료 구조 입니다. 다만 셋의 경우 키만 보관했지만, 맵의 경우 키에 대응되는 값(value) 까지도 같이 보관하게 됩니다.
#include <iostream> #include <map> #include <string> template <typename K, typename V> void print_map(std::map<K, V>& m) { // 맵의 모든 원소들을 출력하기 for (auto itr = m.begin(); itr != m.end(); ++itr) { std::cout << itr->first << " " << itr->second << std::endl; } } int main() { std::map<std::string, double> pitcher_list; // 참고로 2017년 7월 4일 현재 투수 방어율 순위입니다. // 맵의 insert 함수는 pair 객체를 인자로 받습니다. pitcher_list.insert(std::pair<std::string, double>("박세웅", 2.23)); pitcher_list.insert(std::pair<std::string, double>("해커 ", 2.93)); pitcher_list.insert(std::pair<std::string, double>("피어밴드 ", 2.95)); // 타입을 지정하지 않아도 간단히 std::make_pair 함수로 // std::pair 객체를 만들 수 도 있습니다. pitcher_list.insert(std::make_pair("차우찬", 3.04)); pitcher_list.insert(std::make_pair("장원준 ", 3.05)); pitcher_list.insert(std::make_pair("헥터 ", 3.09)); // 혹은 insert 를 안쓰더라도 [] 로 바로 // 원소를 추가할 수 있습니다. pitcher_list["니퍼트"] = 3.56; pitcher_list["박종훈"] = 3.76; pitcher_list["켈리"] = 3.90; print_map(pitcher_list); std::cout << "박세웅 방어율은? :: " << pitcher_list["박세웅"] << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
니퍼트 3.56 박세웅 2.23 박종훈 3.76 장원준 3.05 차우찬 3.04 켈리 3.9 피어밴드 2.95 해커 2.93 헥터 3.09 박세웅 방어율은? :: 2.23
와 같이 나옵니다.
std::map<std::string, double> pitcher_list;
맵의 경우 템플릿 인자로 2 개를 가지는데, 첫번째는 키의 타입이고, 두 번째는 값의 타입입니다. 우리는 투수 이름을 키로 가지고 대응되는 값을 그 투수의 방어율로 하는 맵을 만들 예정입니다.
pitcher_list.insert(std::pair<std::string, double>("박세웅", 2.23)); pitcher_list.insert(std::pair<std::string, double>("해커 ", 2.93)); pitcher_list.insert(std::pair<std::string, double>("피어밴드 ", 2.95));
맵에 원소를 넣기 위해서는 반드시 std::pair 객체를 전달해야 합니다. std::pair 객체는 별다른게 아니고,
template <class T1, class T2> struct std::pair { T1 first; T2 second; };
로 생긴 단순히 2 개의 객체를 멤버로 가지는 객체 입니다. 문제는 std::pair 객체를 사용할 때 마다 위 처럼 템플릿 인자를 초기화 해야 하는데 꽤나 귀찮습니다. 그래서 STL 에서는 std::make_pair 함수를 제공해주는데,
pitcher_list.insert(std::make_pair("차우찬", 3.04)); pitcher_list.insert(std::make_pair("장원준 ", 3.05)); pitcher_list.insert(std::make_pair("헥터 ", 3.09));
이 함수는 인자로 들어오는 객체를 보고 타입을 추측해서 알아서 std::pair 객체를 만들어서 리턴해줍니다. 따라서 굳이 귀찮게 타입을 명시해줄 필요가 없습니다.
한 가지 재미있는 점은
// 혹은 insert 를 안쓰더라도 [] 로 바로 // 원소를 추가할 수 있습니다. pitcher_list["니퍼트"] = 3.56; pitcher_list["박종훈"] = 3.76; pitcher_list["켈리"] = 3.90;
맵의 경우 operator[] 를 이용해서 새로운 원소를 추가할 수 도 있습니다 (만일 해당하는 키가 맵에 없다면). 만일 키가 이미 존재하고 있다면 값이 대체될 것입니다.
template <typename K, typename V> void print_map(std::map<K, V>& m) { // 맵의 모든 원소들을 출력하기 for (auto itr = m.begin(); itr != m.end(); ++itr) { std::cout << itr->first << " " << itr->second << std::endl; } }
맵의 경우도 셋과 마찬가지로 반복자를 이용해서 순차적으로 맵에 저장되어 있는 원소들을 탐색할 수 있습니다. 참고로 셋의 경우 *itr 가 저장된 원소를 바로 가리켰는데, 맵의 경우 반복자가 맵에 저장되어 있는 std::pair 객체를 가리키게 됩니다. 따라서 itr->first 를 하면 해당 원소의 키를, itr->second 를 하면 해당 원소의 값을 알 수 있습니다.
참고로 해당 for 문을 범위 기반 for 문으로 바꿔본다면 아래와 같습니다.
template <typename K, typename V> void print_map(std::map<K, V>& m) { // kv 에는 맵의 key 와 value 가 std::pair 로 들어갑니다. for (const auto& kv : m) { std::cout << kv.first << " " << kv.second << std::endl; } }
반복자를 이용한 버전과 매우 유사하게, 맵의 키와 대응되는 원소를 first 와 second 를 이용해서 참조할 수 있습니다. 이 역시 반복자를 사용한 형태보다 더 간단하므로 권장됩니다.
std::cout << "박세웅 방어율은? :: " << pitcher_list["박세웅"] << std::endl;
만약에 맵에 저장된 값을 찾고 싶다면 간단히 [] 연산자를 이용하면 됩니다. [] 연산자는 인자로 키를 받아서 이를 맵에서 찾아서 대응되는 값을 돌려줍니다.
하지만, [] 연산자를 사용할 때 주의해야 할 점이 있습니다.
#include <iostream> #include <map> #include <string> template <typename K, typename V> void print_map(const std::map<K, V>& m) { // kv 에는 맵의 key 와 value 가 std::pair 로 들어갑니다. for (const auto& kv : m) { std::cout << kv.first << " " << kv.second << std::endl; } } int main() { std::map<std::string, double> pitcher_list; pitcher_list["오승환"] = 3.58; std::cout << "류현진 방어율은? :: " << pitcher_list["류현진"] << std::endl; std::cout << "-----------------" << std::endl; print_map(pitcher_list); }
성공적으로 컴파일 하였다면
실행 결과
류현진 방어율은? :: 0 ----------------- 류현진 0 오승환 3.58
와 같이 나옵니다.
pitcher_list["오승환"] = 3.58;
일단 위와 같이 pitcher_list 에 오승환의 방어율만 추가하였기 때문에 류현진의 방어율을 검색하면 아무것도 나오지 않는게 정상입니다. 그런데,
std::cout << "류현진 방어율은? :: " << pitcher_list["류현진"] << std::endl;
위 처럼 류현진의 방어율을 맵에서 검색하였을 때, 0 이라는 값이 나왔습니다. 없는 값을 참조하였으니 오류가 발생해야 정상인데 오히려 값을 돌려주었네요.이는 [] 연산자가, 맵에 없는 키를 참조하게 되면, 자동으로 값의 디폴트 생성자를 호출해서 원소를 추가해버리기 때문입니다.
double 의 디폴트 생성자의 경우 그냥 변수를 0 으로 초기화 해버립니다. 따라서 되도록이면 find 함수로 원소가 키가 존재하는지 먼저 확인 후에, 값을 참조하는 것이 좋습니다. 아래는 find 함수를 이용해서 안전한게 키에 대응되는 값을 찾는 방법입니다.
#include <iostream> #include <map> #include <string> template <typename K, typename V> void print_map(const std::map<K, V>& m) { // kv 에는 맵의 key 와 value 가 std::pair 로 들어갑니다. for (const auto& kv : m) { std::cout << kv.first << " " << kv.second << std::endl; } } template <typename K, typename V> void search_and_print(std::map<K, V>& m, K key) { auto itr = m.find(key); if (itr != m.end()) { std::cout << key << " --> " << itr->second << std::endl; } else { std::cout << key << "은(는) 목록에 없습니다" << std::endl; } } int main() { std::map<std::string, double> pitcher_list; pitcher_list["오승환"] = 3.58; print_map(pitcher_list); std::cout << "-----------------" << std::endl; search_and_print(pitcher_list, std::string("오승환")); search_and_print(pitcher_list, std::string("류현진")); }
성공적으로 컴파일 하였다면
실행 결과
오승환 3.58 ----------------- 오승환 --> 3.58 류현진은(는) 목록에 없습니다
와 같이 나옵니다.
template <typename K, typename V> void search_and_print(const std::map<K, V>& m, K key) { auto itr = m.find(key); if (itr != m.end()) { std::cout << key << " --> " << itr->second << std::endl; } else { std::cout << key << "은(는) 목록에 없습니다" << std::endl; } }
위 처럼 find 함수는 맵에서 해당하는 키를 찾아서 이를 가리키는 반복자를 리턴합니다. 만약에, 키가 존재하지 않는다면 end() 를 리턴합니다.
마지막으로 짚고 넘어갈 점은 맵 역시 셋 처럼 중복된 원소를 허락하지 않는다는 점입니다. 이미, 같은 키가 원소로 들어 있다면 나중에 오는 insert 는 무시됩니다.
#include <iostream> #include <map> #include <string> template <typename K, typename V> void print_map(const std::map<K, V>& m) { // kv 에는 맵의 key 와 value 가 std::pair 로 들어갑니다. for (const auto& kv : m) { std::cout << kv.first << " " << kv.second << std::endl; } } int main() { std::map<std::string, double> pitcher_list; // 맵의 insert 함수는 std::pair 객체를 인자로 받습니다. pitcher_list.insert(std::pair<std::string, double>("박세웅", 2.23)); pitcher_list.insert(std::pair<std::string, double>("박세웅", 2.93)); print_map(pitcher_list); // 2.23 이 나올까 2.93 이 나올까? std::cout << "박세웅 방어율은? :: " << pitcher_list["박세웅"] << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
박세웅 2.23 박세웅 방어율은? :: 2.23
와 같이 먼저 insert 된 원소가 나오게 됩니다. 즉, 이미 같은 키를 가지는 원소가 있다면 그 insert 작업은 무시됩니다. 만약에, 원소에 대응되는 값을 바꾸고 싶다면 insert 를 하지 말고, [] 연산자로 대응되는 값을 바꿔주면 됩니다.
멀티셋(multiset)과 멀티맵(multimap)
앞서 셋과 맵 모두 중복된 원소를 허락하지 않습니다. 만일, 이미 원소가 존재하고 있는데 insert 를 하였으면 무시가 되었지요. 하지만 멀티셋과 멀티맵은 중복된 원소를 허락합니다.
#include <iostream> #include <set> #include <string> template <typename K> void print_set(const std::multiset<K>& s) { // 셋의 모든 원소들을 출력하기 for (const auto& elem : s) { std::cout << elem << std::endl; } } int main() { std::multiset<std::string> s; s.insert("a"); s.insert("b"); s.insert("a"); s.insert("c"); s.insert("d"); s.insert("c"); print_set(s); }
성공적으로 컴파일 하였다면
실행 결과
a a b c c d
와 같이 나옵니다. 만약에 기존의 set 이였다면 그냥 a,b,c,d 이렇게 나왔어야 하지만, 멀티셋의 경우 중복된 원소를 허락하기 때문에 insert 한 모든 원소들이 쭈르륵 나오게 됩니다.
#include <iostream> #include <map> #include <string> template <typename K, typename V> void print_map(const std::multimap<K, V>& m) { // 맵의 모든 원소들을 출력하기 for (const auto& kv : m) { std::cout << kv.first << " " << kv.second << std::endl; } } int main() { std::multimap<int, std::string> m; m.insert(std::make_pair(1, "hello")); m.insert(std::make_pair(1, "hi")); m.insert(std::make_pair(1, "ahihi")); m.insert(std::make_pair(2, "bye")); m.insert(std::make_pair(2, "baba")); print_map(m); // 뭐가 나올까요? std::cout << "--------------------" << std::endl; std::cout << m.find(1)->second << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
1 hello 1 hi 1 ahihi 2 bye 2 baba -------------------- hello
와 같이 나옵니다.
일단 맵 과는 다르게, 한 개의 키에 여러개의 값이 대응될 수 있다는 것은 알 수 있습니다. 하지만 이 때문에 [] 연산자를 멀티맵의 경우 사용할 수 없습니다. 왜냐하면 예를 들어서
m[1]
을 했을 때 "hello" 를 리턴해야할지, 아니면 "hi" 를 리턴해야 할 지 알 수 없기 때문이지요. 따라서 멀티맵의 경우 아예 [] 연산자를 제공하지 않습니다. 그렇다면
std::cout << m.find(1)->second << std::endl;
위 처럼 find 함수를 사용했을 때 무엇을 리턴할까요? 일단 해당하는 키가 없으면 m.end() 를 리턴합니다. 그렇다면 위 경우 1 이라는 키에 3 개의 문자열이 대응되어 있는데 어떤거를 리턴해야 할까요? 제일 먼저 insert 한것? 아니면 문자열 중에서 사전 순으로 가장 먼저 오는 것?
사실 C++ 표준을 읽어보면 무엇을 리턴하라고 정해놓지 않았습니다. 즉, 해당되는 값들 중 아무 거나 리턴해도 상관 없다는 뜻입니다. 위 경우 hello 가 나왔지만, 다른 라이브러리를 쓰는 경우 hi 가 나올 수 도 있고, ahihi 가 나올 수 도 있습니다.
그렇다면 1 에 대응되는 값들이 뭐가 있는지 어떻게 알까요? 이를 위해 멀티맵은 다음과 같은 함수를 제공하고 있습니다.
#include <iostream> #include <map> #include <string> template <typename K, typename V> void print_map(const std::multimap<K, V>& m) { // 맵의 모든 원소들을 출력하기 for (const auto& kv : m) { std::cout << kv.first << " " << kv.second << std::endl; } } int main() { std::multimap<int, std::string> m; m.insert(std::make_pair(1, "hello")); m.insert(std::make_pair(1, "hi")); m.insert(std::make_pair(1, "ahihi")); m.insert(std::make_pair(2, "bye")); m.insert(std::make_pair(2, "baba")); print_map(m); std::cout << "--------------------" << std::endl; // 1 을 키로 가지는 반복자들의 시작과 끝을 // std::pair 로 만들어서 리턴한다. auto range = m.equal_range(1); for (auto itr = range.first; itr != range.second; ++itr) { std::cout << itr->first << " : " << itr->second << " " << std::endl; } }
성공적으로 컴파일 하였다면
실행 결과
1 hello 1 hi 1 ahihi 2 bye 2 baba -------------------- 1 : hello 1 : hi 1 : ahihi
와 같이 나옵니다.
auto range = m.equal_range(1);
equal_range 함수의 경우 인자로 멀티맵의 키를 받은 뒤에, 이 키에 대응되는 원소들의 반복자들 중에서시작과 끝 바로 다음을 가리키는 반복자를 std::pair 객체로 만들어서 리턴합니다. 즉, begin() 과 end() 를 std::pair 로 만들어서 세트로 리턴한다고 볼 수 있겠지요. 다만, first 로 시작점을, second 로 끝점 바로 뒤를 알 수 있습니다. 왜 끝점 바로 뒤를 가리키는 반복자를 리턴하는지는 굳이 설명 안해도 알겠죠?
for (auto itr = range.first; itr != range.second; ++itr) { std::cout << itr->first << " : " << itr->second << " " << std::endl; }
따라서 위 처럼 1 에 대응되는 모든 원소들을 볼 수 있게 됩니다.
정렬되지 않은 셋과 맵 (unordered_set, unordered_map)
unordered_set 과 unordered_map (한글로 하면 너무 길어서 그냥 영문으로 표기하겠습니다) 은 C++ 11 에 추가된 비교적 최근 나온 컨테이너들 입니다 (위에것들은 모두 C++ 98 에 추가되었었죠).
이 두 개의 컨테이너는 이름에서도 알 수 있듯이 원소들이 정렬되어 있지 않습니다.
이 말이 무슨 말이냐면, 셋이나 맵의 경우 원소들이 순서대로 정렬되어서 내부에 저장되지만, unordered_set 과 unordered_map 의 경우 원소들이 순서대로 정렬되서 들어가지 않는다는 뜻입니다. 따라서 반복자로 원소들을 하나씩 출력해보면 거의 랜덤한 순서로 나오는 것을 볼 수 있습니다.
#include <iostream> #include <string> #include <unordered_set> template <typename K> void print_unordered_set(const std::unordered_set<K>& m) { // 셋의 모든 원소들을 출력하기 for (const auto& elem : m) { std::cout << elem << std::endl; } } int main() { std::unordered_set<std::string> s; s.insert("hi"); s.insert("my"); s.insert("name"); s.insert("is"); s.insert("psi"); s.insert("welcome"); s.insert("to"); s.insert("c++"); print_unordered_set(s); }
성공적으로 컴파일 하였다면
실행 결과
c++ to my name hi is psi welcome
와 같이 나옵니다.
실제로 unordered_set 의 모든 원소들을 반복자로 출력해보면 딱히 순서대로 나오는 것 같지는 않습니다. 원소를 넣은 순서도 아니고, string 문자열 순서도 아니고 그냥 랜덤한 순서 입니다.
그런데 이 unordered_set 에 한 가지 놀라운 점이 있습니다. 바로 insert, erase, find 모두가 으로 수행된다는 점입니다! 셋이나 맵의 경우 이었지만, unordered_set 과 unordered_map 의 경우 상수 시간에 원소를 삽입하고, 검색할 수 있습니다.
이 놀라운 일이 어떻게 가능한건지 unordered_set 과 unordered_map 이 어떻게 구현되었는지 살펴보면 알 수 있습니다.
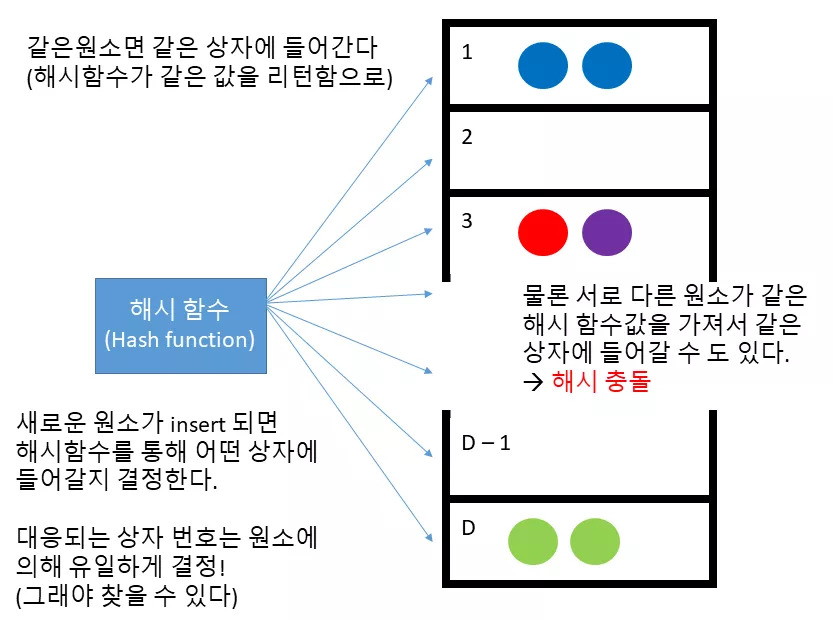
해시 함수(Hash function)
unordered_set 과 unordered_map 은 원소를 삽입하거나 검색 하기 위해 먼저 해시 함수라는 것을 사용합니다 (사실 그래서 원래 hashset 이나 hashmap 이란 이름을 붙이려고 했지만 이미 이러한 이름을 너무 많이 사용하고 있어서 충돌을 피하기 위해 저런 이름을 골랐다고 합니다).
해시 함수란 임의의 크기의 데이터를 고정된 크기의 데이터로 대응시켜주는 함수라고 볼 수 있습니다. 이 때 보통 고정된 크기의 데이터라고 하면 일정 범위의 정수값을 의미합니다.
unordered_set 과 unordered_map 의 경우, 해시함수는 1 부터 D (= 상자의 수)까지의 값을 반환하고 그 해시값 (해시 함수로 계산한 값)을 원소를 저장할 상자의 번호로 삼게 됩니다. 해시 함수는 구조상 최대한 1 부터 D 까지 고른 값을 반환하도록 설계되었습니다. 따라서 모든 상자를 고루 고루 사용할 수 있게 되지요.
해시 함수의 가장 중요한 성질은, 만약에 같은 원소를 해시 함수에 전달한다면 같은 해시값을 리턴한다는 점입니다. 이 덕분에 원소의 탐색을 빠르게 수행할 수 있습니다.
예를 들어 사용자가 파란공이 unordered_set 에 들어있는지 아닌지 확인한다고 해봅시다. 파란공을 해시 함수에 대입하면 1 을 리턴합니다. 따라서 1 번 상자를 살펴보면 이미 파란공이 있는 것을 알 수 있지요. 따라서 파란공이 unordered_set 에 이미 존재하고 있음을 알 수 있습니다.
그런데 재미있는 점은 해시 함수가 해시값 계산을 상수 시간에 처리한다는 점입니다. 따라서 unordered_set 과 unordered_map 모두 탐색을 상수 시간에 처리할 수 있습니다.
물론 빨간색 공과 보라색 공 처럼 다른 원소임에도 불구하고 같은 해시값을 갖는 경우가 있을 것입니다. 이를 해시 충돌(hash collision) 이라고 하는데, 이 경우 같은 상자에 다른 원소들이 들어있게 됩니다.
따라서 만약에 보라색 공이 이 셋에 포함되어 있는지 확인하고 싶다면 먼저 보라색 공의 해시값을 계산 한 뒤에, 해당하는 상자에 있는 모든 원소들을 탐색해보아야 할 것입니다.
해시 함수는 최대한 1 부터 N 까지 고른 값을 반환하도록 설계되었습니다. 뿐만 아니라 상자의 수도 충분히 많아야 상수 시간 탐색을 보장할 수 있습니다. 하지만 그럼에도 운이 매우 매우 나쁘다면 다른 색들의 공이 모두 1 번 상자에 들어갈 수 도 있습니다. 이 경우 탐색이 은 커녕 (여기서 n 은 상자의 개수가 아니라 원소의 개수) 으로 실행될 것입니다.
따라서 unordered_set 과 unordered_map 의 경우 평균적으로 시간으로 원소의 삽입/탐색을 수행할 수 있지만 최악의 경우 으로 수행될 수 있습니다. (그냥 set 과 map 의 경우 평균도 최악의 경우에도 으로 실행됩니다)
이 때문에 보통의 경우에는 그냥 안전하게 맵이나 셋을 사용하고, 만약에 최적화가 매우 필요한 작업일 경우에만 해시 함수를 잘 설계해서 unordered_set 과 unordered_map 을 사용하는 것이 좋습니다.
또한 처음부터 많은 개수의 상자를 사용할 수 없기 때문에 (메모리를 낭비할 순 없으므로..) 상자의 개수는 삽입되는 원소가 많아짐에 따라 점진적으로 늘어나게 됩니다. 문제는 상자의 개수가 늘어나면 해시 함수를 바꿔야 하기 때문에 (더 많은 값들을 해시값으로 반환할 수 있도록) 모든 원소들을 처음부터 끝 까지 다시 insert 해야 합니다. 이를 rehash 라 하며 만큼의 시간이 걸립니다.
#include <iostream> #include <string> #include <unordered_set> template <typename K> void print_unordered_set(const std::unordered_set<K>& m) { // 셋의 모든 원소들을 출력하기 for (const auto& elem : m) { std::cout << elem << std::endl; } } template <typename K> void is_exist(std::unordered_set<K>& s, K key) { auto itr = s.find(key); if (itr != s.end()) { std::cout << key << " 가 존재!" << std::endl; } else { std::cout << key << " 가 없다" << std::endl; } } int main() { std::unordered_set<std::string> s; s.insert("hi"); s.insert("my"); s.insert("name"); s.insert("is"); s.insert("psi"); s.insert("welcome"); s.insert("to"); s.insert("c++"); print_unordered_set(s); std::cout << "----------------" << std::endl; is_exist(s, std::string("c++")); is_exist(s, std::string("c")); std::cout << "----------------" << std::endl; std::cout << "'hi' 를 삭제" << std::endl; s.erase(s.find("hi")); is_exist(s, std::string("hi")); }
성공적으로 컴파일 하였다면
실행 결과
c++ to my name hi is psi welcome ---------------- c++ 가 존재! c 가 없다 ---------------- 'hi' 를 삭제 hi 가 없다
와 같이 나옵니다.
template <typename K> void is_exist(std::unordered_set<K>& s, K key) { auto itr = s.find(key); if (itr != s.end()) { std::cout << key << " 가 존재!" << std::endl; } else { std::cout << key << " 가 없다" << std::endl; } }
일단 위에서 볼 수 있듯이, unordered_set 과 unordered_map 모두 find 함수를 지원하며, 사용법은 그냥 셋과 정확히 동일합니다. find 함수의 경우 만일 해당하는 원소가 존재한다면 이를 가리키는 반복자를, 없다면 end 를 리턴합니다.
s.erase(s.find("hi")); is_exist(s, std::string("hi"));
또한 원소를 제거하고 싶다면 간단히 find 함수로 원소를 가리키는 반복자를 찾은 뒤에, 이를 전달하면 됩니다.
내가 만든 클래스를 `unordered_set/unordered_map` 의 원소로 넣고 싶을 때
그렇다면 여러분이 만든 클래스를 직접 unordered_set 혹은 unordered_map 에 넣으려면 어떻게 해야 할까요? 안타깝게도 셋이나 맵에 넣는것 보다 훨씬 어렵습니다. 왜냐하면 먼저 내 클래스의 객체를 위한 '해시 함수'를 직접 만들어줘야 하기 때문입니다. (그렇기 때문에 셋과 맵을 사용하는 것을 권장하는 것입니다!)
물론 셋이나 맵 과는 다르게 순서대로 정렬하지 않기 때문에 operator< 는 필요하지 않습니다. 하지만 operator== 는 필요한데, 왜냐하면 해시 충돌 발생 시에 상자안에 있는 원소들과 비교를 해야하기 때문이지요.
한 가지 다행인 점은 C++ 에서 기본적인 타입들에 대한 해시 함수들을 제공하고 있습니다. 우리는 이들을 잘만 이용하기만 하면 됩니다.
class Todo { int priority; // 중요도. 높을 수록 급한것! std::string job_desc; public: Todo(int priority, std::string job_desc) : priority(priority), job_desc(job_desc) {} };
그렇다면 위 Todo 클래스의 해시 함수를 만들어보겠습니다. 기본적으로 unordered_set 과 unordered_map 은 해시 함수 계산을 위해 hash 함수 객체를 사용합니다. hash 함수 객체는 아래와 같이 생겼습니다.
예를 들어 string 함수의 해시값을 계산하고 싶다면
hash<string> hash_fn; size_t hash_val = hash_fn(str); // str 의 해시값 계산
위와 같이 수행하게 되는 것이지요. string 을 템플릿 인자로 받는 hash_fn 객체를 만든 뒤에, (Functor 입니다) 마치 함수를 사용하는 것처럼 사용하면 됩니다.
따라서 Todo 함수의 해시 함수를 계산하는 함수 객체를 만들기 위해 다음과 같이 hash 클래스의 Todo 특수화 버전을 만들어줘야 합니다.
// hash 클래스의 Todo 템플릿 특수화 버전! template <> struct hash<Todo> { size_t operator()(const Todo& t) const { // 해시 계산 } };
해시 함수는 객체의 operator() 를 오버로드하면 되고 std::size_t 타입을 리턴하면 됩니다. 보통 size_t 타입은 int 랑 동일한데, 이 말은 해시값으로 0 부터 4294967295 까지 가능하다는 뜻입니다. 물론 그렇다고 해서 이 만큼의 상자를 사용하는 것은 아니고, 현재 컨테이너가 사용하고 있는 상자 개수로 나눈 나머지를 상자 번호로 사용하겠지요.
#include <functional> #include <iostream> #include <string> #include <unordered_set> template <typename K> void print_unordered_set(const std::unordered_set<K>& m) { // 셋의 모든 원소들을 출력하기 for (const auto& elem : m) { std::cout << elem << std::endl; } } template <typename K> void is_exist(std::unordered_set<K>& s, K key) { auto itr = s.find(key); if (itr != s.end()) { std::cout << key << " 가 존재!" << std::endl; } else { std::cout << key << " 가 없다" << std::endl; } } class Todo { int priority; // 중요도. 높을 수록 급한것! std::string job_desc; public: Todo(int priority, std::string job_desc) : priority(priority), job_desc(job_desc) {} bool operator==(const Todo& t) const { if (priority == t.priority && job_desc == t.job_desc) return true; return false; } friend std::ostream& operator<<(std::ostream& o, const Todo& t); friend struct std::hash<Todo>; }; // Todo 해시 함수를 위한 함수객체(Functor) // 를 만들어줍니다! namespace std { template <> struct hash<Todo> { size_t operator()(const Todo& t) const { hash<string> hash_func; return t.priority ^ (hash_func(t.job_desc)); } }; } // namespace std std::ostream& operator<<(std::ostream& o, const Todo& t) { o << "[중요도 : " << t.priority << " ] " << t.job_desc; return o; } int main() { std::unordered_set<Todo> todos; todos.insert(Todo(1, "농구 하기")); todos.insert(Todo(2, "수학 숙제 하기")); todos.insert(Todo(1, "프로그래밍 프로젝트")); todos.insert(Todo(3, "친구 만나기")); todos.insert(Todo(2, "영화 보기")); print_unordered_set(todos); std::cout << "----------------" << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
[중요도 : 2 ] 영화 보기 [중요도 : 1 ] 프로그래밍 프로젝트 [중요도 : 3 ] 친구 만나기 [중요도 : 1 ] 농구 하기 [중요도 : 2 ] 수학 숙제 하기 ----------------
와 같이 나옵니다.
먼저 Todo 를 위해 정의한 해시 함수를 살펴보도록 하겠습니다.
// Todo 해시 함수를 위한 함수객체(Functor) // 를 만들어줍니다! namespace std { template <> struct hash<Todo> { size_t operator()(const Todo& t) const { hash<string> hash_func; return t.priority ^ (hash_func(t.job_desc)); } }; } // namespace std
다행이도 C++ STL 에서는 기본적인 타입들 (int, std::string 등등) 에 대한 해시 함수를 제공하기 때문에 우리의 Todo 클래스의 해시 함수는 이들을 잘 사용해서 짬뽕만 시키면 됩니다. 일단 priority 는 int 값 이므로 그냥 해시값 자체로 쓰기로 하고, string 의 해시값은 hash_func 객체로 이용해서 계산하면 됩니다
결과적으로 두 해시값을 짬뽕 시키기 위해서 XOR 연산을 이용하였습니다.
참고로 왜 hash 클래스가 namespace std 안에 정의되어 있냐면 (이미 위에서 using namespace std 를 했음에도 불구하고), 특정 namespace 안에 새로운 클래스/함수를 추가하기 위해서는 위처럼 명시적으로 namespace (이름) 를 써줘야만 합니다. (여기를 참고)
그리고 마지막으로 아래와 같이 간단히 == 연산자를 추가해주면 됩니다.
bool operator==(const Todo& t) const { if (priority == t.priority && job_desc == t.job_desc) return true; return false; }
그럼 위 처럼 Todo 객체를 마음껏 unordered_set 에서 사용할 수 있게 됩니다!
주의 사항
해시 함수를 직접 제작하는 일은 꽤나 어렵습니다. 가장 큰 이유로, unordered_set 이나 unordered_map 이 제대로 된 성능을 발휘하기 위해서는 해시 함수가 입력 받은 키를 잘 흝뿌려야 합니다.
만일 해시 함수의 결과가 특정 범위의 값에게만 집중되어 있다면, 해시 함수를 이용한 컨테이너의 성능이 그냥 map 이나 set 보다 훨씬 못하니만이 되게 됩니다. 특히 악의적인 사용자가 해당 허점을 이용해서 프로그램의 성능을 저하시킬 수도 있겠지요.
따라서 가장 권장하는 방식은 여기 에 나온 기본 타입들의 대한 해시 함수들을 사용할 것이고, 해시 함수의 성능을 정확히 검증할 수 없다면, map 이나 set 을 사용하는 것이 나을 것입니다.
그렇다면 뭘 써야되?
아래와 같이 간단히 생각하시면 됩니다.
데이터의 존재 유무 만 궁금할 경우 →
set중복 데이터를 허락할 경우 →
multiset(insert, erase, find모두 . 최악의 경우에도 )데이터에 대응되는 데이터를 저장하고 싶은 경우 →
map중복 키를 허락할 경우 →
multimap(insert, erase, find모두 . 최악의 경우에도 )속도가 매우매우 중요해서 최적화를 해야하는 경우 →
unordered_set,unordered_map(insert, erase, find 모두 . 최악의 경우엔 그러므로 해시함수와 상자 개수를 잘 설정해야 한다!)
그렇다면 이번 강좌는 여기에서 마치도록 하겠습니다. 다음 강좌에서는 STL 알고리즘을 이용한 여러가지 작업들에 대해 알아보도록 하겠습니다!

댓글을 불러오는 중입니다..