모두의 코드
씹어먹는 C++ - <10 - 1. C++ STL - 벡터(std::vector), 리스트(list), 데크(deque)>
이번 강좌에서는
C++ 표준 템플릿 라이브러리 개요
시퀀스 컨테이너(sequence container)
반복자 (iterator)
범위 기반 for 문 (Range-based for loop)
에 대해 배웁니다.

안녕하세요 여러분! 지난번 템플릿 메타프로그래밍 강좌는 어떠셨나요? TMP 를 활용해서 프로그래밍을 하는 것은 엄청 머리아픈 일이지만 적당히 잘 쓰면 꽤 괜찮은 도구입니다.
하지만 이번 강좌는 조금 다룹니다. 이번 강좌에서 배우게 될 C++ 의 표준 템플릿 라이브러리 (STL) 은 사용하는 것도 엄청 간단한데, 여러분이 하는 프로그래밍 능률을 100% 향상 시킬 수 있는 엄청난 도구 입니다. 사실 이 STL 의 도입으로 C++ 이 한발 더 도약한 것도 과언이 아니라 볼 수 있습니다.
C++ 표준 템플릿 라이브러리 (Standard Template Library - STL)
사실 C++ 표준 라이브러리를 보면 꽤나 많은 종류의 라이브러리들이 있습니다. 예를 들어서, 대표적으로 입출력 라이브러리 (iostream 등등), 시간 관련 라이브러리 (chrono), 정규표현식 라이브러리 (regex) 등등 들이 있지요. 하지만 보통 C++ 템플릿 라이브러리(STL)를 일컫는다면 다음과 같은 세 개의 라이브러리들을 의미합니다.
임의 타입의 객체를 보관할 수 있는 컨테이너 (container)
컨테이너에 보관된 원소에 접근할 수 있는 반복자 (iterator)
반복자들을 가지고 일련의 작업을 수행하는 알고리즘 (algorithm)
각 라이브러리의 역할을 쉽게 생각하면 다음과 같이 볼 수 있습니다. 여러분이 우편 배달부가 되어서 편지들을 여러개의 편지함에 넣는다고 생각해봅시다. 편지를 보관하는 각각의 편지함들은 '컨테이너' 라고 생각하시면 됩니다. 그리고, 편지를 보고 원하는 편지함을 찾는 일은 '반복자' 들이 수행하지요. 마지막으로, 만일 편지들을 편지함에 날짜 순서로 정렬하여 넣는 일은 '알고리즘' 이 수행할 것입니다.
한 가지 주목할 만한 점은
임의 타입의 객체를 보관할 수 있는 컨테이너 (container)
에서 나타나 있듯이 우리가 다루려는 객체가 어떤 특성을 갖는지 무관하게 라이브러리를 자유롭게 사용할 수 있다는 것입니다 (바로 템플릿 덕분이죠!). 우리가 만일 사용하려는 자료형이 int 나 string 과 같은 평범한 애들이 아니라, 우리가 만든 임의이 클래스의 객체들이여도 자유롭게 위 라이브러리의 기능들을 모두 활용할 수 있습니다. 만일 C 였다면 불가능했을 일입니다.
또한 반복자의 도입으로 알고리즘 라이브러리에 필요한 최소한의 코드만을 작성할 수 있게 되었습니다. 다시 말하면, 기존의 경우 M 개 종류의 컨테이가 있고 N 종류의 알고리즘이 있다면 이 모든 것을 지원하려면 MN 개의 알고리즘 코드가 있어야만 했습니다.
하지만 반복자를 이용해서 컨테이너를 추상화 시켜서 접근할 수 있기 때문에 N 개의 알고리즘 코드 만으로 M 종류의 컨테이너들을 모두 지원할 수 있게됩니다. (후에 알고리즘 라이브러리에 대해서 설명할 때 더 와닿을 것입니다)
C++ `STL` 컨테이너 - 벡터 (std::vector)
C++ STL 에서 컨테이너는 크게 두 가지 종류가 있습니다. 먼저 배열 처럼 객체들을 순차적으로 보관하는 시퀀스 컨테이너 (sequence container) 와 키를 바탕으로 대응되는 값을 찾아주는 연관 컨테이너 (associative container) 가 있습니다.
먼저 시퀀스 컨테이너의 경우 vector, list, deque 이렇게 3 개가 정의되어 있습니다. 먼저 벡터(vector) 의 경우, 쉽게 생각하면 가변길이 배열이라 보시면 됩니다 (템플릿 강의에서 Vector 를 제작하신 것을 기억 하시나요?) 벡터에는 원소들이 메모리 상에서 실제로 순차적으로 저장되어 있고, 따라서 임의의 위치에 있는 원소를 접근하는 것을 매우 빠르게 수행할 수 있습니다.
정확히 얼마나 빠르다고?
사실 '매우 빠르다' 라는 말은 주관적일 수 밖에 없습니다. 따라서 어떠한 작업의 수행 속도를 나타내기 위해선 수학적으로 나타내야 합니다.
컴퓨터 공학에선 어떠한 작업의 처리 속도를 복잡도(complexity) 라고 부르고, 그 복잡도를 Big 표기법이라는 것으로 나타냅니다. 이 표기법은, 개의 데이터가 주어져 있을 때 그 작업을 수행하기 위해 몇 번의 작업을 필요로 하는지 에 대한 식으로 표현하는 방식입니다. (즉 복잡도가 클 수록 작업이 수행되는데 걸리는 시간이 늘어나겠지요)
예를 들어 가장 기초적인 버블 정렬을 생각해봅시다. 버블 정렬의 코드는 간단히 보자면 아래와 같습니다.
for (int i = 0; i < N; i++) { for (int j = i + 1; j < N; j++) { if (arr[i] > arr[j]) { swap(arr, i, j) } } }
따라서 개의 원소가 있는 arr 이라는 배열을 정렬하기 위해서는 일단 적어도
번의 반복이 필요하지요 () 따라서 Big O 표현법으로 이 정렬이 얼마나 빠르게 수행될 수 있는지 나타내면
라고 볼 수 있습니다. 보통 Big O 표현법으로 나타낼 때, 최고차항만을 나타냅니다 (그리고 통상적으로 최고차항의 계수도 생략합니다). 왜냐하면 이 엄청 커지게 되면 최고 차항 말고는 그닥 의미가 없게 되버리기 때문이지요 (최고 차항에 비해 크기가 너무 작기 때문에). 따라서 최종적으로, 버블 정렬 알고리즘의 복잡도는
라고 볼 수 있습니다. 일반적으로 어떠한 알고리즘이 꼴이면 그닥 좋은 편은 아닙니다. 왜냐하면 이 10000 만 되더라도, 번의 작업을 처리해야 하기 때문이죠. 다행이도 정렬 알고리즘의 경우 퀵소트(Quicksort) 라는 알고리즘을 활용하면 아래와 같은 복잡도로 연산을 처리할 수 있습니다.
물론 퀵소트 알고리즘을 사용했을 때 항상 버블 정렬 방식 보다 빠르게 정렬할 수 있다는 의미는 아닙니다. 왜냐하면 저 항 앞에 어떠한 계수가 붙어있는지 알 수 없기 때문이지요. 만약에 버블 정렬이 이고 퀵소트가 이였다면 이 1000 일 때 버블 정렬이 더 빠르게 수행됩니다. (물론 이렇게 극단적이지 않습니다. 퀵소트가 거의 대부분 더 빠르게 됩니다!)
하지만, 이 정말 커진다면 언젠가는 퀵소트가 버블 정렬보다 더 빨리 수행되는 때가 발생합니다.
아래 그림을 보면 각각의 에 대해 복잡도가 어떻게 증가하는지 볼 수 있습니다.
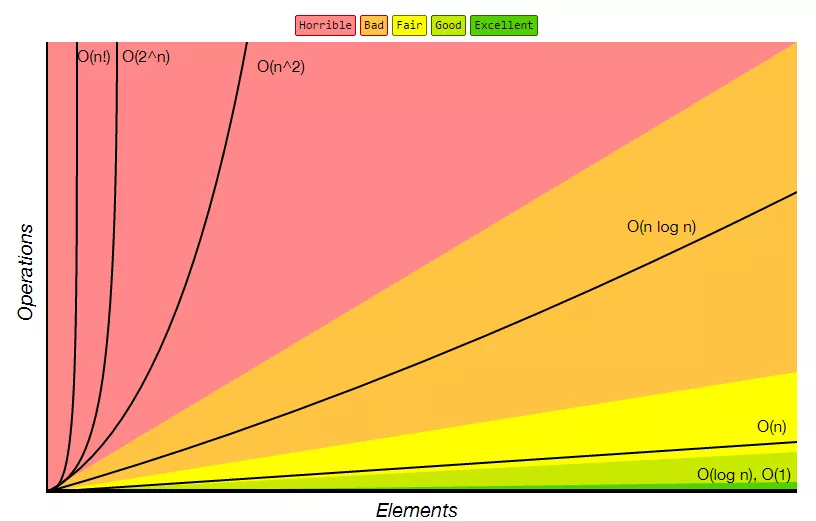
가장 이상적인 복잡도는 이지만 이는 거의 불가능하고 (이는 마치 전체 데이터를 채 보지 않은 채 작업을 끝낼 수 있다는 의미 입니다), 보통 이 알고리즘이 낼 수 있는 가장 빠른 속도를 의미합니다. 그 다음으로 좋은 것이 당연히 이고, 순 입니다.
그렇다면 다시 벡터 자료형으로 돌아오겠습니다. vector 의 경우, 임의의 위치에 있는 원소에 접근을 로 수행할 수 있습니다. 게다가 맨 뒤에 새로운 원소를 추가하거나 제거하는 것 역시 에 수행합니다. vector 의 임의의 원소에 접근하는 것은 배열처럼 [] 를 이용하거나, at 함수를 이용하면 됩니다. 또한 맨 뒤에 원소를 추가하거나 제거하기 위해서는 push_back 혹은 pop_back 함수를 사용하면 됩니다. 아래 예를 보겠습니다.
#include <iostream> #include <vector> int main() { std::vector<int> vec; vec.push_back(10); // 맨 뒤에 10 추가 vec.push_back(20); // 맨 뒤에 20 추가 vec.push_back(30); // 맨 뒤에 30 추가 vec.push_back(40); // 맨 뒤에 40 추가 for (std::vector<int>::size_type i = 0; i < vec.size(); i++) { std::cout << "vec 의 " << i + 1 << " 번째 원소 :: " << vec[i] << std::endl; } }
성공적으로 컴파일 하였으면
실행 결과
vec 의 1 번째 원소 :: 10 vec 의 2 번째 원소 :: 20 vec 의 3 번째 원소 :: 30 vec 의 4 번째 원소 :: 40
와 같이 우리가 넣은 순서대로 잘 나옴을 알 수 있습니다.
참고로 벡터의 크기를 리턴하는 함수인 size 의 경우, 그리턴하는 값의 타입은 size_type 멤버 타입으로 정의되어 있습니다.
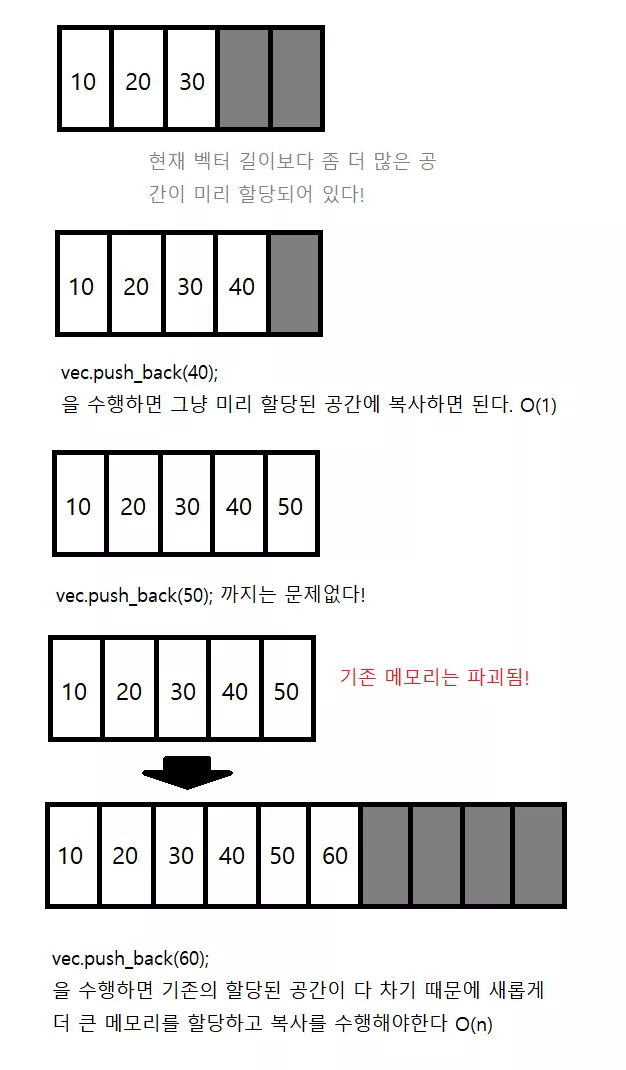
참고로 맨 뒤에 원소를 추가하는 작업은 엄밀히 말하자면 amortized 이라고 합니다. (amortized 의 뜻은 분할상환이란 뜻인데, 아마 아래 설명을 읽으시면 왜 그런 이름을 붙였는지 이해하실 수 있을 것입니다)
왜냐면 보통은 vector 의 경우 현재 가지고 있는 원소의 개수 보다 더 많은 공간을 할당해 놓고 있습니다. 예를 들어 현재 vector 에 있는 원소의 개수가 10 개라면 이미 20개를 저장할 수 있는 공간을 미리 할당해놓게됩니다. 따라서 만약에 뒤에 새로운 원소를 추가하게 된다면 새롭게 메모리를 할당할 필요가 없이, 그냥 이미 할당된 공간에 그 원소를 쓰기만 하면 됩니다. 따라서 대부분의 경우 으로 vector 맨 뒤에 새로운 원소를 추가하거나 지울 수 있습니다.
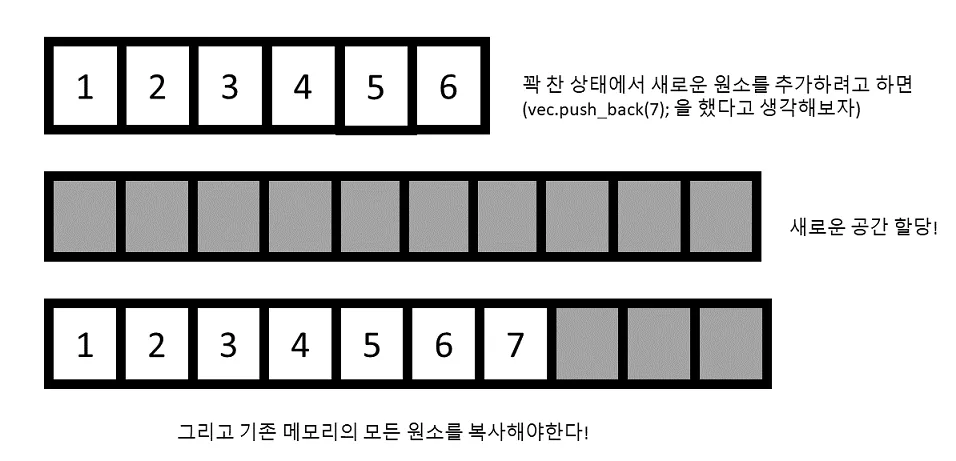
문제가 되는 상황은 할당된 공간을 다 채웠을 때 입니다. 이 때는 어쩔 수 없이, 새로운 큰 공간을 다시 할당하고, 기존의 원소들을 복사하는 수 밖에 없습니다. 따라서 이 경우 개의 원소를 모두 복사해야 하기 때문에 으로 수행됩니다. 하지만 이 으로 수행되는 경우가 매우 드물기 때문에, 전체적으로 평균을 내보았을 때 으로 수행됨을 알 수 있습니다. 이렇기에 amortized 이라고 부르게 됩니다. 아래 그림에서 자세히 설명하고 있습니다.
물론 vector 라고 만능은 아닙니다. 맨 뒤에 원소를 추가하거나 제거하는 것은 빠르지만,임의의 위치에 원소를 추가하거나 제거하는 것은 으로 느립니다. 왜냐하면 어떤 자리에 새로운 원소를 추가하거나 뺄 경우 그 뒤에 오는 원소들을 한 칸 씩 이동시켜 주어야만 하기 때문이지요. 따라서 이는 번의 복사가 필요로 합니다.
따라서 만일 맨 뒤가 아닌 위치에 데이터를 추가하거나 제거하는 작업이 많은 일일 경우 vector 를 사용하면 안되겠지요. 결과적으로 vector 의 복잡도를 정리해보자면 아래와 같습니다.
임의의 위치 원소 접근 (
[], at) :맨 뒤에 원소 추가 및 제거 (push_back/
pop_back) : amortized ; (평균적으로 이지만 최악의 경우 )임의의 위치 원소 추가 및 제거 (
insert, erase) :
위 처럼 어떠한 작업을 하냐에 따라서 속도차가 매우 크기 때문에, C++ 표준 라이브러리를 잘 사용하기 위해서는 내가 이 컨테이너를 어떠한 작업을 위해 사용하는지 정확히 인지하고, 적절한 컨테이너를 골라야 합니다. 후에 설명할 다른 자료 구조를 사용하면 vector 가 빠른 작업이 느릴 수 도 있고, vector 가 느린 작업을 빠르게 할 수 도 있습니다.
반복자 (iterator)
앞서 반복자는 컨테이너에 원소에 접근할 수 있는 포인터와 같은 객체라고 하였습니다. 물론 벡터의 경우 [ ] 를 이용해서 정수형 변수로 마치 배열 처럼 임의의 위치에 접근할 수 있지만, 반복자를 사용해서도 마찬가지 작업을 수행할 수 있습니다. 특히 후에 배울 알고리즘 라이브러리의 경우 대부분이 반복자를 인자로 받아서 알고리즘을 수행합니다.
반복자는 컨테이너에 iterator 멤버 타입으로 정의되어 있습니다. vector 의 경우 반복자를 얻기 위해서는 begin() 함수와 end() 함수를 사용할 수 있는데 이는 다음과 같은 위치를 리턴합니다.
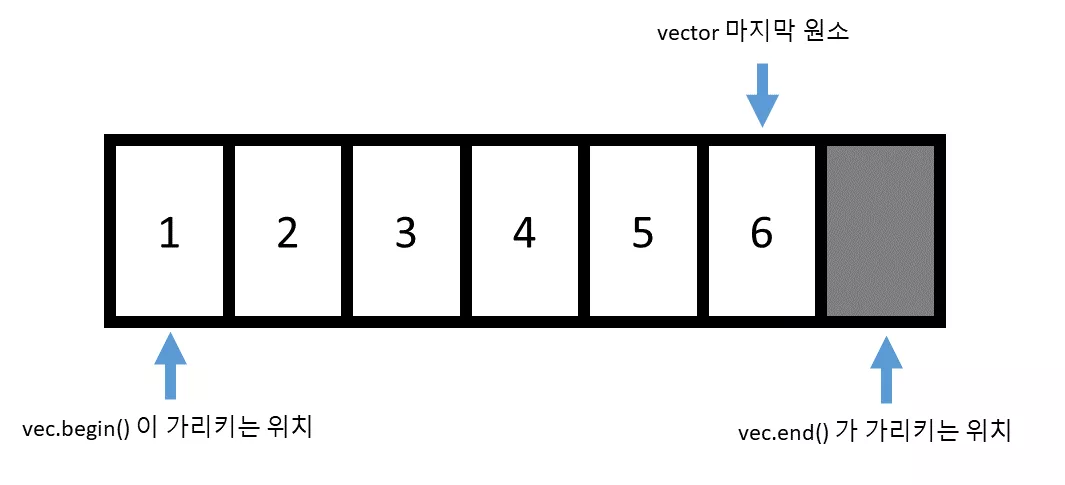
begin() 함수는 예상했던 대로, vector 의 첫번째 원소를 가리키는 반복자를 리턴합니다. 그런데, 흥미롭게도 end() 의 경우 vector 의 마지막 원소 한 칸 뒤를 가리키는 반복자를 리턴하게 됩니다. 왜 end 의 경우 vector 의 마지막 원소를 가리것이 아니라, 마지막 원소의 뒤를 가리키는 반복자를 리턴할까요?
이에 여러가지 이유가 있겠지만, 가장 중요한 점이 이를 통해 빈 벡터를 표현할 수 있다는 점입니다. 만일 begin() == end() 라면 원소가 없는 벡터를 의미하겠지요. 만약에 vec.end() 가 마지막 원소를 가리킨다면 비어있는 벡터를 표현할 수 없게 됩니다.
// 반복자 사용 예시 #include <iostream> #include <vector> int main() { std::vector<int> vec; vec.push_back(10); vec.push_back(20); vec.push_back(30); vec.push_back(40); // 전체 벡터를 출력하기 for (std::vector<int>::iterator itr = vec.begin(); itr != vec.end(); ++itr) { std::cout << *itr << std::endl; } // int arr[4] = {10, 20, 30, 40} // *(arr + 2) == arr[2] == 30; // *(itr + 2) == vec[2] == 30; std::vector<int>::iterator itr = vec.begin() + 2; std::cout << "3 번째 원소 :: " << *itr << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
10 20 30 40 3 번째 원소 :: 30
와 같이 잘 수행됨을 알 수 있습니다.
// 전체 벡터를 출력하기 for (std::vector<int>::iterator itr = vec.begin(); itr != vec.end(); ++itr) { std::cout << *itr << std::endl; }
vector 의 반복자의 타입은 위 처럼 std::vector<>::iterator 멤버 타입으로 정의되어 있고, vec.begin() 이나 vec.end() 함수가 이를 리턴합니다. end() 가 vector 의 마지막 원소 바로 뒤를 가리키기 때문에 for 문에서 vector 전체 원소를 보고 싶다면 vec.end() 가 아닐 때 까지 반복하면 됩니다.
앞서 반복자를 마치 포인터 처럼 사용한다고 하였는데, 실제로 현재 반복자가 가리키는 원소의 값을 보고 싶다면;
std::cout << *itr << std::endl;
포인터로 * 를 해서 가리키는 주소값의 값을 보았던 것처럼, * 연산자를 이용해서 itr 이 가리키는 원소를 볼 수 있습니다. 물론 itr 은 실제 포인터가 아니고 * 연산자를 오버로딩해서 마치 포인터 처럼 동작하게 만든 것입니다. * 연산자는 itr 이 가리키는 원소의 레퍼런스를 리턴합니다.
std::vector<int>::iterator itr = vec.begin() + 2; std::cout << "3 번째 원소 :: " << *itr << std::endl;
또한 반복자 역시 + 연산자를 통해서 그 만큼 떨어져 있는 원소를 가리키게 할 수 도 있습니다. (그냥 배열을 가리키는 포인터와 정확히 똑같이 동작한다고 생각하시면 됩니다!)
반복자를 이용하면 아래와 같이 insert 와 erase 함수도 사용할 수 있습니다.
#include <iostream> #include <vector> template <typename T> void print_vector(std::vector<T>& vec) { // 전체 벡터를 출력하기 for (typename std::vector<T>::iterator itr = vec.begin(); itr != vec.end(); ++itr) { std::cout << *itr << std::endl; } } int main() { std::vector<int> vec; vec.push_back(10); vec.push_back(20); vec.push_back(30); vec.push_back(40); std::cout << "처음 벡터 상태" << std::endl; print_vector(vec); std::cout << "----------------------------" << std::endl; // vec[2] 앞에 15 추가 vec.insert(vec.begin() + 2, 15); print_vector(vec); std::cout << "----------------------------" << std::endl; // vec[3] 제거 vec.erase(vec.begin() + 3); print_vector(vec); }
성공적으로 컴파일 하였다면
실행 결과
처음 벡터 상태 10 20 30 40 ---------------------------- 10 20 15 30 40 ---------------------------- 10 20 15 40
와 같이 잘 나옵니다.
참고로 템플릿 버전의 경우,
for (typename std::vector<T>::iterator itr = vec.begin(); itr != vec.end(); ++itr) {
와 같이 앞에 typename 을 추가해줘야만 합니다. 그 이유는, iterator 가 std::vector<T> 의 의존 타입이기 때문입니다. 의존 타입이 무엇인지 기억 안나시는 분은 이 강좌를 참조하시기 바랍니다
// vec[2] 앞에 15 추가 vec.insert(vec.begin() + 2, 15);
앞서 insert 함수를 소개하였는데, 위 처럼 인자로 반복자를 받고, 그 반복자 앞에 원소를 추가해줍니다. 위 경우 vec.begin() + 2 앞에 15 를 추가하므로 10, 20, 30, 40 에서 10, 20, 15, 30, 40 이 됩니다.
vec.erase(vec.begin() + 3); print_vector(vec);
또 아까전에 언급하였던 erase 도 인자로 반복자를 받고, 그 반복자가 가리키는 원소를 제거합니다. 위 경우 4 번째 원소인 30 이 지워지겠지요. 물론 insert 과 erase 함수 모두 O(n) 으로 느린편입니다.
참고로 vector 에서 반복자로 erase 나 insert 함수를 사용할 때 주의해야할 점이 있습니다.
#include <iostream> #include <vector> template <typename T> void print_vector(std::vector<T>& vec) { // 전체 벡터를 출력하기 std::cout << "[ "; for (typename std::vector<T>::iterator itr = vec.begin(); itr != vec.end(); ++itr) { std::cout << *itr << " "; } std::cout << "]"; } int main() { std::vector<int> vec; vec.push_back(10); vec.push_back(20); vec.push_back(30); vec.push_back(40); vec.push_back(20); std::cout << "처음 벡터 상태" << std::endl; print_vector(vec); std::vector<int>::iterator itr = vec.begin(); std::vector<int>::iterator end_itr = vec.end(); for (; itr != end_itr; ++itr) { if (*itr == 20) { vec.erase(itr); } } std::cout << "값이 20 인 원소를 지운다!" << std::endl; print_vector(vec); }
컴파일 후 실행하였다면 아래와 같은 오류가 발생합니다.
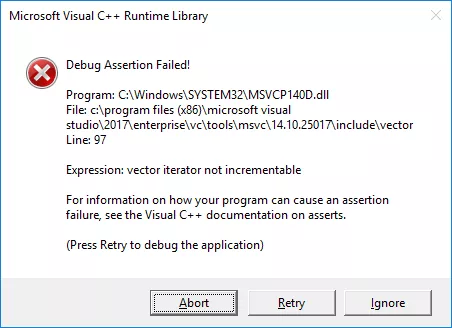
왜 이런 오류가 발생하는 것일까요?
문제는 바로 위 코드에서 발생합니다. 컨테이너에 원소를 추가하거나 제거하게 되면 기존에 사용하였던 모든 반복자들을 사용할 수 없게됩니다. 다시 말해 위 경우 vec.erase(itr) 을 수행하게 되면 더이상 itr 은 유효한 반복자가 아니게 되는 것이지요. 또한 end_itr 역시 무효화 됩니다.
따라서 itr != end_itr 이 영원히 성립되며 무한 루프에 빠지게되어 위와 같은 오류가 발생합니다.
그렇다면
와 같이 코드를 고치면 오류가 없어질까요? 실행해보시면 알겠지만 여전히 위와 같은 오류가 발생합니다. 왜냐하면 itr 이 유효한 반복자가 아니기 때문에 vec.end() 로 올바른 end 반복자 값을 매번 가지고 와도 for 문이 끝나지 않게 되는 것입니다. 결과적으로 코드를 제대로 고치려면 다음과 같이 해야 합니다.
std::vector<int>::iterator itr = vec.begin(); for (; itr != vec.end(); ++itr) { if (*itr == 20) { vec.erase(itr); itr = vec.begin(); } }
성공적으로 컴파일 하였다면
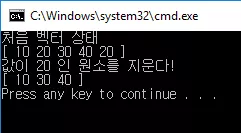
와 같이 제대로 값이 20 인 원소만 지워졌음을 알 수 있습니다.
사실 생각해보면 위 바뀐 코드는 꽤나 비효율적임을 알 수 있습니다. 왜냐하면 20 인 원소를 지우고, 다시 처음으로 돌아가서 원소들을 찾고 있기 때문이지요. 그냥 20 인 원소 바로 다음 위치 부터 찾아나가면 될 텐데 말입니다.
for (std::vector<int>::size_type i = 0; i != vec.size(); i++) { if (vec[i] == 20) { vec.erase(vec.begin() + i); i--; } }
그렇다면 아예 위 처럼 굳이 반복자를 쓰지 않고 erase 함수에만 반복자를 바로 만들어서 전달하면 됩니다.
vec.erase(vec.begin() + i);
를 하게 되면 vec[i] 를 가리키는 반복자를 erase 에 전달할 수 있습니다. 하지만 사실 위 방법은 그리 권장하는 방법은 아닙니다. 기껏 원소에 접근하는 방식은 반복자를 사용하는 것으로 통일하였는데, 위 방법은 이를 모두 깨버리고 그냥 기존의 배열 처럼 정수형 변수 i 로 원소에 접근하는 것이기 때문입니다.
하지만 후에 C++ 알고리즘 라이브러리에 대해 배우면서 이 문제를 깔끔하게 해결 하는 방법에 대해 다루도록 할 것입니다. 일단 임시로는 위 방법 처럼 처리하도록 하세요 :)
vector 에서 지원하는 반복자로 const_iterator 가 있습니다. 이는 마치 const 포인터를 생각하시면 됩니다. 즉, const_iterator 의 경우 가리키고 있는 원소의 값을 바꿀 수 없습니다. 예를 들어서
#include <iostream> #include <vector> template <typename T> void print_vector(std::vector<T>& vec) { // 전체 벡터를 출력하기 for (typename std::vector<T>::iterator itr = vec.begin(); itr != vec.end(); ++itr) { std::cout << *itr << std::endl; } } int main() { std::vector<int> vec; vec.push_back(10); vec.push_back(20); vec.push_back(30); vec.push_back(40); std::cout << "초기 vec 상태" << std::endl; print_vector(vec); // itr 은 vec[2] 를 가리킨다. std::vector<int>::iterator itr = vec.begin() + 2; // vec[2] 의 값을 50으로 바꾼다. *itr = 50; std::cout << "---------------" << std::endl; print_vector(vec); std::vector<int>::const_iterator citr = vec.cbegin() + 2; // 상수 반복자가 가리키는 값은 바꿀수 없다. 불가능! *citr = 30; }
컴파일 하였다면
컴파일 오류
'citr': you cannot assign to a variable that is const
와 같이, const 반복자가 가리키고 있는 값은 바꿀 수 없다고 오류가 발생합니다. 주의할 점은, const 반복자의 경우
std::vector<int>::const_iterator citr = vec.cbegin() + 2;
와 같이 cbegin() 과 cend() 함수를 이용하여 얻을 수 있습니다. 많은 경우 반복자의 값을 바꾸지 않고 참조만 하는 경우가 많으므로, const iterator 를 적절히 이용하는 것이 좋습니다.
vector 에서 지원하는 반복자 중 마지막 종류로 역반복자 (reverse iterator) 가 있습니다. 이는 반복자와 똑같지만 벡터 뒤에서 부터 앞으로 거꾸로 간다는 특징이 있습니다. 아래 예제를 살펴볼까요.
#include <iostream> #include <vector> template <typename T> void print_vector(std::vector<T>& vec) { // 전체 벡터를 출력하기 for (typename std::vector<T>::iterator itr = vec.begin(); itr != vec.end(); ++itr) { std::cout << *itr << std::endl; } } int main() { std::vector<int> vec; vec.push_back(10); vec.push_back(20); vec.push_back(30); vec.push_back(40); std::cout << "초기 vec 상태" << std::endl; print_vector(vec); std::cout << "역으로 vec 출력하기!" << std::endl; // itr 은 vec[2] 를 가리킨다. std::vector<int>::reverse_iterator r_iter = vec.rbegin(); for (; r_iter != vec.rend(); r_iter++) { std::cout << *r_iter << std::endl; } }
성공적으로 컴파일 하였다면
실행 결과
초기 vec 상태 10 20 30 40 역으로 vec 출력하기! 40 30 20 10
와 같이 역으로 벡터의 원소들을 출력할 수 있습니다.
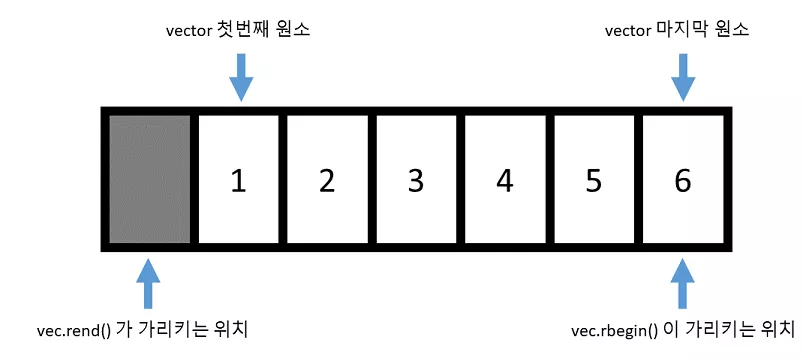
이전에 반복자의 end() 가 맨 마지막 원소의 바로 뒤를 가리켰던 것처럼, 역반복자의 rend() 역시 맨 앞 원소의 바로 앞을 가리키게 됩니다. 또한 반복자의 경우 값이 증가하면 뒤쪽 원소로 가는 것처럼, 역반복자의 경우 값이 증가하면 앞쪽 원소로 가게 됩니다.
또 반복자가 상수 반복자가 있는 것 처럼 역반복자 역시 상수 역반복자가 있습니다. 그 타입은 const_reverse_iterator 타입이고, crbegin(), crend() 로 얻을 수 있습니다.
역반복자를 사용하는 것은 매우 중요합니다. 아래와 같은 코드를 살펴볼까요.
#include <iostream> #include <vector> int main() { std::vector<int> vec; vec.push_back(1); vec.push_back(2); vec.push_back(3); // 끝에서 부터 출력하기 for (std::vector<int>::size_type i = vec.size() - 1; i >= 0; i--) { std::cout << vec[i] << std::endl; } return 0; }
성공적으로 컴파일 하였다면
실행 결과
3 2 1 // ... (생략) ... 0 0 0 1 0 593 0 0 [1] 22180 segmentation fault (core dumped) ./test
와 같이 오류가 발생하게 됩니다. 맨 뒤의 원소 부터 제대로 출력하는 코드 같은데 왜 이런 문제가 발생하였을까요? 그 이유는 vector 의 index 를 담당하는 타입이 부호 없는 정수 이기 때문입니다. 따라서 i 가 0 일 때 i -- 를 하게 된다면 -1 이 되는 것이 아니라, 해당 타입에서 가장 큰 정수가 되버리게 됩니다.
따라서 for 문이 영원히 종료할 수 없게 되죠.
이 문제를 해결하기 위해서는 부호 있는 정수로 선언해야 하는데, 이 경우 vector 의 index 타입과 일치하지 않아서 타입 캐스팅을 해야 한다는 문제가 발생하게 됩니다.
따라서 가장 현명한 선택으로는 역으로 원소를 참조하고 싶다면, 역반복자를 사용하는 것입니다.
범위 기반 for 문 (range based for loop)
위와 같이 컨테이너의 원소를 for 문 으로 접근하는 패턴은 매우 많이 등장하는데, C++ 11 에서 부터는 이와 같은 패턴을 매우 간단하게 나타낼 수 있는 방식을 제공하고 있습니다. 바로 범위 기반(range-based) for 문 이라 불리는 것입니다.
#include <iostream> #include <vector> int main() { std::vector<int> vec; vec.push_back(1); vec.push_back(2); vec.push_back(3); // range-based for 문 for (int elem : vec) { std::cout << "원소 : " << elem << std::endl; } return 0; }
성공적으로 컴파일 하였다면
실행 결과
원소 : 1 원소 : 2 원소 : 3
와 같이 나옵니다. 범위 기반 for 문의 경우 아래와 같은 형태로 써주시면 됩니다.
위 경우
for (int elem : vec) { std::cout << "원소 : " << elem << std::endl; }
의 형태로 썼을 경우, elem 에 vec 의 원소들이 매 루프 마다 복사되서 들어가게 됩니다. 마치
elem = vec[i];
를 한 것과 말이지요. 만약에 복사 하기 보다는 레퍼런스를 받고 싶다면 어떨까요? 매우 간단합니다. 단순히 레퍼런스 타입으로 바꿔버리면 되죠. 예를 들어서 기존의 print_vec 함수를 범위 기반 for 문을 사용해서 어떻게 바꿀 수 있는지 살펴봅시다.
#include <iostream> #include <vector> template <typename T> void print_vector(std::vector<T>& vec) { // 전체 벡터를 출력하기 for (typename std::vector<T>::iterator itr = vec.begin(); itr != vec.end(); ++itr) { std::cout << *itr << std::endl; } } template <typename T> void print_vector_range_based(std::vector<T>& vec) { // 전체 벡터를 출력하기 for (const auto& elem : vec) { std::cout << elem << std::endl; } } int main() { std::vector<int> vec; vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); std::cout << "print_vector" << std::endl; print_vector(vec); std::cout << "print_vector_range_based" << std::endl; print_vector_range_based(vec); return 0; }
실행 결과
print_vector 1 2 3 4 print_vector_range_based 1 2 3 4
와 같이 동일하게 나타남을 알 수 있습니다.
for (const auto& elem : vec) { std::cout << elem << std::endl; }
위와 같이 const auto& 로 elem 을 선언하였으므로, elem 은 vec 의 원소들을 상수 레퍼런스로 접근하게 됩니다.
이와 같이 범위 기반 for 문을 활용한다면 코드를 직관적으로 나타낼 수 있어서 매우 편리합니다.
참고로 앞서 설명한 함수들 말고도 vector 에는 수 많은 함수들이 있고, 또 오버로드 되는 여러가지 버전들이 있습니다.
예를 들어 insert 함수만 해도 5 개의 오버로드 되는 버전들이 있습니다 (물론 하는 역할은 똑같지만 편의를 위해 여러가지 방식으로 사용할 수 있게 만들어 놓은것입니다). 이 모든 것들을 강좌에서 소개하는 것은 시간 낭비이고, C++ 레퍼런스를 보면 잘 정리되어 있으니 이를 참조하시기 바랍니다.
리스트 (list)
리스트(list) 의 경우 양방향 연결 구조를 가진 자료형이라 볼 수 있습니다.
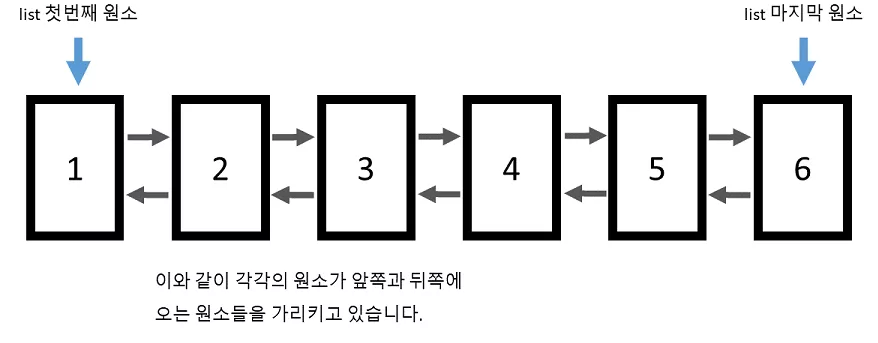
따라서 vector 와는 달리 임의의 위치에 있는 원소에 접근을 바로 할 수 없습니다. list 컨테이너 자체에서는 시작 원소와 마지막 원소의 위치만을 기억하기 때문에, 임의의 위치에 있는 원소에 접근하기 위해서는 하나씩 링크를 따라가야 합니다.
그래서 리스트에는 아예 [] 나 at 함수가 아예 정의되어 있지 않습니다.
물론 리스트의 장점이 없는 것은 아닙니다. vector 의 경우 맨 뒤를 제외하고는 임의의 위치에 원소를 추가하거나 제거하는 작업이 이였지만 리스트의 경우 으로 매우 빠르게 수행될 수 있습니다. 왜냐하면 원하는 위치 앞과 뒤에 있는 링크값만 바꿔주면 되기 때문입니다.
#include <iostream> #include <list> int main() { std::list<int> lst; lst.push_back(10); lst.push_back(20); lst.push_back(30); lst.push_back(40); for (std::list<int>::iterator itr = lst.begin(); itr != lst.end(); ++itr) { std::cout << *itr << std::endl; } }
성공적으로 컴파일 하였다면
실행 결과
10 20 30 40
와 같이 잘 나옵니다.
한 가지 재미있는점은 리스트의 반복자의 경우 다음과 같은 연산밖에 수행할 수 없습니다.
itr++ // itr ++ itr-- // --itr 도 됩니다.
다시말해
itr + 5 // 불가능!
와 같이 임의의 위치에 있는 원소를 가리킬 수 없다는 것입니다. 반복자는 오직 한 칸 씩 밖에 움직일 수 없습니다.
이와 같은 이유는 list 의 구조를 생각해보면 알 수 있습니다. 앞서 말했듯이 리스트는 왼쪽 혹은 오른쪽을 가리키고 있는 원소들의 모임으로 이루어져 있기 때문에, 한 번에 한 칸 씩 밖에 이동할 수 없습니다. 즉, 메모리 상에서 원소들이 연속적으로 존재하지 않을 수 있다는 뜻입니다. 반면에 벡터의 경우 메모리 상에서 연속적으로 존재하기 때문에 쉽게 임의의 위치에 있는 원소를 참조할 수 있습니다.
이렇게 리스트 에서 정의되는 반복자의 타입을 보면 BidirectionalIterator 타입임을 알 수 있습니다. 이름에서도 알 수 있듯이 양방향으로 이동할 수 있되, 한 칸 씩 밖에 이동할 수 없습니다. 반면에 벡터에서 정의되는 반복자의 타입은 RandomAccessIterator 타입 입니다.
즉, 임의의 위치에 접근할 수 있는 반복자 입니다 (참고로 RandomAccessIterator 는 BidirectionalIterator 를 상속받고 있습니다)
#include <iostream> #include <list> template <typename T> void print_list(std::list<T>& lst) { std::cout << "[ "; // 전체 리스트를 출력하기 (이 역시 범위 기반 for 문을 쓸 수 있습니다) for (const auto& elem : lst) { std::cout << elem << " "; } std::cout << "]" << std::endl; } int main() { std::list<int> lst; lst.push_back(10); lst.push_back(20); lst.push_back(30); lst.push_back(40); std::cout << "처음 리스트의 상태 " << std::endl; print_list(lst); for (std::list<int>::iterator itr = lst.begin(); itr != lst.end(); ++itr) { // 만일 현재 원소가 20 이라면 // 그 앞에 50 을 집어넣는다. if (*itr == 20) { lst.insert(itr, 50); } } std::cout << "값이 20 인 원소 앞에 50 을 추가 " << std::endl; print_list(lst); for (std::list<int>::iterator itr = lst.begin(); itr != lst.end(); ++itr) { // 값이 30 인 원소를 삭제한다. if (*itr == 30) { lst.erase(itr); break; } } std::cout << "값이 30 인 원소를 제거한다" << std::endl; print_list(lst); }
성공적으로 컴파일 하면
실행 결과
처음 리스트의 상태 [ 10 20 30 40 ] 값이 20 인 원소 앞에 50 을 추가 [ 10 50 20 30 40 ] 값이 30 인 원소를 제거한다 [ 10 50 20 40 ]
와 같이 잘 나옵니다.
for (std::list<int>::iterator itr = lst.begin(); itr != lst.end(); ++itr) { // 만일 현재 원소가 20 이라면 // 그 앞에 50 을 집어넣는다. if (*itr == 20) { lst.insert(itr, 50); } }
앞서 설명하였지만 리스트의 반복자는 BidirectionalIterator 이기 때문에 ++ 과 -- 연산만 사용 가능합니다. 따라서 위 처럼 for 문으로 하나 하나 원소를 확인해보는것은 가능하지요. vector 와는 다르게 insert 작업은 O(1) 으로 매우 빠르게 실행됩니다.
for (std::list<int>::iterator itr = lst.begin(); itr != lst.end(); ++itr) { // 값이 30 인 원소를 삭제한다. if (*itr == 30) { lst.erase(itr); break; } }
마찬가지로 erase 함수를 이용하여 원하는 위치에 있는 원소를 지울 수 도 있습니다. 리스트의 경우는 벡터와는 다르게, 원소를 지워도 반복자가 무효화 되지 않습니다. 왜냐하면, 각 원소들의 주소값들은 바뀌지 않기 때문이죠!
덱 (deque - double ended queue)
마지막으로 살펴볼 컨테이너는 덱(deque) 이라고 불리는 자료형 입니다. 덱은 벡터와 비슷하게 으로 임의의 위치의 원소에 접근할 수 있으며 맨 뒤에 원소를 추가/제거 하는 작업도 으로 수행할 수 있습니다. 뿐만아니라 벡터와는 다르게 맨 앞에 원소를 추가/제거 하는 작업 까지도 으로 수행 가능합니다.
임의의 위치에 있는 원소를 제거/추가 하는 작업은 벡터와 마찬가지로 으로 수행 가능합니다. 뿐만 아니라 그 속도도 벡터 보다 더 빠릅니다 (이 부분은 아래 덱이 어떻게 구현되어 있는지 설명하면서 살펴보겠습니다.)
그렇다면 덱이 벡터에 비해 모든 면에서 비교 우위에 있는 걸까요? 안타깝게도 벡터와는 다르게 덱의 경우 원소들이 실제로 메모리 상에서 연속적으로 존재하지는 않습니다. 이 때문에 원소들이 어디에 저장되어 있는지에 대한 정보를 보관하기 위해 추가적인 메모리가 더 필요로 합니다. (실제 예로, 64 비트 libc++ 라이브러리의 경우 1 개의 원소를 보관하는 덱은 그 원소 크기에 비해 8 배나 더 많은 메모리를 필요로 합니다).
즉 덱은 실행 속도를 위해 메모리를 (많이) 희생하는 컨테이너라 보면 됩니다.
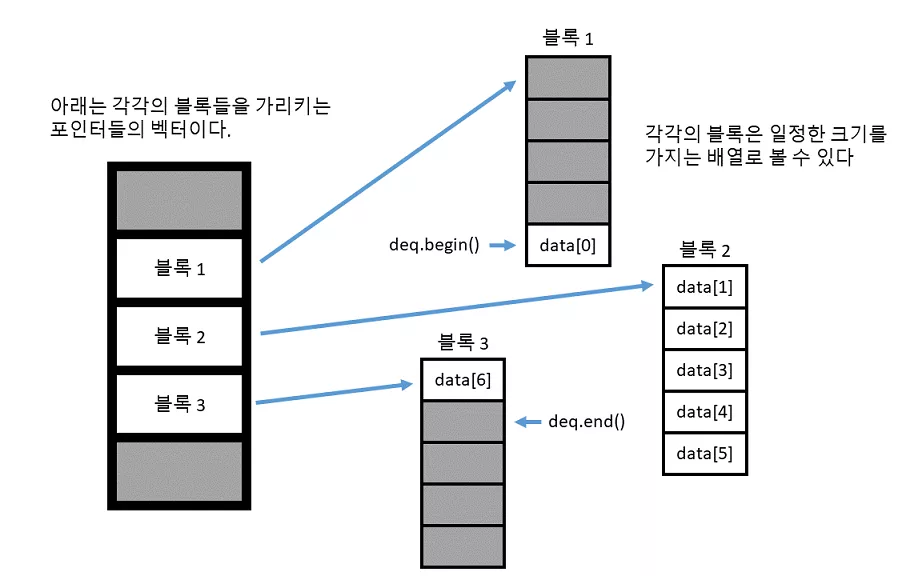
위 그림은 덱이 어떠한 구조를 가지는지 보여줍니다. 일단, 벡터와는 다르게 원소들이 메모리에 연속되어 존재하는 것이 아니라 일정 크기로 잘려서 각각의 블록 속에 존재합니다. 따라서 이 블록들이 메모리 상에 어느 곳에 위치하여 있는지 저장하기 위해서 각각의 블록들의 주소를 저장하는 벡터가 필요로 합니다.
참고로 이 벡터는 기존의 벡터와는 조금 다르게, 새로 할당 시에 앞쪽 및 뒤쪽 모두에 공간을 남겨놓게 됩니다. (벡터의 경우 뒤쪽에만 공간이 남았지요) 따라서 이를 통해 맨 앞과 맨 뒤에 O(1) 의 속도로 insert 및 erase 를 수행할 수 있는 것입니다. 그렇다면 왜 덱이 벡터 보다 원소를 삽입하는 작업이 더 빠른 것일까요?
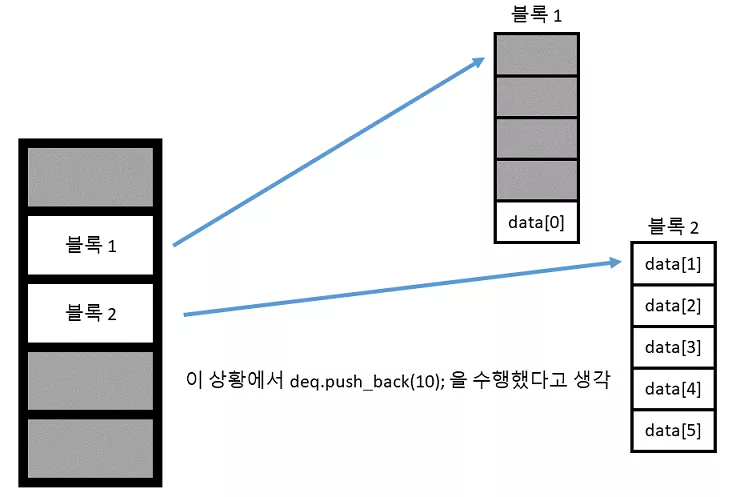
위와 같은 상황에서 deq.push_back(10) 을 수행하였다고 생각해봅시다.
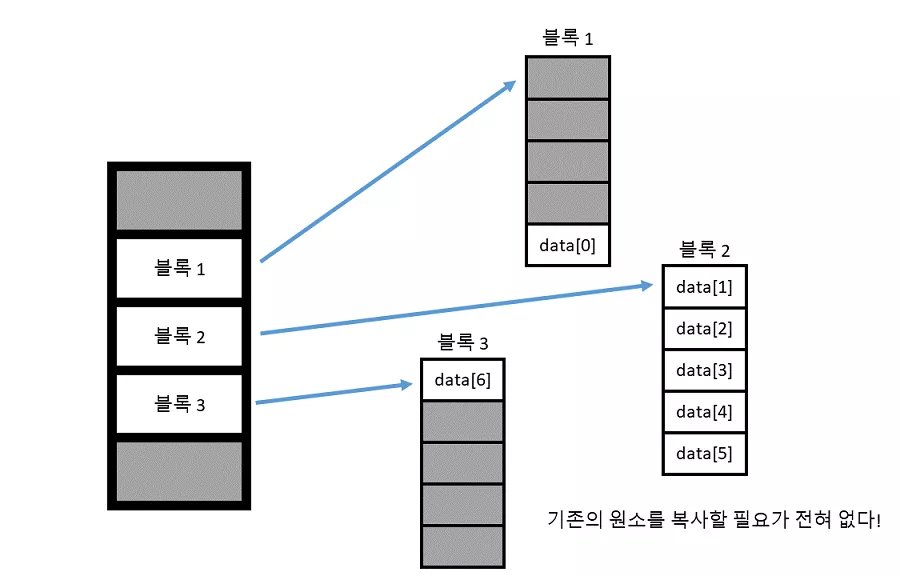
그렇다면 단순히 새로운 블록을 만들어서 뒤에 추가되는 원소를 넣어주면 됩니다. 즉 기존의 원소들을 복사할 필요가 전혀 없다는 의미 입니다. 반면에 벡터의 경우
위 그림에서도 잘 알 수 있듯이, 만약에 기존에 할당한 메모리가 꽉 차면 모든 원소들을 새로운 공간에 복사해야 합니다. 따라서 평균적으로 덱이 벡터보다 더 빠르게 작동합니다. (물론 덱의 경우 블록 주소를 보관하는 벡터가 꽉 차게 되면 새로운 공간에 모두 복사해야 합니다.
하지만 블록 주소의 개수는 전체 원소 개수 보다 적고 ( 위 경우 N / 5 가 되겠네요. 왜냐하면 각 블록에 원소가 5개 씩 있으므로), 대체로 벡터에 저장되는객체들의 크기가 주소값의 크기보다 크기 때문에 복사 속도가 훨씬 빠릅니다.)
#include <deque> #include <iostream> template <typename T> void print_deque(std::deque<T>& dq) { // 전체 덱을 출력하기 std::cout << "[ "; for (const auto& elem : dq) { std::cout << elem << " "; } std::cout << " ] " << std::endl; } int main() { std::deque<int> dq; dq.push_back(10); dq.push_back(20); dq.push_front(30); dq.push_front(40); std::cout << "초기 dq 상태" << std::endl; print_deque(dq); std::cout << "맨 앞의 원소 제거" << std::endl; dq.pop_front(); print_deque(dq); }
성공적으로 컴파일 하였다면
실행 결과
초기 dq 상태 [ 40 30 10 20 ] 맨 앞의 원소 제거 [ 30 10 20 ]
와 같이 잘 수행됩니다.
dq.push_back(10); dq.push_back(20); dq.push_front(30); dq.push_front(40);
위와 같이 push_back 과 push_front 를 이용해서 맨 앞과 뒤에 원소들을 추가하였고,
dq.pop_front();
pop_front 함수를 이용해서 맨 앞의 원소를 제거할 수 있습니다.
앞서 말했듯이 덱 역시 벡터 처럼 임의의 위치에 원소에 접근할 수 있으므로 [] 와 at 함수를 제공하고 있고, 반복자 역시 RandomAccessIterator 타입 이고 벡터랑 정확히 동일한 방식으로 작동합니다.
그래서 어떤 컨테이너를 사용해야돼?
어떠한 컨테이너를 사용할지는 전적으로 이 컨테이너를 가지고 어떠한 작업들을 많이 하냐에 달려있습니다.
일반적인 상황에서는 그냥 벡터를 사용한다 (거의 만능이다!)
만약에 맨 끝이 아닌 중간에 원소들을 추가하거나 제거하는 일을 많이 하고, 원소들을 순차적으로만 접근 한다면 리스트를 사용한다.
만약에 맨 처음과 끝 모두에 원소들을 추가하는 작업을 많이하면 덱을 사용한다.
참고적으로 으로 작동한다는 것은 언제나 이론적인 결과일 뿐이며 실제로 프로그램을 짜게 된다면, 이나 보다도 느릴 수 있습니다. ( 의 크기에 따라서) 따라서 속도가 중요한 환경이라면 적절한 벤치마크를 통해서 성능을 가늠해 보는것도 좋습니다.
자 이번 강좌는 이것으로 마치도록 하겠습니다. 다음 강좌에서는 다른 종류의 컨테이너인 연관 컨테이너에 대해서 배웁니다.
생각 해보기
문제 1
deque 를 구현해보세요. (난이도 : 중)
문제 2
여기에서 시퀀스 컨테이너들의 모든 함수들을 찾아볼 수 있습니다.한 번 읽어보세요!

댓글을 불러오는 중입니다..