모두의 코드
씹어먹는 C++ - <10 - 4. C++ 문자열의 모든 것 (string 과 string_view)>
이번 강좌에서는
유니코드와 여러가지 인코딩 방식
등등에 대해 다룹니다.

안녕하세요 여러분! 지난 강좌들에서 STL 의 컨테이너들과 알고리즘 라이브러리에 대해 다루었습니다. 이번 강좌에서는 C++ 의 표준 문자열 라이브러리인 <string> 에 대해 조금 더 자세히 알아보도록 할 것입니다.
basic_string
이전에 6-1 강에서 string 클래스에 대해 간단히 소개드린적이 있습니다. 그 때 간단히 std::string 의 사용법을 짚고 갔었는데요, 이번 강좌에서는 좀 더 자세히 파헤쳐보겠습니다.
std::string 은 사실 basic_string 이라는 클래스 템플릿의 인스턴스화 버전입니다. basic_string 의 정의를 살펴보면 아래와 같습니다.
template <class CharT, class Traits = std::char_traits<CharT>, class Allocator = std::allocator<CharT> > class basic_string;
basic_string 은 CharT 타입의 객체들을 메모리에 연속적으로 저장하고, 여러가지 문자열 연산들을 지원해주는 클래스 입니다. 만약에 CharT 자리에 char 이 오게 된다면, 우리가 생각하는 std::string 이 되는 것이죠. 사실 우리가 아는 string 말고도 총 5 가지 종류의 인스턴스화 된 문자열들이 있는데;
타입 | 정의 | 비고 |
|---|---|---|
| ||
|
| |
|
|
|
|
| |
|
|
와 같이 있습니다. UTF-8 이나 UTF-16 이 뭔지에 관해서는 아래에 좀더 설명할 것이니 여기서는 대충 저런들이 있구나 하고 넘어가면 됩니다.
그렇다면 나머지 템플릿 인자들을 살펴봅시다. Traits 는 주어진 CharT 문자들에 대해 기본적인 문자열 연산들을 정의해놓은 클래스를 의미합니다. 여기서 기본적인 문자열 연산들이란, 주어진 문자열의 대소 비교를 어떻게 할 것인지, 주어진 문자열의 길이를 어떻게 잴 것인지 등등을 말합니다.
다시 말해 basic_string 에 정의된 문자열 연산들은 사실 전부다 Traits 의 기본적인 문자열 연산들을 가지고 정의되어 있습니다. 덕분에 문자열들을 어떻게 보관하는지 에 대한 로직과 문자열들을 어떻게 연산하는지 에 대한 로직을 분리시킬 수 있었지요. 전자는 basic_string 에서 해결하고, 후자는 Traits 에서 담당하게 됩니다.
이렇게 로직을 분리한 이유는 basic_string 의 사용자에게 좀더 자유를 부여하기 위해서 입니다. 예를 들어서 string 처럼 char 이 기본 타입인 문자열에서, 문자열 비교시 대소 문자 구분을 하지 않는 버전을 만들고싶다고 해봅시다.
그렇다면 그냥 처음 부터 Traits 에서 문자열들을 비교하는 부분만 살짝 바꿔주면 됩니다. 만일 Traits 가 없었다면 basic_string 에서 문자열을 비교하는 부분을 일일히 찾아서 고쳐야겠지요. 여기 에서 예시 코드를 볼 수 있습니다.
Traits 에는 <string> 에 정의된 std::char_traits 클래스의 인스턴스화 버전을 전달합니다. 예를 들어서 string 의 경우 char_traits<char> 을 사용하게 됩니다.
숫자들의 순위가 알파벳 보다 낮은 문자열
Traits 가 어떻게 활용되는지 좀더 자세히 살펴보기 위해, 직접 Traits 클래스를 오버로딩 해서 문자열 비교시의 숫자들의 순위가 제일로 낮은 문자열을 만들어보겠습니다. 이게 무슨 말이냐면 원래 아스키 테이블에서 숫자들의 값이 알파벳 보다 작아서 더 앞에 오게 됩니다. 즉, 1a 가 a1 보다 앞에 온다는 것이지요.
하지만 이를 바꿔서 숫자들이 다른 문자들 보다 우선순위가 낮은 문자열을 한 번 만들어보겠습니다.
#include <cctype> #include <iostream> #include <string> // char_traits 의 모든 함수들은 static 함수 입니다. struct my_char_traits : public std::char_traits<char> { static int get_real_rank(char c) { // 숫자면 순위를 엄청 떨어트린다. if (isdigit(c)) { return c + 256; } return c; } static bool lt(char c1, char c2) { return get_real_rank(c1) < get_real_rank(c2); } static int compare(const char* s1, const char* s2, size_t n) { while (n-- != 0) { if (get_real_rank(*s1) < get_real_rank(*s2)) { return -1; } if (get_real_rank(*s1) > get_real_rank(*s2)) { return 1; } ++s1; ++s2; } return 0; } }; int main() { std::basic_string<char, my_char_traits> my_s1 = "1a"; std::basic_string<char, my_char_traits> my_s2 = "a1"; std::cout << "숫자의 우선순위가 더 낮은 문자열 : " << std::boolalpha << (my_s1 < my_s2) << std::endl; std::string s1 = "1a"; std::string s2 = "a1"; std::cout << "일반 문자열 : " << std::boolalpha << (s1 < s2) << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
숫자의 우선순위가 더 낮은 문자열 : false 일반 문자열 : true
와 같이 잘 나옵니다.
struct my_char_traits : public std::char_traits<char> {
basic_string 의 Traits 에는 char_traits 에서 제공하는 모든 멤버 함수들이 구현된 클래스가 전달되어야 합니다. (꼭 char_traits 를 상속 받을 필요는 없습니다) 이를 가장 간편히 만들기 위해서는 그냥 char_traits 를 상속 받은 후, 필요한 부분만 새로 구현하면 됩니다.
char_traits 에 정의되는 함수들은 모두 static 함수들 입니다. 그 이유는 char_traits 의 존재 이유를 생각해보면 당연한데, Traits 는 문자와 문자열들 간에 간단한 연산을 제공해주는 클래스이므로 굳이 데이터를 저장할 필요가 없기 때문입니다. (이를 보통 Stateless 하다고 합니다.)
일반적인 char 들을 다루는 char_traits<char> 에서 우리가 바꿔줘야 할 부분은 대소 비교하는 부분 뿐입니다. 따라서 아래와 같이 문자들 간의 크기를 비교하는 lt 함수와 길이 n 의 문자열의 크기를 비교하는 compare 함수를 새로 정의해줘야 했습니다.
static bool lt(char c1, char c2) { return get_real_rank(c1) < get_real_rank(c2); } static int compare(const char* s1, const char* s2, size_t n) { while (n-- != 0) { if (get_real_rank(*s1) < get_real_rank(*s2)) { return -1; } if (get_real_rank(*s1) > get_real_rank(*s2)) { return 1; } ++s1; ++s2; } return 0; }
코드를 읽어보면 그다지 어렵지 않습니다. get_real_rank 함수는 문자를 받아서 숫자면 256 을 더해서 순위를 매우 떨어뜨립니다. 따라서 숫자들이 모든 문자들 뒤에 오게 되겠지요.
std::cout << "숫자의 우선순위가 더 낮은 문자열 : " << std::boolalpha << (my_s1 < my_s2) << std::endl;
따라서 실제로 my_s1 이 my_s2 보다 뒤에 온다고 나타나게 됩니다. (my_s1 > my_s2) 반면에 보통의 string 의 경우에는 s1 이 s2 앞에 나오겠지요.
이와 같이 간단히 Traits 만 바꿔주는 것으로 좀더 커스터마이징 된 basic_string 을 사용하실 수 있습니다.
짧은 문자열 최적화 (SSO)
이전에도 이야기 했지만, 메모리를 할당하는 작업은 시간을 꽤나 잡아먹습니다.
basic_string 이 저장하는 문자열의 길이는 천차 만별입니다. 때론 한 두 문자 정도의 짧은 문자열을 저장할 때도 있고, 수십만 바이트의 거대한 문자열을 저장할 때도 있습니다. 문제는 거대한 문자열은 매우 드물게 저장되는데 반해 길이가 짧은 문자열들은 굉장히 많이 생성되고 소멸 된다는 점입니다. 만일 매번 모든 문자열을 동적으로 메모리를 할당 받는다고 해봅시다. 길이가 짧은 문자열을 여러번 할당한다면 매번 메모리 할당이 이루어져야 하므로, 굉장히 비효율적일 것입니다.
따라서 basic_string 의 제작자들은 짧은 길이 문자열의 경우 따로 문자 데이터를 위한 메모리를 할당하는 대신에 그냥 객체 자체에 저장해버립니다. 이를 짧은 문자열 최적화(SSO - short string optimization) 이라고 부릅니다.
#include <iostream> #include <string> // 이와 같이 new 를 전역 함수로 정의하면 모든 new 연산자를 오버로딩 해버린다. // (어떤 클래스의 멤버 함수로 정의하면 해당 클래스의 new 만 오버로딩됨) void* operator new(std::size_t count) { std::cout << count << " bytes 할당 " << std::endl; return malloc(count); } int main() { std::cout << "s1 생성 --- " << std::endl; std::string s1 = "this is a pretty long sentence!!!"; std::cout << "s1 크기 : " << sizeof(s1) << std::endl; std::cout << "s2 생성 --- " << std::endl; std::string s2 = "short sentence"; std::cout << "s2 크기 : " << sizeof(s2) << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
s1 생성 --- 34 bytes 할당 s1 크기 : 32 s2 생성 --- s2 크기 : 32
위와 같이 나옵니다.
// 이와 같이 new 를 전역 함수로 정의하면 모든 new 연산자를 오버로딩 해버린다. // (어떤 클래스의 멤버 함수로 정의하면 해당 클래스의 new 만 오버로딩됨) void* operator new(std::size_t count) { std::cout << count << " bytes 할당 " << std::endl; return malloc(count); }
먼저 메모리가 할당되는지 안되는지 확인하기 위해서 위와 같이 새로 new 연산자를 정의해줬습니다. 참고로 new 의 경우 위와 같이 클래스 외부의 함수로 정의하게 된다면 모든 new 연산자들이 위 함수를 사용하게 됩니다. 반면에 클래스 내에 멤버 함수로 new 를 정의하게 된다면, 해당 객체를 new 로 생성할 때 해당 new 함수가 호출됩니다.
아무튼 위와 같이 operator new 를 정의한 덕분에 basic_string 내부를 바꾸지 않고도 문자열 생성 시에 메모리 할당이 일어나는지 아닌지 관찰할 수 있습니다.
그리고 그 결과는 위와 같습니다. 길이가 긴 문자열 s1 을 생성할 때에는 메모리 할당이 발생하였고, 길이가 짧은 문자열인 s2 의 경우에는 메모리 할당이 발생하지 않았습니다.
그 대신 문자열 객체의 크기를 확인하였을 때 32 바이트로 꽤나 큽니다. 만일 정말 단순하게 문자열 라이브러리를 구현하였다면 문자열 길이를 저장할 변수 하나, 할당한 메모리 공간 크기 저장을 위한 변수 하나, 메모리 포인터 하나로 해소 총 12 바이트로 만들 수 도 있을 것입니다. 하지만 라이브러리 제작자들은 메모리 사용량을 조금 희생한 대신 성능 향상을 꾀했습니다.
물론 라이브러리 마다 어느 길이 문자열 부터 따로 메모리 할당을 할 지는 다릅니다. 하지만 대부분의 주류 C++ 라이브러리 (gcc 의 libstdc++ 과 clang 의 libc++) 들은 어떤 방식이든 SSO 를 사용하고 있습니다.
여담으로, C++ 11 이전에 basic_string 의 구현에서는 Copy On Write 라는 기법도 사용되었습니다. 이는 문자열을 복사할 때, 바로 복사하는 것이 아니라, 복사된 문자열이 바뀔 때 비로소 복사를 수행하는 방식이였죠. 하지만 이는 C++ 11 에서 개정된 표준에 따라 불가능해졌습니다.
문자열 리터럴 정의하기
C 에서 문자열 리터럴을 정의하기 위해선 아래와 같이 하였습니다.
const char* s = "hello"; // 혹은 char s[] = "hello";
그렇다면 위 두 s 모두 "hello" 라는 문자열을 보관하게 됩니다.
C++ 의 경우는 어떨까요? 만약에
auto str = "hello"
를 하면 str 는 string 으로 정의될까요? 아닙니다. C++ 에서는 C 와 마찬가지로 str 의 타입은 const char * 로 정의됩니다. 이는 C 를 배우지 않고 C++ 부터 배우신 분들에게는 혼란스러울 여지가 있습니다. 만일 문자열을 꼭 만들어야겠다 한다면
string str = "hello"
위 처럼 타입을 꼭 명시해줘야 겠죠. 하지만 C++ 14 에 이 문제를 깜찍하게 해결할 수 있는 방법이 나왔습니다.
리터럴 연산자
재미있게도, C++ 14 에서 리터럴 연산자(literal operator) 라는 것이 새로 추가되었습니다.
auto str = "hello"s;
위와 같이 "" 뒤에 s 를 붙여주면 auto 가 string 으로 추론됩니다. 참고로 이 리터럴 연산자는
std::string operator"" s(const char *str, std::size_t len);
위 처럼 정의되어 있는데, "hello"s 는 컴파일 과정에서 operator""s("hello", 5); 로 바뀌게 됩니다. 참고로 해당 리터럴 연산자를 사용하기 위해서는 std::string_literals 네임 스페이스를 사용해야 합니다. 아래 코드를 보시죠
#include <iostream> #include <string> using namespace std::literals; int main() { auto s1 = "hello"s; std::cout << "s1 길이 : " << s1.size() << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
s1 길이 : 5
와 같이 제대로 string 으로 auto 가 추론된 것을 확인할 수 있습니다.
리터럴 연산자는 위 처럼 문자열 리터럴만 가능한 것이 아니라 정수나 부동 소수점 리터럴들 역시 사용 가능합니다. 자세한 예시는 여기를 살펴보세요.
그 외의 여러가지 리터럴 정의 방법
사실 C++ 에는 "" 말고도 문자열 리터럴을 정의하는 몇 가지 방법이 더 있습니다.
std::string str = "hello"; // char[] std::wstring wstr = L"hello"; // wchar_t[]
일단 그냥 "hello" 를 했다면 여러분이 생각한 대로 char 배열을 생성하게 됩니다. 하지만 wchar_t 문자열을 만들고 싶다면 앞에 그냥 L 을 붙여주면 됩니다. 그러면 컴파일러가 알아서 wchar_t 배열을 만들어줍니다. 그 외에도 몇 가지가 더 있습니다. 자세한 내용은 여기 를 참조해주세요.
C++ 11 에 추가된 유용한 기능으로 Raw string literal 이라는 것이 생겼습니다. 아래 코드를 보시지요.
#include <iostream> #include <string> int main() { std::string str = R"(asdfasdf 이 안에는 어떤 것들이 와도 // 이런것도 되고 #define hasldfjalskdfj \n\n <--- Escape 안해도 됨 )"; std::cout << str; }
성공적으로 컴파일 하였다면
실행 결과
asdfasdf 이 안에는 어떤 것들이 와도 // 이런것도 되고 #define hasldfjalskdfj \n\n <--- Escape 안해도 됨
와 같이 나옵니다. R"()" 안에 오는 문자들은 모두 문자 그대로 char 배열 안에 들어가게 됩니다. 예를 들어서 이전에 "" 안에 \ 를 입력하기 위해서는 \\ 와 같이 써야 하고, " 를 입력하려면 \" 와 같이 해야 했지만, 위 경우 \ 을 넣으려면 그냥 \ 를 쓰고 " 을 넣으려면 그냥 " 를 쓰면 됩니다. 출력 결과를 보면 개행 문자 역시 그대로 잘 들어갔음을 알 수 있습니다.
다만 한 가지 문제는 닫는 괄호 )" 를 문자열 안에 넣을 수 없다는 점입니다. 하지만 이는 구분 문자를 추가함으로써 해결할 수 있습니다.
#include <iostream> #include <string> int main() { std::string str = R"foo( )"; <-- 무시됨 )foo"; std::cout << str; }
성공적으로 컴파일 하였다면
실행 결과
)"; <-- 무시됨
와 같이 잘 나옵니다. Raw string 문법을 정확히 살펴보자면
R"/* delimiter */( /* 문자열 */ )/* delimiter */"
꼴로 쓰면 됩니다. delimiter 자리는 아무것도 없어도 되고, 위처럼 여러분이 원하는 문자열이 와도 되는데, 앞의 delimiter 와 뒤의 delimiter 는 같아야 합니다. 문법이 복잡하다고 느끼신다면 그냥 "delimiter( 가 하나의 괄호라고 생각하시면 됩니다.
C++ 에서 한글 다루기
아무래도 이 글을 읽으시는 분들은 한국사람일 테니, 한글로 된 문자열 을 다룰 일이 매우 많을 것이라 생각합니다. 하지만 한글을 다루는 일은 생각보다 복잡합니다.
처음에 컴퓨터가 만들어졌을 때, 대부분 영미권 국가에서 사용하였기 때문에 문자를 표현하는데 1 바이트 (= 255 개) 로도 충분하였습니다. 하지만 점차 전세계적으로 사용이 확대대면서 세계 각국의 문자를 나타내는 데에는 한계를 느끼게 되었죠.
이에 전세계 모든 문자들을 컴퓨터로 표현할 수 있도록 설계된 표준이 바로 유니코드(Unicode) 입니다. 유니코드는 모든 문자들에 고유의 값을 부여하게 됩니다.
예를 들어서 한글의 가 는0xAC00 의 값을 부여 받았고, 그 다음에 오는 문자가 각 으로 0xAC01 이 됩니다. 참고로 0 부터 0x7F 까지는 기존에 사용되던 아스키 테이블과 호환을 위해 동일합니다. 즉, 영어 알파벳 A 의 경우 그대로 0x41 입니다.현재 유니코드에 등록되어 있는 문자들의 개수는 대략 14 만 개 정도 되므로, 문자 하나를 한 개의 자료형에 보관하기 위해서는 최소 int 를 사용해야 합니다. (1 바이트나 2 바이트로는 불가)
127 사이 이므로 1 바이트 문자만 사용해도 전부 표현할 수 있기 때문이죠.그래서 등장한 것이 바로 인코딩(Encoding) 방식 입니다. 인코딩 방식에 따라 컴퓨터에서 문자를 표현하기 위해 동일하게 4 바이트를 사용하는 대신에, 어떤 문자는 1 바이트, 어떤 건 2 바이트 등등의 길이로 저장하게 됩니다. 유니코드에서는 아래와 같이 3 가지 형식의 인코딩 방식을 지원하고 있습니다.
UTF-8 : 문자를 최소 1 부터 최대 4 바이트로 표현한다. (즉 문자마다 길이가 다르다!)
UTF-16 : 문자를 2 혹은 4 바이트로 표현한다.
UTF-32 : 문자를 4 바이트로 표현한다.
UTF-32 의 경우 모든 문자들을 4 바이트로 할당하기 때문에 다루기가 매우 간단합니다. 예를 들어서 아래 코드를 살펴봅시다.
#include <iostream> #include <string> int main() { // 1234567890 123 4 567 std::u32string u32_str = U"이건 UTF-32 문자열 입니다"; std::cout << u32_str.size() << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
17
과 같이 나옵니다.
std::u32string u32_str = U"이건 UTF-32 문자열 입니다";
u32string 은 C++ 에서 UTF-32 로 인코딩 된 문자열을 보관하는 타입이고, "" 앞에 붙은 U 는 해당 문자열 리터럴이 UTF-32 로 인코딩 하라는 의미 입니다. 앞서 말했듯이 UTF-32 는 모든 문자들을 동일하게 4 바이트로 나타내기 때문에 문자열의 원소 개수와 실제 문자열의 크기가 일치합니다.
실제로도 u32_str.size() 를 했을 때 출력한 결과와 문자열의 실제 길이가 일치함을 알 수 있습니다.
UTF-8 인코딩
UTF-32 방식의 인코딩은 다루기에 직관적이기는 하지만 자주 사용되는 인코딩 방식은 아닙니다. 왜냐하면 모든 문자에 4 바이트 씩 할당하는 것이 매우 비효율적이기 때문이죠. 그렇다면 현재 웹 상에서 많이 사용되는 UTF-8 인코딩 방식은 어떤지 살펴봅시다.
#include <iostream> #include <string> int main() { // 12 345678901 2 3456 std::string str = u8"이건 UTF-8 문자열 입니다"; std::cout << str.size() << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
32
와 같이 나옵니다. 먼저 UTF-8 형식의 문자열을 만들기 위해서는
std::string str = u8"이건 UTF-8 문자열 입니다";
와 같이 "" 앞에 u8 을 써주면 됩니다. 그리고 대부분의 시스템의 경우 굳이 u8 을 안붙여도 파일의 형식이 UTF-8 일 것이므로 알아서 UTF-8 문자열이 될 것입니다.
문제는 위 프로그램 결과 입니다. 무언가 이상하죠?
분명히 문자열의 길이는 16 인데, 실제 출력된 것은 32 가 나왔습니다. 이는 UTF-8 인코딩 방식이 문자들에 최소 1 바이트 부터 최대 4 바이트 까지 지정하기 때문입니다. 일단 최소 단위가 1 바이트 이므로, UTF-8 인코딩 방식의 문자열은 char 원소들로 보관하는데, 어떤 문자는 char 1 개 만으로 충분하고, 어떤 원소는 char 원소 2 개, 3 개, 아니면 4 개 까지 필요로 하게 됩니다.
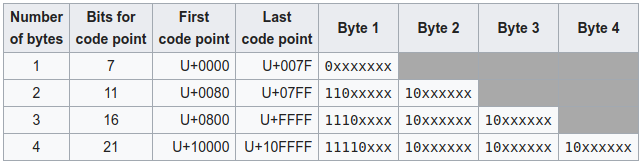
위 표는 유니코드 별로 어떻게 UTF-8 로 인코딩 되는지 설명하고 있습니다. 예를 들어서 0 부터 0x7F 까지의 문자들은 1 바이트, 그 다음 0x80 부터 0x7FF 까지 문자들은 2 바이트, 0x800 부터 0xFFFF 까지는 3 바이트, 그리고 나머지가 4 바이트로 지정됩니다. 한글의 경우 0xAC00 부터 0xD7AF 까지 걸쳐 있으므로 전부 3 바이트로 표현됩니다.
이건 UTF-8 문자열 입니다 에는 한글이 8 개 있고, 영어 알파벳, 공백 문자, - 가 8 개 있습니다. 한글은 3 바이트, 나머지 애들은 1 바이트로 표현되므로 총 , 총 32 개의 char 이 필요 합니다.
std::string 은 문자열이 어떤 인코딩으로 이루어져 있는지 관심이 없습니다. 그냥 단순하게 char 의 나열로 이루어져 있다고 생각합니다. 따라서 str.size() 를 했을 때, 문자열의 실제 길이가 아니라 그냥 char 이 몇 개가 있는지 알려줍니다. 따라서 위와 같이 32 가 출력되었습니다.
문제는 string 단에서 각각의 문자를 구분하지 못하기 때문에 불편함이 이만 저만이 아니라는 점입니다. 예를 들어서 두 번째 문자('건')를 추출하고 싶다면
// "건" 이 나와야 할 것 같지만 실제로는 이상한 것이 나온다. std::cout << str[1];
와 같이 하면 될 것 같지만 실제로는 이상한 결과가 나옵니다. 아마 출력된 것은 이 의 UTF-8 인코딩의 두 번째 바이트 이고, 해당 값은 UTF-8 인코딩에서 불가능한 값입니다.
그렇다고 해서 C++ 에서 UTF-8 문자열을 분석할 수 없다는 것은 아닙니다. 아래 처럼 하나씩 차례대로 읽어나가면 됩니다.
#include <iostream> #include <string> int main() { // 1 234567890 1 2 34 5 6 std::string str = u8"이건 UTF-8 문자열 입니다"; size_t i = 0; size_t len = 0; while (i < str.size()) { int char_size = 0; if ((str[i] & 0b11111000) == 0b11110000) { char_size = 4; } else if ((str[i] & 0b11110000) == 0b11100000) { char_size = 3; } else if ((str[i] & 0b11100000) == 0b11000000) { char_size = 2; } else if ((str[i] & 0b10000000) == 0b00000000) { char_size = 1; } else { std::cout << "이상한 문자 발견!" << std::endl; char_size = 1; } std::cout << str.substr(i, char_size) << std::endl; i += char_size; len++; } std::cout << "문자열의 실제 길이 : " << len << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
이 건 U T F - 8 문 자 열 입 니 다 문자열의 실제 길이 : 16
와 같이 잘 나옵니다.
코드를 살펴보면 매우 간단합니다. 예를 들어서 첫 번째 if 문을 살펴봅시다.
if ((str[i] & 0b11111000) == 0b11110000)
앞서 위에 있는 UTF-8 인코딩 방식을 살펴보면, 4 바이트로 인코딩되는 문자들은 첫 번째 바이트가 11110xxx 꼴입니다. 11111000 과 AND 연산을 했을 때 11110000 이 나오는 비트 형태는 11110xxx 형태 밖에 없으므로 성공적으로 분류를 하고 있다고 알 수 있습니다.
나머지 조건문들도 마찬가지 입니다.
std::cout << str.substr(i, char_size) << std::endl;
그리고 위 처럼 문자의 시작 위치에서 char_size 만큼을 읽어서 인코딩 된 문자를 정확하게 출력할 수 있습니다.
물론 UTF-8 형식의 문자열을 저장햇다고 해서 basic_string 의 정의된 연산들을 사용할 수 없는 것은 아닙니다. size() 를 제외한 다른 모든 연산들은 문자열의 인코딩 방식과 무관합니다. 예를 들어서 문자열에서 원하는 글자를 검색하는 것은 인코딩과 무관하게 수행할 수 있습니다.
하지만 그래도 UTF-8 문자 그대로 한글 문자열을 다루는 것은 불편합니다. 특히 영문자와 섞여 있을 경우 알파벳은 1 바이트지만 한글은 3 바이트로 해석되기 때문에 반복자를 통해서 문자들을 순차적으로 뽑아내기 힘들지요. 하지만 UTF-16 인코딩 방식을 사용하면 이야기가 달라집니다.
UTF-16 인코딩
UTF-16 인코딩은 최소 단위가 2 바이트 입니다. 따라서 UTF-16 으로 인코딩 된 문자열을 저장하는 클래스인 u16string 도 원소의 타입이 2 바이트 (char16_t) 입니다.
UTF-16 은 유니코드에서 0 부터 D7FF 번 까지, 그리고 E000 부터 FFFF 까지의 문자들을 2 바이트로 인코딩 합니다. 그리고 FFFF 보다 큰 문자들은 4 바이트로 인코딩 되지요. 참고로 D800 번 부터 DFFF 사이의 문자들은 어디에 인코딩 되냐고 물을 수 있는데, 이들은 유니코드 상 존재하지 않는 문자들 입니다.
덕분에 UTF-16 인코딩 방식으로는 대부분의 문자들이 2 바이트로 인코딩 됩니다. 알파벳, 한글, 한자 전부다 말이지요. 물론 이모지(🍑,🍒,🍓,🍔,🍕,🍖,🍗)나 이집트 상형문자(𓀀,𓀁,𓀂)와 같이 유니코드 상 높은 번호로 매핑되어 있는 애들은 4 바이트로 인코딩 됩니다.
#include <iostream> #include <string> int main() { // 1234567890 123 4 567 std::u16string u16_str = u"이건 UTF-16 문자열 입니다"; std::cout << u16_str.size() << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
17
와 같이 나옵니다.
만일 여러분이 일반적인 문자들만 수록되어 있는 텍스트를 다루신다면 u16string 을 사용하는 것 만큼 좋은 것이 없습니다. 거의 대부분의 문자들이 2 바이트로 인코딩 될 것이므로, 모든 문자들이 원소 1 개 만큼씩을 사용합니다. 따라서 위 처럼 문자열의 길이와 u16_str.size() 가 일치하겠지요.
따라서 아래와 같이 한글의 초성만 분리해내는 코드를 작성할 수 도 있습니다.
#include <iostream> #include <string> int main() { std::u16string u16_str = u"안녕하세용 모두에 코드에 오신 것을 환영합니다"; std::string jaum[] = {"ㄱ", "ㄲ", "ㄴ", "ㄷ", "ㄸ", "ㄹ", "ㅁ", "ㅂ", "ㅃ", "ㅅ", "ㅆ", "ㅇ", "ㅈ", "ㅉ", "ㅊ", "ㅋ", "ㅌ", "ㅍ", "ㅎ"}; for (char16_t c : u16_str) { // 유니코드 상에서 한글의 범위 if (!(0xAC00 <= c && c <= 0xD7A3)) { continue; } // 한글은 AC00 부터 시작해서 한 초성당 총 0x24C 개 씩 있다. int offset = c - 0xAC00; int jaum_offset = offset / 0x24C; std::cout << jaum[jaum_offset]; } }
성공적으로 컴파일 하였다면
실행 결과
ㅇㄴㅎㅅㅇㅁㄷㅇㅋㄷㅇㅇㅅㄱㅇㅎㅇㅎㄴㄷ
위와 같이 잘 분리되었음을 알 수 있습니다. 한글은 유니코드 상에서 한 초성 당 588 개 씩 있습니다. 예를 들어 처음에 가 를 시작으로, 각, 갂, 간 순으로 진행되지요. 여기 에서 한글이 어떻게 유니코드 상에서 등록되어 있는지 볼 수 있습니다. 머리를 좀만 쓴다면, 초성-중성-종성 분리 까지 쉽게 가능합니다.
하지만 UTF-16 역시 때론 4 바이트로 문자를 인코딩 해야 하기 때문에 i 번째 문자를 str[i] 와 같이 접근할 수 있는 것은 아닙니다. 예를 들어서;
#include <iostream> #include <string> int main() { std::u16string u16_str = u"🍑🍒"; std::cout << u16_str.size() << std::endl; }
성공적으로 컴파일 하였을 경우
실행 결과
4
위와 같이 실제 문자열의 길이와 사용된 원소의 개수가 차이가 나게 됩니다.
안타깝게도 C++ 에서는 요즘에 나온 Go 언어 처럼 인코딩 된 문자열을 언어 단에서 간단히 처리할 수 있는 방법은 없습니다. 가장 편한 방법은 그냥 어떤 문자열이든 그냥 UTF-32 인코딩으로 바꿔버리면 되겠지만, 이는 메모리 사용량을 매우 증가시킵니다.
다행이도 UTF8-CPP 라는 C++ 에서 여러 방식으로 인코딩 된 문자열을 쉽게 다룰 수 있게 도와주는 라이브러리가 있습니다 (표준 라이브러리는 아닙니다). 여기에서 사용법을 볼 수 있으며 매우 간단합니다!
string_view
자 그럼 이번에는 좀 더 다른 주제에 대해 이야기 해보도록 하겠습니다. 만일 어떤 함수에다 문자열을 전달할 때, 문자열 읽기 만 필요로 한다면 보통 const std::string& 으로 받던지 아니면 const char* 형태로 받게 됩니다.
하지만 각각의 방식은 문제점이 있습니다. 먼저 const string& 형태로 받을 경우를 살펴봅시다.
#include <iostream> #include <string> void* operator new(std::size_t count) { std::cout << count << " bytes 할당 " << std::endl; return malloc(count); } // 문자열에 "very" 라는 단어가 있으면 true 를 리턴함 bool contains_very(const std::string& str) { return str.find("very") != std::string::npos; } int main() { // 암묵적으로 std::string 객체가 불필요하게 생성된다. std::cout << std::boolalpha << contains_very("c++ string is very easy to use") << std::endl; std::cout << contains_very("c++ string is not easy to use") << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
31 bytes 할당 true 30 bytes 할당 false
와 같이 나옵니다.
contains_very 함수는 인자로 받은 문자열에 very 라는 단어가 있으면 true 를 리턴하는 함수 입니다. 따라서 인자를 읽기 만 하므로, const string& 의 형태로 받으면 됩니다.
문제는 contains_very 함수에 문자열 리터럴을 전달한다면 (이는 const char*), 인자는 string 만 받을 수 있기 때문에 암묵적으로 string 객체가 생성된다는 점입니다. 따라서 위 출력 결과 처럼 불필요한 메모리 할당이 발생한 것을 볼 수 있습니다.
그렇다면 contains_very 함수를 const char* 형태의 인자로 받도록 바꾸면 안될까요? 그렇다면 두 가지 문제가 발생합니다.
먼저 string 을 함수에 직접 전달할 수 없고 c_str 함수를 통해 string 에서
const char*주소값을 뽑아내야 합니다.const char*로 변환하는 과정에서 문자열의 길이에 대한 정보를 읽어버리게 됩니다. 만일 함수 내부에서 문자열 길이 정보가 필요 하다면 매 번 다시 계산해야 합니다.
이러한 연유로, contains_very 함수를 합리적으로 만들기 위해서는 const string& 을 인자로 받는 오버로딩 하나, 그리고 const char* 을 인자로 받는 오버로딩 하나를 각각 준비해야 한다는 문제점이 있었습니다.
하지만 위와 같은 문제는 C++ 17 에서 string_view 가 도입됨으로써 해결되었습니다.
소유하지 않고 읽기만 한다!
#include <iostream> #include <string> void* operator new(std::size_t count) { std::cout << count << " bytes 할당 " << std::endl; return malloc(count); } // 문자열에 "very" 라는 단어가 있으면 true 를 리턴함 bool contains_very(std::string_view str) { return str.find("very") != std::string_view::npos; } int main() { // string_view 생성 시에는 메모리 할당이 필요 없다. std::cout << std::boolalpha << contains_very("c++ string is very easy to use") << std::endl; std::cout << contains_very("c++ string is not easy to use") << std::endl; std::string str = "some long long long long long string"; std::cout << "--------------------" << std::endl; std::cout << contains_very(str) << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
true false 37 bytes 할당 -------------------- false
와 같이 나옵니다.
string_view 는 이름 그대로 문자열을 읽기 만 하는 클래스 입니다. 이 때문에 string_view 는 문자열을 소유하고 있지 않습니다. 즉, 어딘가 존재하는 문자열을 참조해서 읽기만 하는 것이지요. 따라서 string_view 가 현재 보고 있는 문자열이 소멸된다면 정의되지 않은 작업(Undefined behavior)이 발생하게 됩니다.
주의 사항
중요해서 한 번 더 강조하지만 string_view 는 문자열을 소유하고 있지 않기 때문에 현재 읽고 있는 문자열이 소멸되지 않은 상태인지 주의해야 합나다.
하지만 문자열을 소유하지 않고 읽기 만 한다는 특성 때문에 string_view 객체 생성시에 메모리 할당이 불필요 합니다. 그냥 읽고 있는 문자열의 시작 주소값만 복사하면 되기 때문이죠. 따라서 위 처럼 string 이나 const char* 을 전달하더라도 메모리 할당이 발생하지 않습니다.
뿐만 아니라 const char* 을 인자로 받았을 때에 비해 string 의 경우 문자열 길이가 그대로 전달되므로 불필요한 문자열 길이 계산을 할 필요가 없습니다. 또한 const char* 에서 string_view 를 생성하면서 문자열 길이를 한 번만 계산하면 되므로 효율적입니다.
string_view 에서 제공하는 연산들은 당연히도 원본 문자열을 수정하지 않는 연산들 입니다. 대표적으로 find 와 부분 문자열을 얻는 substr 을 들 수 있습니다. 특히 string 의 경우 substr 이 실제로 부분 문자열을 새로 생성해야 하기 때문에 으로 수행되지만, string_view 의 경우 substr 로 또다른 view 를 생성하므로 로 매우 빠르게 수행됩니다.
#include <iostream> #include <string> void* operator new(std::size_t count) { std::cout << count << " bytes 할당 " << std::endl; return malloc(count); } int main() { std::cout << "string -----" << std::endl; std::string s = "sometimes string is very slow"; std::cout << "--------------------" << std::endl; std::cout << s.substr(0, 20) << std::endl << std::endl; std::cout << "string_view -----" << std::endl; std::string_view sv = s; std::cout << "--------------------" << std::endl; std::cout << sv.substr(0, 20) << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
string ----- 30 bytes 할당 -------------------- 21 bytes 할당 sometimes string is string_view ----- -------------------- sometimes string is
와 같이 나옵니다.
보시다시피, string 의 substr 은 문자열을 새로 생성하였기에 메모리 할당이 발생하였지만 string_view 의 경우 substr 시에 메모리 할당이 발생하지 않았습니다.
물론 위 string_view 들은 모두 s 에서 만들어진 것이므로 s 가 소멸되면 사용할 수 없게 됩니다. 예를 들어 아래 예제를 보실까요.
#include <iostream> #include <string> std::string_view return_sv() { std::string s = "this is a string"; std::string_view sv = s; return sv; } int main() { std::string_view sv = return_sv(); // <- sv 가 가리키는 s 는 이미 소멸됨! // Undefined behavior!!!! std::cout << sv << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
a string
와 같이 이상하게 나올 것입니다.
std::string_view sv = return_sv(); // <- sv 가 가리키는 s 는 이미 소멸됨!
위 sv 는 return_sv 안에서 만들어진 s 의 string_view 이지만 함수가 리턴하면서 지역 객체였던 s 가 소멸하였기 때문에 sv 는 소멸된 문자열을 가리키는 꼴이 되었습니다.
따라서 sv 를 사용하면 위와 같이 이상한 결과가 나옵니다 (물론 프로그램을 crash 시킬 수 도 있겠지요). 반드시 string_view 가 살아 있는 문자열의 view 인지를 확인하고 사용해야 합니다.
자 그럼 이것으로 이번 강좌를 마치도록 하겠습니다. 이번 강좌를 통해서 C++ 에서 제공되는 string 라이브러리와 string_view 라이브러리의 강력함을 알아보셨으면 합니다.
뭘 배웠지?
std::string 은 basic_string 의 char 을 인자로 갖는 템플릿 인스턴스화 버전입니다. 그 외에도 u8string, u16string, u32string 이 있고 각각은 UTF-8, UTF-16, UTF-32 으로 인코딩 된 문자열을 보관할 수 있습니다.
std::char_traits 를 사용해서 사용자가 원하는 기능을 가진 문자열을 생성할 수 있습니다.
유니코드는 전세계의 모든 문자들을 컴퓨터에서 표현하고자 각각의 문자에 대해 고유의 코드를 부여한 것입니다. 코드 그대로 그냥 저장하려면 4 바이트가 필요한데, 이는 매우 비효율적이므로 여러가지 인코딩 을 통해서 크기를 줄일 수 있습니다. 하지만 이 때문에 문자별로 인코딩 되는 길이가 다르다는 문제점이 있습니다.
string_view 를 통해서 불필요한 복사를 막고 const char* 과 const string& 사이에서 깔끔하게 처리할 수 있습니다.

댓글을 불러오는 중입니다..