모두의 코드
씹어먹는 C ++ - <15 - 2. C++ 뮤텍스(mutex) 와 조건 변수(condition variable)>
이번 강좌에서는
경쟁 상태 (Race Condition)
뮤텍스 (mutex) 와 데드락 (deadlock)
생산자 - 소비자 패턴
condition_variable
에 대해 다룹니다.

안녕하세요 여러분!
지난 강좌에서 보았듯이, 서로 다른 쓰레드에서 같은 메모리를 공유할 때 발생할 수 있는 문제를 보았습니다. 이와 같이 서로 다른 쓰레드들이 동일한 자원을 사용할 때 발생하는 문제를 경쟁 상태(race condtion) 이라 부릅니다. 이 경우 counter 라는 변수에 race condtion 이 있었습니다.
Race Condition
그 코드를 다시 가져오면 아래와 같습니다.
#include <iostream> #include <thread> #include <vector> void worker(int& counter) { for (int i = 0; i < 10000; i++) { counter += 1; } } int main() { int counter = 0; std::vector<std::thread> workers; for (int i = 0; i < 4; i++) { // 레퍼런스로 전달하려면 ref 함수로 감싸야 한다 (지난 강좌 bind 함수 참조) workers.push_back(std::thread(worker, std::ref(counter))); } for (int i = 0; i < 4; i++) { workers[i].join(); } std::cout << "Counter 최종 값 : " << counter << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
Counter 최종 값 : 26459
왜 이런 문제가 발생하였을까요?
counter += 1;
문제는 위 명령에 있습니다. 컴퓨터에 입장에서 생각해봅시다. counter += 1; 을 하기 위해서는 어떠한 과정이 필요할까요?
이를 이해하기 위해서는 CPU 에서 연산을 어떻게 처리하는지 알아야 합니다.
CPU 간단 소개
CPU 는 말했듯이 컴퓨터의 모든 연산이 발생하는 두뇌 라고 볼 수 있습니다. CPU 에서 연산을 수행하기 위해서는, CPU 의 레지스터(register) 라는 곳에 데이터를 기록한 다음에 연산을 수행해야 합니다.
레지스터의 크기는 매우 작습니다. 64 비트 컴퓨터의 경우, 레지스터의 크기들이 8 바이트에 비해 불과합니다. 뿐만 아니라 레지스터의 개수는 그리 많지 않습니다. 일반적인 연산에서 사용되는 범용 레지스터의 경우 불과 16 개 밖에 없습니다.

즉, 모든 데이터들은 메모리에 저장되어 있고, 연산 할 때 할 때 마다 메모리에서 레지스터로 값을 가져온 뒤에, 빠르게 연산을 하고, 다시 메모리에 가져다 놓는 식으로 작동을 한다고 보시면 됩니다.
쉽게 말하자면, 메모리는 냉장고 이고 CPU 의 레지스터는 도마 라고 보시면 됩니다. 냉장고 (RAM) 에서 재료를 도마 위에 하나 (레지스터) 꺼내서 후다닥 썰고 (연산) 다시 냉장고로 가져다 놓는 거라 생각하면 됩니다.
그렇다면 counter += 1 이 실제로 어떠한 코드로 컴파일되는지 살펴봅시다.
mov rax, qword ptr [rbp - 8] mov ecx, dword ptr [rax] add ecx, 1 mov dword ptr [rax], ecx
흠, 조금 무섭게 생겼습니다. 위와 같은 코드를 어셈블리(Assembly) 코드라고 부릅니다. 어셈블리 코드는 CPU 가 실제로 실행하는 기계어와 1 대 1 대응이 되어 있습니다. 따라서, 위 명령을 한줄 한줄 CPU 가 처리한다고 생각해도 무방합니다.
이해하기 매우 어렵게 생겼지만 사실 하나씩 뜯어보면 크게 어렵지 않습니다. 먼저 첫번째 줄 부터 살펴봅시다.
mov rax, qword ptr [rbp - 8]
rax 와 rbp 모두 CPU 의 레지스터를 의미합니다. mov 는 이 문장이 어떤 명령을 하는지 나타내는데, 이름에서도 짐직할 수 있듯이 대입(move) 명령 입니다. 즉, [rbp - 8] 이 rax 에 대입 됩니다.
이 때 [] 의 의미는 역참조, 즉 rbp - 8 을 주소값이라 생각했을 때 해당 주소에 있는 값을 읽어라 라는 의미가 되겠습니다. C++ 에서 포인터에 * 연산을 하는 것과 동일합니다. 그런데, 이 때 값을 읽기 위해 해당 주소부터 얼마나 읽어야 하는지 명시해야합니다. 이는 qword 라는 단어에서 알 수 있는데, qword 는 8 바이트를 의미합니다. (주소값의 크기가 8 바이트 이지요!)
즉, C++ 의 언어로 풀어 쓰자면
rax = *(int**)(rbp - 8)
가 되겠습니다.
실제로 위 명령에서 무슨 짓을 하고 있는 것이냐면 현재 rbp - 8 에는 counter 의 주소값이 담겨 있어서 rax 에 counter 의 주소값을 복사하고 있는 과정입니다. 그렇다면 그 아래 문장이 바로 이해가 되시겠지요?
mov ecx, dword ptr [rax]
현재 rax 에는 result 의 주소값이 담겨 있습니다. 따라서 ecx 에는 result 의 현재 값이 들어가게 되니다. 위 문장은
ecx = *(int*)(rax); // rax 에는 &result 가 들어가 있음
와 동일합니다.
자 이제 그 다음 문장 입니다.
add ecx, 1
언뜩 봐도 알 수 있듯이 ecx 에 1 을 더하는 명령 입니다. 즉, result 에 1 이 더해집니다.
mov dword ptr [rax], ecx
마지막으로 result 에 이전의 result 에 1 이 더해진 값이 저장됩니다.
참고로 ecx 없이
mov rax, qword ptr [rbp - 8] add dword ptr [rax], 1
이렇게 하면 안되냐고 생각할 수 있는데, 이는 CPU 의 구조상 add 명령은 역참조한 메모리에서 직접 사용할 수 없고 반드시 레지스터에만 내릴 수 있습니다. (냉장고 안에서 직접 요리를 할 수 없으니까요!)
자 그러면, 왜 이제 counter 의 값이 이상하게 나왔는지 짐작하실 수 있나요?

위 그림과 같은 상황을 생각해봅시다. 처음에 counter 가 0 이였다고 가정하고, 쓰레드 1 에서
mov rax, qword ptr [rbp - 8] mov ecx, dword ptr [rax]
딱 여기 까지 실행하였다고 생각해봅시다. 그러면 이 시점에서 쓰레드 1 의 ecx 레지스터에는 counter 의 초기값인 0 이 들어가게 됩니다.
다음에 쓰레드 2 에서 전체 명령을 모두 실행합니다. 현재 쓰레드 1 이 counter 의 값을 바꾸지 않은 상태이기 때문에 쓰레드 2 에서 읽은 counter 의 값도 역시 0 입니다. 따라서 쓰레드 2 가 counter += 1 을 마쳤을 때에는 counter 에는 1 이 들어가 있겠지요.
다시 쓰레드 1 의 차례 입니다. 쓰레드 1 에서 나머지
add ecx, 1 mov dword ptr [rax], ecx
부분을 실행하였습니다. 이 때 쓰레드 1 의 ecx 는 0 이였으므로, add ecx, 1 후에 ecx 역시 1 이 됩니다. 결국 counter 에는 2 가 아닌 1 이 기록됩니다.
물론 운이 좋다면 쓰레드 1 에서 중간에 쓰레드 2 가 실행되는 일 없이 쭉 실행해서 정상적으로 counter 에 2 가 들어갔을 수 도 있습니다. 하지만, 쓰레드를 어떻게 스케쥴링 할지는 운영체제가 마음대로 결정하는 것이기 때문에 우리는 그런 행운을 항상 바랄 수 없습니다.
이게 멀티쓰레딩의 재밌는 점입니다. 여태까지 여러분이 실행한 모든 프로그램은 몇 번을 실행 하건 결과가 동일하게 나왔습니다. 하지만, 멀티 쓰레드 프로그램의 경우 프로그램 실행 마다 그 결과가 달라질 수 있습니다.
이게 무슨 말일까요? 제대로 프로그램을 만들지 않았을 경우 디버깅이 겁나 어렵다는 뜻입니다.
뮤텍스 (mutex)
그렇다면 위 문제를 어떻게 하면 해결할 수 있을까요? 위 문제가 발생한 근본적인 이유는
counter += 1;
위 부분을 여러 쓰레드에서 동시에 실행시켰기 때문이지요. 그렇다면 만약에 어떤 경찰관 같은 역할을 하는 것이 있어서, 한 번에 한 쓰레드에서만 위 코드를 실행시킬 수 있다면 어떨까요?

그렇다면 우리가 앞서 말한 문제를 완벽히 해결할 수 있을 것입니다. 그리고 다행이도 C++ 에선 이러한 기능을 하는 객체를 제공하고 있습니다. 바로 뮤텍스(mutex) 라고 불리는 것입니다.
#include <iostream> #include <mutex> // mutex 를 사용하기 위해 필요 #include <thread> #include <vector> void worker(int& result, std::mutex& m) { for (int i = 0; i < 10000; i++) { m.lock(); result += 1; m.unlock(); } } int main() { int counter = 0; std::mutex m; // 우리의 mutex 객체 std::vector<std::thread> workers; for (int i = 0; i < 4; i++) { workers.push_back(std::thread(worker, std::ref(counter), std::ref(m))); } for (int i = 0; i < 4; i++) { workers[i].join(); } std::cout << "Counter 최종 값 : " << counter << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
Counter 최종 값 : 40000
와 같이 제대로 나오는 것을 알 수 있습니다.
std::mutex m; // 우리의 mutex 객체
일단 위와 같이 뮤텍스 객체를 정의 하였습니다. mutex 라는 단어는 영어의 상호 배제 (mutual exclusion) 라는 단어에서 따온 단어 입니다.
void worker(int& result, std::mutex& m)
뮤텍스를 각 쓰레드에서 사용하기 위해 위와 같이 전달하였고;
m.lock(); result += 1; m.unlock();
실제 사용하는 것은 위와 같습니다.
m.lock() 은 뮤텍스 m 을 내가 쓰게 달라! 라고 이야기 하는 것입니다. 이 때 중요한 사실은, 한 번에 한 쓰레드에서만 m 의 사용 권한을 갖는다는 것입니다. 그렇다면, 다른 쓰레드에서 m.lock() 을 하였다면 어떻게될까요? 이는 m 을 소유한 쓰레드가 m.unlock() 을 통해 m 을 반환할 때 까지 무한정 기다리게 됩니다.
따라서, result += 1; 은 아무리 많은 쓰레드들이 서로 다른 코어에서 돌아가고 있더라고 하더라도, 결국 m 은 한 번에 한 쓰레드만 얻을 수 있기 때문에, result += 1; 은 결국 한 쓰레드만 유일하게 실행할 수 있게 됩니다.
이렇게 m.lock() 과 m.unlock() 사이에 한 쓰레드만이 유일하게 실행할 수 있는 코드 부분을 임계 영역(critical section) 이라고 부릅니다.
만약에 까먹고 m.unlock() 을 하지 않는다면 어떻게 될까요?
#include <iostream> #include <mutex> // mutex 를 사용하기 위해 필요 #include <thread> #include <vector> void worker(int& result, std::mutex& m) { for (int i = 0; i < 10000; i++) { m.lock(); result += 1; } } int main() { int counter = 0; std::mutex m; // 우리의 mutex 객체 std::vector<std::thread> workers; for (int i = 0; i < 4; i++) { workers.push_back(std::thread(worker, std::ref(counter), std::ref(m))); } for (int i = 0; i < 4; i++) { workers[i].join(); } std::cout << "Counter 최종 값 : " << counter << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
(끝나지 않아서 강제 종료)
와 같이 나옵니다. 위와 같이 프로그램이 끝나지 않아서 강제로 종료해야만 합니다.
뮤텍스를 취득한 쓰레드가 unlock 을 하지 않으므로, 다른 모든 쓰레드들이 기다리게 됩니다. 심지어 본인도 마찬가지로 m.lock() 을 다시 호출하게 되고, unlock 을 하지 않았기에 본인 역시 기다리게 되죠.
결국 아무 쓰레드도 연산을 진행하지 못하게 됩니다. 이러한 상황을 데드락(deadlock) 이라고 합니다.
위와 같은 문제를 해결하기 위해서는 취득한 뮤텍스는 사용이 끝나면 반드시 반환을 해야 합니다. 하지만 코드 길이가 길어지게 된다면 반환하는 것을 까먹을 수 있기 마련입니다.
곰곰히 생각해보면 이전에 비슷한 문제를 해결한 기억이 있습니다. unique_ptr 를 왜 도입을 하였는지 생각을 해보자면, 메모리를 할당 하였으면 사용 후에 반드시 해제를 해야 하므로, 아예 이 과정을 unique_ptr 의 소멸자에서 처리하도록 했었습니다.
뮤텍스도 마찬가지로 사용 후 해제 패턴을 따르기 때문에 동일하게 소멸자에서 처리할 수 있습니다.
#include <iostream> #include <mutex> // mutex 를 사용하기 위해 필요 #include <thread> #include <vector> void worker(int& result, std::mutex& m) { for (int i = 0; i < 10000; i++) { // lock 생성 시에 m.lock() 을 실행한다고 보면 된다. std::lock_guard<std::mutex> lock(m); result += 1; // scope 를 빠져 나가면 lock 이 소멸되면서 // m 을 알아서 unlock 한다. } } int main() { int counter = 0; std::mutex m; // 우리의 mutex 객체 std::vector<std::thread> workers; for (int i = 0; i < 4; i++) { workers.push_back(std::thread(worker, std::ref(counter), std::ref(m))); } for (int i = 0; i < 4; i++) { workers[i].join(); } std::cout << "Counter 최종 값 : " << counter << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
Counter 최종 값 : 40000
와 같이 나옵니다.
std::lock_guard<std::mutex> lock(m);
lock_guard 객체는 뮤텍스를 인자로 받아서 생성하게 되는데, 이 때 생성자에서 뮤텍스를 lock 하게 됩니다. 그리고 lock_guard 가 소멸될 때 알아서 lock 했던 뮤텍스를 unlock 하게 됩니다.
따라서 사용자가 따로 unlock 을 신경쓰지 않아도 되서 매우 편리하죠.
그렇다면 lock_guard 만 있다면 이제 더이상 데드락 상황은 신경쓰지 않아도 되는 것일까요?
데드락 (deadlock)
아래와 같은 상황을 생각해봅시다.
#include <iostream> #include <mutex> // mutex 를 사용하기 위해 필요 #include <thread> void worker1(std::mutex& m1, std::mutex& m2) { for (int i = 0; i < 10000; i++) { std::lock_guard<std::mutex> lock1(m1); std::lock_guard<std::mutex> lock2(m2); // Do something } } void worker2(std::mutex& m1, std::mutex& m2) { for (int i = 0; i < 10000; i++) { std::lock_guard<std::mutex> lock2(m2); std::lock_guard<std::mutex> lock1(m1); // Do something } } int main() { int counter = 0; std::mutex m1, m2; // 우리의 mutex 객체 std::thread t1(worker1, std::ref(m1), std::ref(m2)); std::thread t2(worker2, std::ref(m1), std::ref(m2)); t1.join(); t2.join(); std::cout << "끝!" << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
(끝나지 않아서 강제 종료)
와 같이 나옵니다. 위와 같이 프로그램이 끝나지 않아서 강제로 종료해야만 합니다.
왜 이런 일이 발생하였을까요? worker1 과 worker2 에서 뮤텍스를 얻는 순서를 살펴봅시다.
worker1 에서는
std::lock_guard<std::mutex> lock1(m1); std::lock_guard<std::mutex> lock2(m2);
와 같이 m1 을 먼저 lock 한 후 m2 를 lock 하게 됩니다. 반면에 worker2 의 경우
std::lock_guard<std::mutex> lock2(m2); std::lock_guard<std::mutex> lock1(m1);
m2 를 먼저 lock 한 후 m1 을 lock 하게 됩니다.
그렇다면 다음과 같은 상황을 생각해보세요. 만약에 worker1 에서 m1 을 lock 하고, worker2 에서 m2 를 lock 했습니다. 그렇다면 worker1 에서 m2 를 lock 할 수 있을까요?
아닙니다. worker1 에서 m2 를 lock 하기 위해서는 worker2 에서 m2 를 unlock 해야 됩니다. 하지만 그러기 위해서는 worker2 에서 m1 을 lock 해야 합니다. 그런데 이 역시 불가능합니다. 왜냐하면 worker1 에 m1 을 lock 하고 있기 때문이지요!
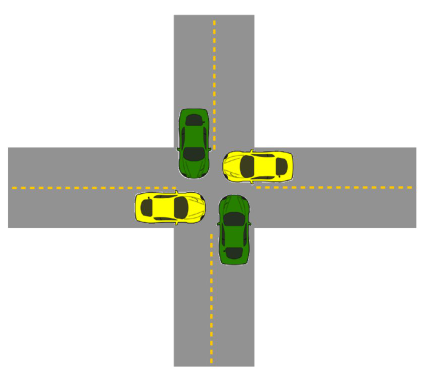
즉 worker1 과 worker2 모두 이러지도 저러지도 못하는 데드락 상황에 빠지게 됩니다. 분명히 뮤텍스를 lock 하면 반드시 unlock 한다라는 원칙을 지켰음에도 불구하고 데드락을 피할 수 없었습니다.
여기에 보면 데드락이 발생하는 조건이 잘 나타나 있습니다. 물론 만족해야 할 조건이 꽤나 많지만, 일어날 수 있는 일은 반드시 일어나고, 데드락 때문에 디버깅 하는 것 만큼 골때리는 것도 없습니다.
그렇다면 데드락이 가능한 상황을 어떻게 해결할 수 있을까요? 한 가지 방법으로는 한 쓰레드에게 우선권을 주는 것입니다. 위 자동차 그림으로 보자면 초록색 차가 노란색 차보다 항상 먼저 지나가도록 우선권을 주는 것이지요. 만약에 노란색 차가 교차로에 있는데 초록색 차가 들어온다면 초록색 차가 노란색 차에게 "야 차 빼~!" 라고 요구할 수 도 있지요.
물론 노란색 차는 억울하겠지만, 적어도 차들이 뒤엉켜서 아무도 전진하지 못하는 상황은 막을 수 있습니다. 쓰레드로 비유하자면, 한 쓰레드가 다른 쓰레드에 비해 우위를 갖게 된다면, 한 쓰레드만 열심히 일하고 다른 쓰레드는 일할 수 없는 기아 상태(starvation)가 발생할 수 있습니다.
위에서 말한 해결 방식을 코드로 옮기자면 아래와 같습니다.
#include <iostream> #include <mutex> // mutex 를 사용하기 위해 필요 #include <thread> void worker1(std::mutex& m1, std::mutex& m2) { for (int i = 0; i < 10; i++) { m1.lock(); m2.lock(); std::cout << "Worker1 Hi! " << i << std::endl; m2.unlock(); m1.unlock(); } } void worker2(std::mutex& m1, std::mutex& m2) { for (int i = 0; i < 10; i++) { while (true) { m2.lock(); // m1 이 이미 lock 되어 있다면 "야 차 빼" 를 수행하게 된다. if (!m1.try_lock()) { m2.unlock(); continue; } std::cout << "Worker2 Hi! " << i << std::endl; m1.unlock(); m2.unlock(); break; } } } int main() { std::mutex m1, m2; // 우리의 mutex 객체 std::thread t1(worker1, std::ref(m1), std::ref(m2)); std::thread t2(worker2, std::ref(m1), std::ref(m2)); t1.join(); t2.join(); std::cout << "끝!" << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
Worker1 Hi! 0 Worker1 Hi! 1 Worker1 Hi! 2 Worker1 Hi! 3 Worker1 Hi! 4 Worker1 Hi! 5 Worker1 Hi! 6 Worker1 Hi! 7 Worker1 Hi! 8 Worker1 Hi! 9 Worker2 Hi! 0 Worker2 Hi! 1 Worker2 Hi! 2 Worker2 Hi! 3 Worker2 Hi! 4 Worker2 Hi! 5 Worker2 Hi! 6 Worker2 Hi! 7 Worker2 Hi! 8 Worker2 Hi! 9 끝!
데드락 상황 없이 잘 실행됨을 알 수 있습니다. (물론 출력하는 개수가 적어서 그럴 수 도 있습니다. for 문에서 10 을 10000 정도로 바꿔보세요. 그럼에도 잘 실행됨을 알 수 있습니다.)
m1.lock(); m2.lock(); std::cout << "Worker1 Hi! " << i << std::endl; m2.unlock(); m1.unlock();
일단 worker1 은 lock_guard 를 통해 구현한 부분을 그대로 옮겨왔습니다. worker1 이 뮤텍스를 갖고 경쟁할 때 우선권을 가지므로 굳이 코드를 바꿀 필요가 없습니다. 차를 빼야 하는 것은 worker2 이니까요.
while (true) { m2.lock(); // m1 이 이미 lock 되어 있다면 "야 차 빼" 를 수행하게 된다. if (!m1.try_lock()) { m2.unlock(); continue; } std::cout << "Worker2 Hi! " << i << std::endl; m1.unlock(); m2.unlock(); break; }
worker2 의 경우 사뭇 다릅니다. 일단 m2 는 아무 문제 없이 lock 할 수 있습니다. 하지만 문제는 m1 을 lock 하는 과정 입니다.
만약에 worker1 이 m1 을 lock 하고 있다면 어떨까요? m1.lock 을 호출한 순간 서로 교차로 끼어서 이도저도 못하는 상황이 되는 것이겠지요.
C++ 에서는 try_lock 이라는 함수를 제공하는데, 이 함수는 만일 m1 을 lock 할 수 있다면 lock 을 하고 true 를 리턴합니다. 그런데 lock() 함수와는 다르게, lock 을 할 수 없다면 기다리지 않고 그냥 false 를 리턴합니다.
따라서 m1.try_lock() 이 true 를 리턴하였다면 worker2 가 m1 과 m2 를 성공적으로 lock 한 상황이므로 (교차로에 노란차만 있는 상황) 그대로 처리하면 됩니다.
반면에 m1.try_lock() 이 false 를 리턴하였다면 worker1 이 이미 m1 을 lock 했다는 의미 이지요. 이 경우 worker1 에서 우선권을 줘야 하기 때문에 자신이 이미 얻은 m2 역시 worker1 에게 제공해야 합니다. 쉽게 말해 교차로에서 노란차가 후진한다고 보시면 됩니다.
그 후에 while 을 통해 m1 과 m2 모두 lock 하는 것을 성공할 때 까지 계속 시도하게 되며, 성공하게 되면 while 을 빠져나가겠지요.
이와 같이 데드락을 해결하는 것은 매우 복잡합니다 (또한 완벽하지 않지요). 애초에 데드락 상황이 발생할 수 없게 프로그램을 잘 설계하는 것이 중요합니다.
C++ Concurrency In Action 이란 책에선 데드락 상황을 피하기 위해 다음과 같은 가이드라인을 제시하고 있습니다.
중첩된 Lock 을 사용하는 것을 피해라
모든 쓰레드들이 최대 1 개의 Lock 만을 소유한다면 (일반적인 경우에) 데드락 상황이 발생하는 것을 피할 수 있습니다. 또한 대부분의 디자인에서는 1 개의 Lock 으로도 충분합니다. 만일 여러개의 Lock 을 필요로 한다면 정말 필요로 하는지 를 되물어보는 것이 좋습니다.
Lock 을 소유하고 있을 때 유저 코드를 호출하는 것을 피해라
사실 이 가이드라인 역시 위에서 말한 내용과 자연스럽게 따라오는 것이긴 한데, 유저 코드에서 Lock 을 소유할 수 도 있기에 중첩된 Lock 을 얻는 것을 피하려면 Lock 소유시 유저 코드를 호출하는 것을 지양해야 합니다.
Lock 들을 언제나 정해진 순서로 획득해라
만일 여러개의 Lock 들을 획득해야 할 상황이 온다면, 반드시 이 Lock 들을 정해진 순서로 획득해야 합니다. 우리가 앞선 예제에서 데드락이 발생했던 이유 역시, worker1 에서는 m1, m2 순으로 lock 을 하였지만 worker2 에서는 m2, m1 순으로 lock 을 하였기 때문이지요. 만일 worker2 에서 역시 m1, m2 순으로 lock 을 하였다면 데드락은 발생하지 않았을 것입니다.
생산자(Producer) 와 소비자(Consumer) 패턴
다음으로 멀티 쓰레드 프로그램에서 가장 많이 등장하는 생산자(producer)-소비자(consumer) 패턴에 대해서 살펴보겠습니다.

생산자의 경우, 무언가 처리할 일을 받아오는 쓰레드를 의미합니다. 예를 들어서, 여러분이 인터넷에서 페이지를 긁어서 분석하는 프로그램을 만들었다고 생각해봅시다. 이 경우 페이지를 긁어 오는 쓰레드가 바로 생산자가 되겠지요.
소비자의 경우, 받은 일을 처리하는 쓰레드를 의미합니다. 앞선 예제의 경우 긁어온 페이지를 분석하는 쓰레드가 해당 역할을 하겠습니다.
그렇다면 이와 같은 상황을 쓰레드로 어떻게 구현할지 살펴보겠습니다.
#include <chrono> // std::chrono::miliseconds #include <iostream> #include <mutex> #include <queue> #include <string> #include <thread> #include <vector> void producer(std::queue<std::string>* downloaded_pages, std::mutex* m, int index) { for (int i = 0; i < 5; i++) { // 웹사이트를 다운로드 하는데 걸리는 시간이라 생각하면 된다. // 각 쓰레드 별로 다운로드 하는데 걸리는 시간이 다르다. std::this_thread::sleep_for(std::chrono::milliseconds(100 * index)); std::string content = "웹사이트 : " + std::to_string(i) + " from thread(" + std::to_string(index) + ")\n"; // data 는 쓰레드 사이에서 공유되므로 critical section 에 넣어야 한다. m->lock(); downloaded_pages->push(content); m->unlock(); } } void consumer(std::queue<std::string>* downloaded_pages, std::mutex* m, int* num_processed) { // 전체 처리하는 페이지 개수가 5 * 5 = 25 개. while (*num_processed < 25) { m->lock(); // 만일 현재 다운로드한 페이지가 없다면 다시 대기. if (downloaded_pages->empty()) { m->unlock(); // (Quiz) 여기서 unlock 을 안한다면 어떻게 될까요? // 10 밀리초 뒤에 다시 확인한다. std::this_thread::sleep_for(std::chrono::milliseconds(10)); continue; } // 맨 앞의 페이지를 읽고 대기 목록에서 제거한다. std::string content = downloaded_pages->front(); downloaded_pages->pop(); (*num_processed)++; m->unlock(); // content 를 처리한다. std::cout << content; std::this_thread::sleep_for(std::chrono::milliseconds(80)); } } int main() { // 현재 다운로드한 페이지들 리스트로, 아직 처리되지 않은 것들이다. std::queue<std::string> downloaded_pages; std::mutex m; std::vector<std::thread> producers; for (int i = 0; i < 5; i++) { producers.push_back(std::thread(producer, &downloaded_pages, &m, i + 1)); } int num_processed = 0; std::vector<std::thread> consumers; for (int i = 0; i < 3; i++) { consumers.push_back( std::thread(consumer, &downloaded_pages, &m, &num_processed)); } for (int i = 0; i < 5; i++) { producers[i].join(); } for (int i = 0; i < 3; i++) { consumers[i].join(); } }
성공적으로 컴파일 하였다면
실행 결과
웹사이트 : 0 from thread(1) 웹사이트 : 0 from thread(2) 웹사이트 : 1 from thread(1) 웹사이트 : 0 from thread(3) 웹사이트 : 2 from thread(1) 웹사이트 : 0 from thread(4) 웹사이트 : 1 from thread(2) 웹사이트 : 3 from thread(1) 웹사이트 : 0 from thread(5) 웹사이트 : 4 from thread(1) 웹사이트 : 1 from thread(3) 웹사이트 : 2 from thread(2) 웹사이트 : 1 from thread(4) 웹사이트 : 3 from thread(2) 웹사이트 : 2 from thread(3) 웹사이트 : 1 from thread(5) 웹사이트 : 4 from thread(2) 웹사이트 : 2 from thread(4) 웹사이트 : 3 from thread(3) 웹사이트 : 2 from thread(5) 웹사이트 : 4 from thread(3) 웹사이트 : 3 from thread(4) 웹사이트 : 3 from thread(5) 웹사이트 : 4 from thread(4) 웹사이트 : 4 from thread(5)
와 같이 나옵니다. 일단 위 코드가 어떻게 생산자-소비자 패턴을 구현하였는지 살펴봅시다.
std::queue<std::string> downloaded_pages;
먼저 producer 쓰레드에서는 웹사이트에서 페이지를 계속 다운로드 하는 역할을 하게 됩니다. 이 때, 다운로드한 페이지들을 downloaded_pages 라는 큐에 저장하게 됩니다.
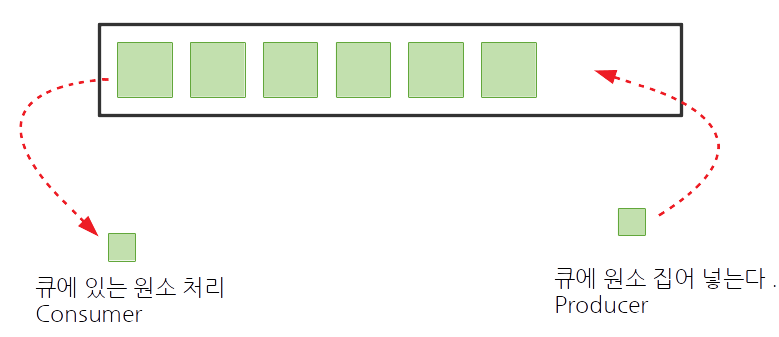
왜 굳이 큐를 사용하였나면 큐가 바로 먼저 들어온 것이 먼저 나간다(First In First Out - FIFO) 라는 특성이 있기 때문입니다. 쉽게 말해, 먼저 다운로드한 페이지를 먼저 처리하기 위함이지요.
물론 vector 로 구현해도 상관은 없습니다. 하지만 vector 를 사용하였을 경우, 가장 먼저 도착한 페이지가 벡터 첫번째 원소로 있을터인데, 이를 제거하는 작업이 꽤나 느리기 때문에 권장하지 않습니다. (맨 앞의 원소를 제거하면, 나머지 모든 원소들을 앞으로 한 칸 씩 땡겨줘야 하지요)
하지만 큐의 경우 해당 연산들이 매우 빠르게 이루어질 수 있습니다.
producer 를 살펴보면 아래와 같습니다.
// 웹사이트를 다운로드 하는데 걸리는 시간이라 생각하면 된다. // 각 쓰레드 별로 다운로드 하는데 걸리는 시간이 다르다. std::this_thread::sleep_for(std::chrono::milliseconds(100 * index)); std::string content = "웹사이트 : " + std::to_string(i) + " from thread(" + std::to_string(index) + ")\n"; // downloaded_pages 는 쓰레드 사이에서 공유되므로 critical section 에 넣어야 // 한다. m->lock(); downloaded_pages->push(content); m->unlock();
일단 기본적으로 C++ 표준 라이브러리 상에서는 인터넷 페이지를 다운받는 기능을 제공하지 않기 때문에, 대략 비슷한 상황을 가정하고 시뮬레이션 하였습니다.
std::this_thread::sleep_for 함수는 인자로 전달된 시간 만큼 쓰레드를 sleep 시키는데, 이 때 해당 인자로 chrono 의 시간 객체를 받게 됩니다. chrono 는 C++ 11 에 새로 추가된 시간 관련 라이브러리로 기존의 C 의 time.h 보다 훨씬 편리한 기능을 제공하고 있습니다. 이에 대해서는 나중 강좌에서 자세히 다루어 보도록 하고, 일단 100 * index 밀리초 만큼 쓰레드를 재우기 위해서는
std::chrono::milliseconds(100 * index) 와 같이 전달하면 됩니다.
그리고 다운 받은 웹사이트 내용이 content 라고 생각해봅시다.
그렇다면, 이제 다운 받은 페이지를 작업 큐에 집어 넣어야 합니다. 이 때 주의할 점으로, producer 쓰레드가 1 개가 아니라 5 개나 있다는 점입니다. 따라서 downloaded_pages 에 접근하는 쓰레드들 사이에 race condition 이 발생할 수 있습니다.
이를 방지 하기 위해서 뮤텍스 m 으로 해당 코드를 감싸서 문제가 발생하지 않게 해줍니다.
자 그럼 consumer 의 경우 어떤 식으로 구현할 지 생각해봅시다.
먼저 consumer 쓰레드의 입장에서는 언제 일이 올지 알 수 없습니다. 따라서 downloaded_pages 가 비어있지 않을 때 까지 계속 while 루프를 돌아야겠지요. 한 가지 문제는 컴퓨터 CPU 의 속도에 비해 웹사이트 정보가 큐에 추가되는 속도는 매우 느리다는 점입니다.
우리의 producer 의 경우 대충 100ms 마다 웹사이트 정보를 큐에 추가하게 되는데, 이 시간 동안 downloaded_pages->empty() 이 문장을 수십 만 번 호출할 수 있을 것입니다. 이는 상당한 CPU 자원의 낭비가 아닐 수 없지요.
따라서, 실제로는 아래와 같이 구현하였습니다.
m->lock(); // 만일 현재 다운로드한 페이지가 없다면 다시 대기. if (downloaded_pages->empty()) { m->unlock(); // (Quiz) 여기서 unlock 을 안한다면 어떻게 될까요? // 10 밀리초 뒤에 다시 확인한다. std::this_thread::sleep_for(std::chrono::milliseconds(10)); continue; }
downloaded_pages->empty() 라면, 강제로 쓰레드를 sleep 시켜서 10 밀리초 뒤에 다시 확인하는 식으로 말이지요.
참고로 m->unlock 을 위 if 문 안에서 호출하지 않는다면 데드락이 발생하게 됩니다. (왜 인지는 생각해보세요!)
// 맨 앞의 페이지를 읽고 대기 목록에서 제거한다. std::string content = downloaded_pages->front(); downloaded_pages->pop(); (*num_processed)++; m->unlock(); // content 를 처리한다. std::cout << content; std::this_thread::sleep_for(std::chrono::milliseconds(80));
마지막으로 content 를 처리하는 과정은 간단합니다. front 를 통해서 맨 앞의 원소를 얻은 뒤에, pop 을 호출하면 맨 앞의 원소를 큐에서 제거하게 됩니다.
이 때 m->unlock 을 함으로써 다른 쓰레드에서도 다음 원소를 바로 처리할 수 있도록 해야되죠. content 를 처리하는 시간은 대충 80 밀리초가 소모된다고 시뮬레이션 하였습니다.
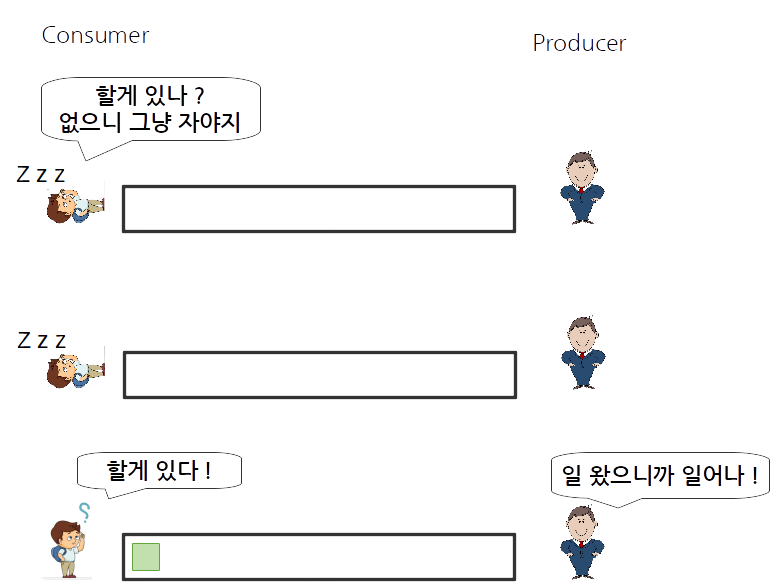
우리의 producer 와 consumer 들 관계를 그림으로 보자면 아래와 같습니다.

위 그림 처럼 우리의 구현에서 consumer 쓰레드가 10 밀리초 마다 downloaded_pages 에 할일이 있는지 확인하고 없으면 다시 기다리는 형태를 취하고 있습니다.
이는 매우 비효율적입니다. 매 번 언제 올지 모르는 데이터를 확인하기 위해 지속적으로 mutex 를 lock 하고, 큐를 확인해야 하기 때문이지요.
차라리 producer 에서 데이터가 뜸하게 오는 것을 안다면 그냥 consumer 는 아예 재워놓고, producer 에서 데이터가 온다면 consumer 를 깨우는 방식이 낫지 않을까요? 쓰레드를 재워놓게 되면, 그 사이에 다른 쓰레드들이 일을 할 수 있기 때문에 CPU 를 더 효율적으로 쓸 수 있을 것입니다.
C++ 에서는 위와 같은 형태로 생산자 소비자 패턴을 구현할 수 있도록 여러가지 도구들을 제공하고 있습니다.
condition_variable
위와 같은 상황에서 쓰레드들을 10 밀리초 마다 재웠다 깨웠다 할 수 밖에 없었던 이유는 어떠 어떠한 조건을 만족할 때 까지 자라! 라는 명령을 내릴 수 없었기 때문입니다.
위 경우 downloaded_pages 가 empty() 가 참이 아닐 때 까지 자라 라는 명령을 내리고 싶었겠지요.
이는 조건 변수(condition_variable) 를 통해 해결할 수 있습니다.
#include <chrono> // std::chrono::miliseconds #include <condition_variable> // std::condition_variable #include <iostream> #include <mutex> #include <queue> #include <string> #include <thread> #include <vector> void producer(std::queue<std::string>* downloaded_pages, std::mutex* m, int index, std::condition_variable* cv) { for (int i = 0; i < 5; i++) { // 웹사이트를 다운로드 하는데 걸리는 시간이라 생각하면 된다. // 각 쓰레드 별로 다운로드 하는데 걸리는 시간이 다르다. std::this_thread::sleep_for(std::chrono::milliseconds(100 * index)); std::string content = "웹사이트 : " + std::to_string(i) + " from thread(" + std::to_string(index) + ")\n"; // data 는 쓰레드 사이에서 공유되므로 critical section 에 넣어야 한다. m->lock(); downloaded_pages->push(content); m->unlock(); // consumer 에게 content 가 준비되었음을 알린다. cv->notify_one(); } } void consumer(std::queue<std::string>* downloaded_pages, std::mutex* m, int* num_processed, std::condition_variable* cv) { while (*num_processed < 25) { std::unique_lock<std::mutex> lk(*m); cv->wait( lk, [&] { return !downloaded_pages->empty() || *num_processed == 25; }); if (*num_processed == 25) { lk.unlock(); return; } // 맨 앞의 페이지를 읽고 대기 목록에서 제거한다. std::string content = downloaded_pages->front(); downloaded_pages->pop(); (*num_processed)++; lk.unlock(); // content 를 처리한다. std::cout << content; std::this_thread::sleep_for(std::chrono::milliseconds(80)); } } int main() { // 현재 다운로드한 페이지들 리스트로, 아직 처리되지 않은 것들이다. std::queue<std::string> downloaded_pages; std::mutex m; std::condition_variable cv; std::vector<std::thread> producers; for (int i = 0; i < 5; i++) { producers.push_back( std::thread(producer, &downloaded_pages, &m, i + 1, &cv)); } int num_processed = 0; std::vector<std::thread> consumers; for (int i = 0; i < 3; i++) { consumers.push_back( std::thread(consumer, &downloaded_pages, &m, &num_processed, &cv)); } for (int i = 0; i < 5; i++) { producers[i].join(); } // 나머지 자고 있는 쓰레드들을 모두 깨운다. cv.notify_all(); for (int i = 0; i < 3; i++) { consumers[i].join(); } }
성공적으로 컴파일 하였다면
실행 결과
웹사이트 : 0 from thread(1) 웹사이트 : 0 from thread(2) 웹사이트 : 1 from thread(1) 웹사이트 : 0 from thread(3) 웹사이트 : 2 from thread(1) 웹사이트 : 1 from thread(2) 웹사이트 : 0 from thread(4) 웹사이트 : 3 from thread(1) 웹사이트 : 0 from thread(5) 웹사이트 : 4 from thread(1) 웹사이트 : 1 from thread(3) 웹사이트 : 2 from thread(2) 웹사이트 : 1 from thread(4) 웹사이트 : 3 from thread(2) 웹사이트 : 2 from thread(3) 웹사이트 : 1 from thread(5) 웹사이트 : 4 from thread(2) 웹사이트 : 2 from thread(4) 웹사이트 : 3 from thread(3) 웹사이트 : 2 from thread(5) 웹사이트 : 4 from thread(3) 웹사이트 : 3 from thread(4) 웹사이트 : 3 from thread(5) 웹사이트 : 4 from thread(4) 웹사이트 : 4 from thread(5)
와 같이 나옵니다.
condition_variable cv;
먼저 뮤텍스를 정의할 때와 같이 condition_variable 을 정의하였습니다. 이 condition_variable 이 어떻게 사용되는지 consumer 쓰레드 부터 살펴봅시다.
std::unique_lock<std::mutex> lk(*m); cv->wait(lk, [&] { return !downloaded_pages->empty() || *num_processed == 25; });
대충 코드를 보면 느낌이 오겠지만, condition_variable 의 wait 함수에 어떤 조건이 참이 될 때 까지 기다릴지 해당 조건을 인자로 전달해야 합니다. 우리의 경우 조건으로
!downloaded_pages->empty() || *num_processed == 25;
를 전달하였는데, 이는 downloaded_pages 에 원소들이 있거나, 전체 처리된 페이지의 개수가 25개 일 때 wait 을 중지하도록 하였습니다.
조건 변수는 만일 해당 조건이 거짓이라면, lk 를 unlock 한 뒤에, 영원히 sleep 하게 됩니다. 이 때 이 쓰레드는 다른 누가 깨워주기 전까지 계속 sleep 된 상태로 기다리게 됩니다. 한 가지 중요한 점이라면 lk 를 unlock 한다는 점입니다.
반면에 해당 조건이 참이라면 cv.wait 는 그대로 리턴해서 consumer 의 content 를 처리하는 부분이 그대로 실행되게 됩니다.
std::unique_lock<std::mutex> lk(*m);
참고로 기존의 lock_guard 와는 다르게 unique_lock 을 정의하였는데, 사실 unique_lock 은 lock_guard 와 거의 동일합니다. 다만, lock_guard 의 경우 생성자 말고는 따로 lock 을 할 수 없는데, unique_lock 은 unlock 후에 다시 lock 할 수 있습니다.
덧붙여 unique_lock 을 사용한 이유는 cv->wait 가 unique_lock 을 인자로 받기 때문입니다.
if (*num_processed == 25) { lk.unlock(); return; }
cv.wait 후에 아래 num_processed 가 25 인지 확인하는 구문이 추가되었는데, 이는 wait 에서 탈출한 이유가 모든 페이지 처리를 완료해서 인지, 아니면 정말 downloaded_pages 에 페이지가 추가됬는지 알 수 없기 때문입니다. 만일 모든 페이지 처리가 끝나서 탈출한 것였다면, 그냥 쓰레드를 종료해야 합니다.
자 그렇다면 producer 를 확인해보겠습니다.
// consumer 에게 content 가 준비되었음을 알린다. cv->notify_one();
만약에 페이지를 하나 다운 받았다면, 잠자고 있는 쓰레드들 중 하나를 깨워서 일을 시켜야겠죠? (만약에 모든 쓰레드들이 일을 하고 있는 상태라면 아무 일도 일어나지 않습니다.) notify_one 함수는 말 그대로,조건이 거짓인 바람에 자고 있는 쓰레드 중 하나를 깨워서 조건을 다시 검사하게 해줍니다. 만일 조건이 참이 된다면 그 쓰레드가 다시 일을 시작하겠지요.
for (int i = 0; i < 5; i++) { producers[i].join(); } // 나머지 자고 있는 쓰레드들을 모두 깨운다. cv.notify_all();
producer 들이 모두 일을 끝낸 시점을 생각해본다면, 자고 있는 일부 consumer 쓰레드들이 있을 것입니다. 만약에 cv.notify_all() 을 하지 않는다면, 자고 있는 consumer 쓰레드들의 경우 join 되지 않는 문제가 발생합니다.
따라서 마지막으로 cv.notify_all() 을 통해서 모든 쓰레드를 깨워서 조건을 검사하도록 합니다. 해당 시점에선 이미 num_processed 가 25 가 되어 있을 것이므로, 모든 쓰레드들이 잠에서 깨어나 종료하게 됩니다.
자 그럼 이것으로 이번 강좌를 마치도록 하겠습니다. 다음 강좌에서는 C++ 에서 제공하는 또 다른 기능인 atomic 객체에 대해 다루어 볼 것입니다.
뭘 배웠지?
여러 쓰레드에서 같은 객체의 값을 수정한다면 Race Condition 이 발생합니다. 이를 해결하기 위해서는 여러가지 방법이 있지만, 한 가지 방법으로 뮤텍스를 사용하는 방법이 있습니다.
뮤텍스는 한 번에 한 쓰레드에서만 획득할 수 있습니다. 획득한 뮤텍스는 반드시 반환해야 합니다.
lock_guard 나 unique_lock 등을 이용하면 뮤텍스의 획득-반환을 손쉽게 처리할 수 있습니다.
뮤텍스를 사용할 때 데드락이 발생하지 않도록 주의해야 합니다. 데드락을 디버깅하는 것은 매우 어렵습니다.
condition_variable 을 사용하면 생산자-소비자 패턴을 쉽게 구현할 수 있습니다.
생각 해보기
문제 1
condition_variable 에서 wait 말고도 wait_for 과 wait_until 이라는 다른 유용한 함수들이 있습니다. 여기서 읽어보세요!

댓글을 불러오는 중입니다..