모두의 코드
씹어먹는 C++ - <15 - 4. C++ future, promise, packaged_task, async>
이번 강좌에서는
동기와 비동기적 실행에 대한 이해
std::promise,std::future,std::packaged_task이해std::async사용법
에 대해 다룹니다.

안녕하세요 여러분! 앞선 강좌를 통해서 C++ 에서 어떻게 쓰레드를 생성하고, 뮤텍스를 통해서 공유된 자원에서 경쟁 상태 (race condition) 을 방지하고, 조건 변수 (condition_variable) 을 통해서 생산자 - 소비자 패턴을 어떻게 구현하는지 알아보았습니다.
뿐만 아니라 atomic 객체를 통해 쉽게 원자적 연산을 수행하는 방법을 배웠고, 더 나아가서 memory_order 을 통해 컴파일러가 어떤 식으로 명령어를 재배치 할지 설정하는 방법도 다루었습니다.
이번 강좌에서는 멀티 쓰레딩의 강력함을 더 쉽게 활용할 수 있게 해주는 몇 가지 도구들을 살펴보도록 하겠습니다.
동기 (synchronous) 와 비동기 (asynchronous) 실행
자바스크립트로 프로그램을 한 번 이라도 짜신 분들은 비동기 (asynchronous) 작업이라는 단어를 수 없이 들어봤을 것입니다. 하지만 C++ 만 배우신 분들은 아직 많이 생소할 텐데 간단히 설명하면 다음과 같습니다.
예를 들어서 여러분이 하드 디스크에서 파일을 읽는다고 생각해봅시다. SSD 가 아니라, 하드 디스크를 사용한다면, 임의의 위치에 쓰여져 있는 파일을 읽는데 시간이 상당해 오래 걸립니다.

왜냐하면 하드 디스크의 경우 헤드 라고 부르는 장치가 디스크에 파일이 쓰여져 있는 실제 위치 까지 가야 하기 때문이죠. 이는 하드 디스크에 있는 모터가 디스크를 돌려서 헤드를 정해진 구역에 위치 시킵니다.
보통 사용하는 7200rpm 하드 디스크의 경우 (여기서 rpm 은 모터가 돌아가는 속도를 말합니다), 평균 4.17 밀리초가 걸린다고 합니다. 램에서 데이터를 읽어내는데 50 나노초가 걸리는 것에 비해 대략 8만배 정도 느린 셈입니다.
따라서 아래와 같은 코드를 생각해보면
string txt = read("a.txt"); // 5ms string result = do_something_with_txt(txt); // 5ms do_other_computation(); // 5ms 걸림 (CPU 로 연산을 수행함)
만일 순차적으로 실행한다고 했을 때, 위 작업들이 모두 종료되는데 총 5 + 5 + 5 = 15 밀리초가 걸리게 됩니다.
이러한 작업이 비효율적인 이유는 read 함수가 파일이 하드 디스크에서 읽어지는 동안 기다리기 때문입니다. 다시 말해 read 함수는 파일 읽기가 끝나기 전 까지 리턴하지 않고, CPU 는 아무것도 하지 않은 채 가만히 기다리게 됩니다.
이렇게, 한 번에 하나씩 순차적으로 실행 되는 작업을 동기적 (synchronous) 으로 실행 된다고 부릅니다. 동기적인 작업들은 한 작업이 끝날 때 까지 다음 작업으로 이동하지 않기 때문이지요.
만일 read 함수가 CPU 를 계속 사용한다면, 동기적으로 작업을 수행해도 문제될 것이 없습니다. 하지만 실제로는 read 함수가 하드 디스크에서 데이터를 읽어오는 동안 CPU 는 아무런 작업도 하지 않기 때문에, 그 시간에 오히려 CPU 를 놀리지 않고 do_other_computation 과 같은 작업을 수행하는 것이 더 바람직합니다.
그렇다면 이를 C++ 에서는 어떻게 구현할 수 있을까요? 아마 쓰레드를 배우신 여러분들은 아래와 같이 코드를 짤 수 있을 것입니다.
void file_read(string* result) { string txt = read("a.txt"); // (1) *result = do_something_with_txt(txt); } int main() { string result; thread t(file_read, &result); do_other_computation(); // (2) t.join(); }
위 코드의 수행 시간은 어떻게 될까요? 예를 들어서 쓰레드 t 를 생성한 뒤에 바로 새로운 쓰레드에서 file_read 함수를 실행한다고 해봅시다.
file_read 함수 안에서 read("a.txt") 가 실행이 되는데, 이 때 CPU 는 하드 디스크에서 데이터를 기다리지 않고, 바로 다시 원래 main 함수 쓰레드로 넘어와서 do_other_computation() 을 수행하게 되겠지요.
5 밀리초 후에 do_other_computation() 이 끝나게 된다면, t.join 을 수행하면서 다시 file_read 쓰레드를 실행할 텐데, 이미 하드 디스크에서 a.txt 파일의 내용이 도착해있을 것이므로, do_something_with_txt 를 바로 실행하게 됩니다. 이 경우, 총 5 + 5 = 10 밀리초 만에 수행이 끝나게 됩니다. CPU 는 단 한 순간도 놀지 않았습니다.
이와 같이 프로그램의 실행이, 한 갈래가 아니라 여러 갈래로 갈라져서 동시에 진행되는 것을 비동기적(asynchronous) 실행 이라고 부릅니다. 자바스크립트와 같은 언어들은 언어 차원에서 비동기적 실행을 지원하지만, C++ 의 경우 위와 같이 명시적으로 쓰레드를 생성해서 적절히 수행해야 했었습니다.
하지만 C++ 11 표준 라이브러리를 통해 매우 간단히 비동기적 실행을 할 수 있게 해주는 도구를 제공하고 있습니다.
std::promise 와 std::future
결국 비동기적 실행으로 하고 싶은 일은, 어떠한 데이터를 다른 쓰레드를 통해 처리해서 받아내는 것입니다.
내가 어떤 쓰레드 T 를 사용해서, 비동기적으로 값을 받아내겠다 라는 의미는, 미래에 (future) 쓰레드 T 가 원하는 데이터를 돌려 주겠다 라는 약속 (promise) 라고 볼 수 있습니다.
이 문장을 그대로 코드로 옮겨보면 아래와 같습니다.
#include <future> #include <iostream> #include <string> #include <thread> using std::string; void worker(std::promise<string>* p) { // 약속을 이행하는 모습. 해당 결과는 future 에 들어간다. p->set_value("some data"); } int main() { std::promise<string> p; // 미래에 string 데이터를 돌려 주겠다는 약속. std::future<string> data = p.get_future(); std::thread t(worker, &p); // 미래에 약속된 데이터를 받을 때 까지 기다린다. data.wait(); // wait 이 리턴했다는 뜻이 future 에 데이터가 준비되었다는 의미. // 참고로 wait 없이 그냥 get 해도 wait 한 것과 같다. std::cout << "받은 데이터 : " << data.get() << std::endl; t.join(); }
성공적으로 컴파일 하였다면
실행 결과
받은 데이터 : some data
와 같이 나옵니다.
std::promise<string> p;
먼저 promise 객체를 살펴봅시다. promise 객체를 정의할 때, 연산을 수행 후에 돌려줄 객체의 타입을 템플릿 인자로 받습니다. 우리의 경우 string 객체를 돌려줄 예정이므로 string 을 전달하였습니다.
연산이 끝난 다음에 promise 객체는 자신이 가지고 있는 future 객체에 값을 넣어주게 됩니다. 이 때 promise 객체에 대응되는 future 객체는
std::future<string> data = p.get_future();
위와 같이 get_future 함수를 통해서 얻을 수 있습니다. 하지만 data 가 아직은 실제 연산 결과를 포함하고 있는 것은 아닙니다. data 가 실제 결과를 포함하기 위해서는
p->set_value("some data");
위와 같이 promise 객체가 자신의 future 객체에 데이터를 제공한 후에;
// 미래에 약속된 데이터를 받을 때 까지 기다린다. data.wait(); // wait 이 리턴했다는 뜻이 future 에 데이터가 준비되었다는 의미. // 참고로 wait 없이 그냥 get 해도 wait 한 것과 같다. std::cout << "받은 데이터 : " << data.get() << std::endl;
대응되는 future 객체의 get 함수를 통해 얻어낼 수 있습니다. 한 가지 중요한 점은 promise 가 future 에 값을 전달하기 전 까지 wait 함수가 기다린다는 점입니다. wait 함수가 리턴을 하였다면 get 을 통해서 future 에 전달된 객체를 얻을 수 있습니다.
참고로 굳이 wait 함수를 따로 호출할 필요는 없는데, get 함수를 바로 호출하더라도 알아서 promise 가 future 에 객체를 전달할 때 까지 기다린다음에 리턴합니다. 참고로 get 을 호출하면 future 내에 있던 데이터가 이동 됩니다. 따라서 get 을 다시 호출하면 안됩니다.
주의 사항
future 에서 get 을 호출하면, 설정된 객체가 이동 됩니다. 따라서 절대로 get 을 두 번 호출하면 안됩니다.
정리해 보자면 promise 는 생산자-소비자 패턴에서 마치 생산자 (producer) 의 역할을 수행하고, future 는 소비자 (consumer) 의 역할을 수행한다고 보면 됩니다.
따라서 아래와 같이 조건 변수를 통해서도 promise - future 패턴을 구현할 수 있습니다.
#include <condition_variable> #include <iostream> #include <mutex> #include <string> #include <thread> std::condition_variable cv; std::mutex m; bool done = false; std::string info; void worker() { { std::lock_guard<std::mutex> lk(m); info = "some data"; // 위의 p->set_value("some data") 에 대응 done = true; } cv.notify_all(); } int main() { std::thread t(worker); std::unique_lock<std::mutex> lk(m); cv.wait(lk, [] { return done; }); // 위의 data.wait() 이라 보면 된다. lk.unlock(); std::cout << "받은 데이터 : " << info << std::endl; t.join(); }
하지만, promise 와 future 를 이용하는 것이 훨씬 더 깔끔하고 더 이해하기도 쉽습니다. 또한 위 조건 변수를 사용한 것 보다 더 우수한 점은 future 에 예외도 전달할 수 있기 때문입니다. 예를 들어서 아래와 같은 코드를 살펴봅시다.
#include <exception> #include <future> #include <iostream> #include <string> #include <thread> using std::string; void worker(std::promise<string>* p) { try { throw std::runtime_error("Some Error!"); } catch (...) { // set_exception 에는 exception_ptr 를 전달해야 한다. p->set_exception(std::current_exception()); } } int main() { std::promise<string> p; // 미래에 string 데이터를 돌려 주겠다는 약속. std::future<string> data = p.get_future(); std::thread t(worker, &p); // 미래에 약속된 데이터를 받을 때 까지 기다린다. data.wait(); try { data.get(); } catch (const std::exception& e) { std::cout << "예외 : " << e.what() << std::endl; } t.join(); }
성공적으로 컴파일 하였다면
실행 결과
예외 : Some Error!
위와 같이 예외가 제대로 전달되었음을 알 수 있습니다.
p->set_exception(current_exception());
참고로 set_exception 에는 예외 객체가 아니라 exception_ptr 을 전달해야 합니다. 이 exception_ptr 는 catch 로 받은 예외 객체의 포인터가 아니라, 현재 catch 된 예외에 관한 정보를 반환하는 current_exception 함수가 리턴하는 객체 입니다.
물론, catch 로 전달받은 예외 객체를 make_exception_ptr 함수를 사용해서 exception_ptr 로 만들 수 도 있지만, 그냥 편하게 current_exception 을 호출하는 것이 더 간단합니다.
이렇게 future 에 전달된 예외 객체는
try { data.get(); } catch (const std::exception& e) { std::cout << "예외 : " << e.what() << std::endl; }
위와 같이 get 함수를 호출하였을 때, 실제로 future 에 전달된 예외 객체가 던져지고, 마치 try 와 catch 문을 사용한 것처럼 예외를 처리할 수 있게 됩니다. 매우 간단하지요.
wait_for
그냥 wait 을 하였다면 promise 가 future 에 전달할 때 까지 기다리게 됩니다. 하지만 wait_for 을 사용하면, 정해진 시간 동안만 기다리고 그냥 진행할 수 있습니다.
#include <chrono> #include <exception> #include <future> #include <iostream> #include <string> #include <thread> void worker(std::promise<void>* p) { std::this_thread::sleep_for(std::chrono::seconds(10)); p->set_value(); } int main() { // void 의 경우 어떠한 객체도 전달하지 않지만, future 가 set 이 되었냐 // 안되었느냐의 유무로 마치 플래그의 역할을 수행할 수 있습니다. std::promise<void> p; // 미래에 string 데이터를 돌려 주겠다는 약속. std::future<void> data = p.get_future(); std::thread t(worker, &p); // 미래에 약속된 데이터를 받을 때 까지 기다린다. while (true) { std::future_status status = data.wait_for(std::chrono::seconds(1)); // 아직 준비가 안됨 if (status == std::future_status::timeout) { std::cerr << ">"; } // promise 가 future 를 설정함. else if (status == std::future_status::ready) { break; } } t.join(); }
성공적으로 컴파일 하였다면

와 같이 나옵니다.
std::future_status status = data.wait_for(std::chrono::seconds(1)); // 아직 준비가 안됨 if (status == std::future_status::timeout) { cerr << ">"; } // promise 가 future 를 설정함. else if (status == std::future_status::ready) { break; }
wait_for 함수는 promise 가 설정될 때 까지 기다리는 대신에 wait_for 에 전달된 시간 만큼 기다렸다가 바로 리턴해버립니다. 이 때 리턴하는 값은 현재 future 의 상태를 나타내는 future_status 객체 입니다.
future_status 는 총 3 가지 상태를 가질 수 있습니다. 먼저 future 에 값이 설정 됬을 때 나타나는 future_status::ready 가 있고, wait_for 에 지정한 시간이 지났지만 값이 설정되지 않아서 리턴한 경우에는 future_status::timeout 이 리턴됩니다.
마지막으로 future_status::deferred 가 있는데 이는 결과값을 계산하는 함수가 채 실행되지 않았다는 의미인데, 뒤에서 좀더 자세히 다루도록 하겠습니다.
shared_future
앞서 future 의 경우 딱 한 번만 get 을 할 수 있다고 하였습니다. 왜냐하면 get 을 호출하면 future 내부의 객체가 이동되기 때문이지요. 하지만, 종종 여러 개의 다른 쓰레드에서 future 를 get 할 필요성이 있습니다.
이 경우 shared_future 를 사용하면 됩니다. 아래 예제는 달리기를 하는 것을 C++ 프로그램으로 나타내본 것입니다. main 함수에서 출발 신호를 보내면 각 runner 쓰레드들에서 달리기를 시작하게 됩니다.
#include <chrono> #include <future> #include <iostream> #include <thread> using std::thread; void runner(std::shared_future<void> start) { start.get(); std::cout << "출발!" << std::endl; } int main() { std::promise<void> p; std::shared_future<void> start = p.get_future(); thread t1(runner, start); thread t2(runner, start); thread t3(runner, start); thread t4(runner, start); // 참고로 cerr 는 std::cout 과는 다르게 버퍼를 사용하지 않기 때문에 터미널에 // 바로 출력된다. std::cerr << "준비..."; std::this_thread::sleep_for(std::chrono::seconds(1)); std::cerr << "땅!" << std::endl; p.set_value(); t1.join(); t2.join(); t3.join(); t4.join(); }
성공적으로 컴파일 하였다면

와 같이 잘 나옵니다. 위 코드 역시 condition_variable 을 이용해서 동일하게 작성할 수 있습니다. 하지만 보시다시피, future 를 사용하는 것이 훨씬 편리합니다. 참고로 shared_future 의 경우 future 와는 다르게 복사가 가능하고, 복사본들이 모두 같은 객체를 공유하게 됩니다. 따라서 레퍼런스나 포인터로 전달할 필요가 없습니다.
packaged_task
C++ 에서는 위 promise-future 패턴을 비동기적 함수(정확히는 Callable - 즉 람다 함수, Functor 포함) 의 리턴값에 간단히 적용할 수 있는 packaged_task 라는 것을 지원합니다.
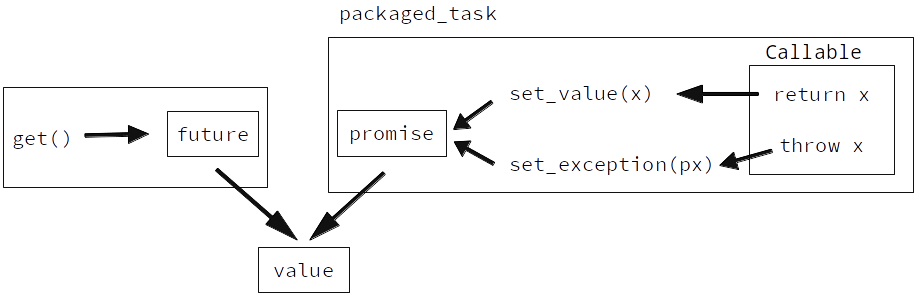
packaged_task 에 전달된 함수가 리턴할 때, 그 리턴값을 promise 에 set_value 하고, 만약에 예외를 던졌다면 promise 에 set_exception 을 합니다. 해당 future 는 packaged_task 가 리턴하는 future 에서 접근할 수 있습니다. 아래 예제를 한편 살펴봅시다.
#include <future> #include <iostream> #include <thread> int some_task(int x) { return 10 + x; } int main() { // int(int) : int 를 리턴하고 인자로 int 를 받는 함수. (std::function 참조) std::packaged_task<int(int)> task(some_task); std::future<int> start = task.get_future(); std::thread t(std::move(task), 5); std::cout << "결과값 : " << start.get() << std::endl; t.join(); }
성공적으로 컴파일 하였다면
실행 결과
결과값 : 15
와 같이 잘 나옵니다.
std::packaged_task<int(int)> task(some_task); std::future<int> start = task.get_future();
packaged_task 는 비동기적으로 수행할 함수 자체를 생성자의 인자로 받습니다. 또한 템플릿 인자로 해당 함수의 타입을 명시해야 합니다. packaged_task 는 전달된 함수를 실행해서, 그 함수의 리턴값을 promise 에 설정합니다.
해당 promise 에 대응되는 future 는 위와 같이 get_future 함수로 얻을 수 있습니다.
thread t(std::move(task), 5);
생성된 packaged_task 를 쓰레드에 전달하면 됩니다. 참고로 packaged_task 는 복사 생성이 불가능하므로 (promise 도 마찬가지 입니다.) 명시적으로 move 해줘야만 합니다.
std::cout << "결과값 : " << start.get() << std::endl;
비동기적으로 실행된 함수의 결과값은 추후에 future 의 get 함수로 받을 수 있게 됩니다. 이와 같이 packaged_task 를 사용하게 된다면 쓰레드에 굳이 promise 를 전달하지 않아도 알아서 packaged_task 가 함수의 리턴값을 처리해줘서 매우 편리합니다.
std::async
앞서 promise 나 packaged_task 는 비동기적으로 실행을 하기 위해서는, 쓰레드를 명시적으로 생성해서 실행해야만 했습니다. 하지만 std::async 에 어떤 함수를 전달한다면, 아예 쓰레드를 알아서 만들어서 해당 함수를 비동기적으로 실행하고, 그 결과값을 future 에 전달합니다.
#include <future> #include <iostream> #include <thread> #include <vector> // std::accumulate 와 동일 int sum(const std::vector<int>& v, int start, int end) { int total = 0; for (int i = start; i < end; ++i) { total += v[i]; } return total; } int parallel_sum(const std::vector<int>& v) { // lower_half_future 는 1 ~ 500 까지 비동기적으로 더함 // 참고로 람다 함수를 사용하면 좀 더 깔끔하게 표현할 수 도 있다. // --> std::async([&v]() { return sum(v, 0, v.size() / 2); }); std::future<int> lower_half_future = std::async(std::launch::async, sum, cref(v), 0, v.size() / 2); // upper_half 는 501 부터 1000 까지 더함 int upper_half = sum(v, v.size() / 2, v.size()); return lower_half_future.get() + upper_half; } int main() { std::vector<int> v; v.reserve(1000); for (int i = 0; i < 1000; ++i) { v.push_back(i + 1); } std::cout << "1 부터 1000 까지의 합 : " << parallel_sum(v) << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
1 부터 1000 까지의 합 : 500500
와 같이 잘 나옵니다.
std::future<int> lower_half_future = std::async(std::launch::async, sum, cref(v), 0, v.size() / 2);
async 함수는 인자로 받은 함수를 비동기적으로 실행한 후에, 해당 결과값을 보관할 future 를 리턴합니다. 첫 번째 인자로는 어떠한 형태로 실행할지를 전달하는데 두 가지 값이 가능합니다.
std::launch::async: 바로 쓰레드를 생성해서 인자로 전달된 함수를 실행한다.std::launch::deferred:future의 get 함수가 호출되었을 때 실행한다. (새로운 쓰레드를 생성하지 않음)
즉 launch::async 옵션을 주면 바로 그 자리에서 쓰레드를 생성해서 실행하게 되고, launch::deferred 옵션을 주면, future 의 get 을 하였을 때 비로소 (동기적으로) 실행하게 됩니다. 다시 말해, 해당 함수를 굳이 바로 당장 비동기적으로 실행할 필요가 없다면 deferred 옵션을 주면 됩니다.
async 함수는 실행하는 함수의 결과값을 포함하는 future 를 리턴합니다. 그 결과값은
return lower_half_future.get() + upper_half;
async 함수가 리턴한 future 에 get 을 통해 얻어낼 수 있습니다.
위 parallel 함수는 1 부터 1000 까지의 덧셈을 총 2 개의 쓰레드에서 실행한다고 보면 됩니다. 1 부터 500 까지의 합은, async 를 통해 생성된 새로운 쓰레드에서 더하게 되고, 나머지 501 부터 1000 까지의 합은 원래의 쓰레드에서 처리하게 되죠.
물론 위 1 부터 1000 까지의 합은 금방 처리되기 때문에 큰 차이는 나지 않지만, CPU 를 많이 사용하는 작업을 두 개의 쓰레드에서 나눠 처리한다면 (CPU 가 멀티 코어임을 가정할 때) 2 배 빠르게 작업을 수행할 수 있습니다.
예를 들어서 아래 예제를 살펴봅시다.
#include <future> #include <iostream> #include <thread> int do_work(int x) { // x 를 가지고 무슨 일을 한다. std::this_thread::sleep_for(std::chrono::seconds(3)); return x; } void do_work_parallel() { auto f1 = std::async([]() { do_work(3); }); auto f2 = std::async([]() { do_work(3); }); do_work(3); f1.get(); f2.get(); } void do_work_sequential() { do_work(3); do_work(3); do_work(3); } int main() { do_work_parallel(); }
성공적으로 컴파일 하였다면

위와 같이 실행하는데 총 3초가 걸리는 것을 알 수 있습니다. 이는 총 실행하는데 3 초가 걸리는 do_work 함수를 아래와 같이 비동기적으로 호출하였기 때문입니다.
auto f1 = std::async([]() { do_work(3); }); auto f2 = std::async([]() { do_work(3); }); do_work(3);
즉 3 개의 do_work 함수를 동시에 각기 다른 쓰레드에서 실행한 덕분에 3 초 만에 끝났습니다. 반면에 동기적으로 하나씩 실행하였다면
#include <future> #include <iostream> #include <thread> int do_work(int x) { // x 를 가지고 무슨 일을 한다. std::this_thread::sleep_for(std::chrono::seconds(3)); return x; } void do_work_parallel() { auto f1 = std::async([]() { do_work(3); }); auto f2 = std::async([]() { do_work(3); }); do_work(3); f1.get(); f2.get(); } void do_work_sequential() { do_work(3); do_work(3); do_work(3); } int main() { do_work_sequential(); }
성공적으로 컴파일 하였다면

위와 같이 총 3 + 3 + 3 = 9 초가 걸림을 알 수 있습니다.
이처럼 C++ 에서 제공하는 promise, future, packaged_task, async 를 잘 활용하면 귀찮게 mutex 나 condition_variable 을 사용하지 않고도 매우 편리하게 비동기적 작업을 수행할 수 있습니다. 그렇다면 이번 강좌는 여기서 마치도록 하겠습니다.
다음 강좌에서는 여태까지 배운 것들을 총 동원해서 ThreadPool 을 만들어보겠습니다.
생각 해보기
문제 1
async 를 사용해서 기존의 find 를 더 빠르게 수행하는 함수를 만들어보세요.
문제 2
쓰레드풀(ThreadPool) 이란 말 그대로 쓰레드들의 직업 소개소라고 보면 됩니다. 여기에 일거리 (함수) 를 던져주면, 직업 소개소에 있던 쓰레드 하나가 그 일감을 받아서 수행하게 됩니다. 그 일을 다 수행한 쓰레드는 다시 직업 소개소로 돌아오죠.
쓰레드풀의 사용자는 원하는 만큼의 쓰레드들을 생성해놓고, 무언가 수행하고 싶은 일이 있다면 그냥 쓰레드풀에 추가하면 됩니다.
그렇다면 한 번 ThreadPool 클래스를 설계하고 만들어보세요. 다음 강좌에서 같이 만들겠지만, 먼저 혼자 자기 힘으로 만들어보는 것이 중요합니다.
뭘 배웠지?
한 번 발생하는 이벤트에 대해서 promise - future 패턴을 이용하면 간단하게 처리할 수 있습니다.
shared_future 를 사용해서 여러 개의 쓰레드를 한꺼번에 관리할 수 있습니다.
packaged_task 를 통해서 원하는 함수의 promise 와 future 패턴을 손쉽게 생성할 수 있습니다.
async 를 사용하면 원하는 함수를 비동기적으로 실행할 수 있습니다.

댓글을 불러오는 중입니다..